溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Flink中的Time與Window有什么作用”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Flink中的Time與Window有什么作用”吧!
Flink 是流式的、實時的 計算引擎
上面一句話就有兩個概念,一個是流式,一個是實時。
流式:就是數據源源不斷的流進來,也就是數據沒有邊界,但是我們計算的時候必須在一個有邊界的范圍內進行,所以這里面就有一個問題,邊界怎么確定?無非就兩種方式,根據時間段或者數據量進行確定,根據時間段就是每隔多長時間就劃分一個邊界,根據數據量就是每來多少條數據劃分一個邊界,Flink 中就是這么劃分邊界的,本文會詳細講解。
實時:就是數據發送過來之后立馬就進行