溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
排序算法比較與分析
一、常用排序算法簡述
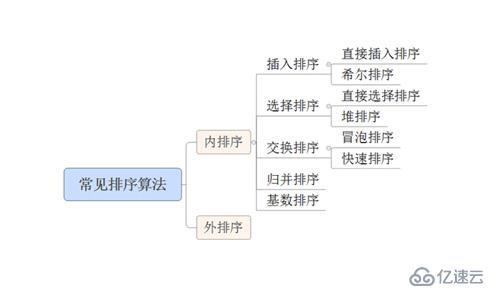
下面主要從排序算法的基本概念、原理出發,分別從算法的時間復雜度、空間復雜度、算法的穩定性和速度等方面進行分析比較。依據待排序的問題大小(記錄數量 n)的不同,排序過程中需要的存儲器空間也不同,由此將排序算法分為兩大類:【內排序】、【外排序】。
內排序:指排序時數據元素全部存放在計算機的隨機存儲器RAM中。
外排序:待排序記錄的數量很大,以致內存一次不能容納全部記錄,在排序過程中還需要對外存進行訪問的排序過程。
先了解一下常見排序算法的分類關系(見圖1-1)
圖1-1 常見排序算法
二、內排序相關算法
2.1 插入排序
核心思想:將一個待排序的數據元素插入到前面已經排好序的數列中的適當位置,使數據元素依然有序,直到待排序數據元素全部插入完為止。
2.1.1 直接插入排序
核心思想:將欲插入的第i個數據元素的關鍵碼與前面已經排序好的i-1、i-2 、i-3、 … 數據元素的值進行順序比較,通過這種線性搜索的方法找到第i個數據元素的插入位置 ,并且原來位置 的數據元素順序后移,直到全部排好順序。
直接插入排序中,關鍵詞相同的數據元素將保持原有位置不變,所以該算法是穩定的,時間復雜度的最壞值為平方階O(n2),空間復雜度為常數階O(l)。
2.1.2 希爾排序
核心思想:是把記錄按下標的一定增量分組,對每組使用直接插入排序算法排序;隨著增量逐漸減少,每組包含的關鍵詞越來越多,當增量減至1時,整個文件恰被分成一組,算法便終止。
希爾排序時間復雜度會比O(n2)好一些,然而,多次插入排序中,第一次插入排序是穩定的,但在不同的插入排序過程中,相同的元素可能在各自的插入排序中移動,所以希爾排序是不穩定的。
2.2 選擇排序
核心思想:每一趟掃描時,從待排序的數據元素中選出關鍵碼最小或最大的一個元素,順序放在已經排好順序序列的最后,直到全部待排序的數據元素排完為止。
2.2.1 直接選擇排序
核心思想:給每個位置選擇關鍵碼最小的數據元素,即:選擇最小的元素與第一個位置的元素交換,然后在剩下的元素中再選擇最小的與第二個位置的元素交換,直到倒數第二個元素和最后一個元素比較為止。
根據其基本思想,每當掃描一趟時,如果當前元素比一個元素小,而且這個小元素又出現在一個和當前元素相等的元素后面,則它們的位置發生了交換,所以直接選擇排序時不穩定的,其時間復雜度為平方階O(n2),空間復雜度為O(l)。
2.2.2 堆排序
堆排序時對直接選擇排序的一種有效改進。
核心思想:將所有的數據建成一個堆,最大的數據在堆頂,然后將堆頂的數據元素和序列的最后一個元素交換;接著重建堆、交換數據,依次下去,從而實現對所有的數據元素的排序。完成堆排序需要執行兩個動作:建堆和堆的調整,如此反復進行。
堆排序有可能會使得兩個相同值的元素位置發生互換,所以是不穩定的,其平均時間復雜度為0(nlog2n),空間復雜度為O(l)。
2.3交換排序
核心思想:顧名思義,就是一組待排序的數據元素中,按照位置的先后順序相互比較各自的關鍵碼,如果是逆序,則交換這兩個數據元素,直到該序列數據元素有序為止。
2.3.1 冒泡排序
核心思想:對于待排序的一組數據元素,把每個數據元素看作有重量的氣泡,按照輕氣泡不能在重氣泡之下的原則,將未排好順序的全部元素自上而下的對相鄰兩個元素依次進行比較和調整,讓較重的元素往下沉,較輕的往上冒。
根據基本思想,只有在兩個元素的順序與排序要求相反時才將調換它們的位置,否則保持不變,所以冒泡排序時穩定的。時間復雜度為平方階O(n2),空間復雜度為O(l)。
2.3.2 快速排序
快速排序是對冒泡排序本質上的改進。
核心思想:是一個就地排序,分而治之,大規模遞歸的算法。即:通過一趟掃描后確保基準點的這個數據元素的左邊元素都比它小、右邊元素都比它大,接著又以遞歸方法處理左右兩邊的元素,直到基準點的左右只有一個元素為止。
快速排序時一個不穩定的算法,其最壞值的時間復雜度為平方階O(n2),空間復雜度為O(log2n)。
2.4歸并排序
核心思想:把數據序列遞歸地分成短序列,即把1分成2、2分成4、依次分解,當分解到只有1個一組的時候排序這些分組,然后依次合并回原來的序列,不斷合并直到原序列全部排好順序。
合并過程中可以確保兩個相等的當前元素中,把處在前面的元素保存在結果序列的前面,因此歸并排序是穩定的,其時間復雜度為O(nlog2n),空間復雜度為O(n)。
2.5 基數排序
核心思想:首先是低位排序,然后收集;其次是高位排序,然后再收集;依次類推,直到最高位。
三、排序算法實測
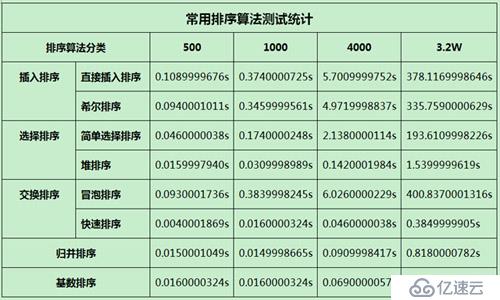
圖3-1 常用排序算法測試統計
四、排序算法對比與分析
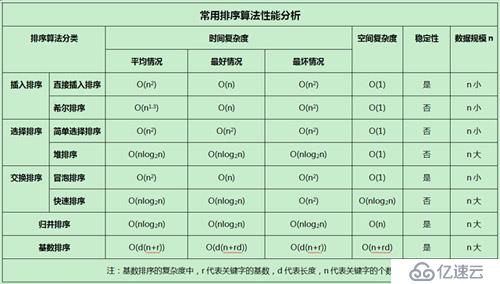
表4-1各個排序算法比較
[直接插入排序]是對冒泡排序的改進,比冒泡排序快,但是只適用于數據量較小(1000 ) 的排序
[希爾排序]比較簡單,適用于小數據量(5000以下)的排序,比直接插入排序快、冒泡排序快,因此,希爾排序適用于小數據量的、排序速度要求不高的排序。
[直接選擇排序]和冒泡排序算法一樣,適用于n值較小的場合,而且是排序算法發展的初級階段,在實際應用中采用的幾率較小。
[堆排序]比較適用于數據量達到百萬及其以上的排序,在這種情況下,使用遞歸設計的快速排序和歸并排序可能會發生堆棧溢出的現象。
[冒泡排序]是最慢的排序算法,是排序算法發展的初級階段,實際應用中采用該算法的幾率比較小。
[快速排序]是遞歸的、速度最快的排序算法,但是在內存有限的情況下不是一個好的選擇;而且,對于基本有序的數據序列排序,快速排序反而變得比較慢。
[歸并排序]比堆排序要快,但是需要的存儲空間增加一倍。
[基數排序]適用于規模n值很大的場合,但是只適用于整數的排序,如果對浮點數進行基數排序,則必須明確浮點數的存儲格式,然后通過某種方式將其映射到整數上,最后再映射回去,過程復雜。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





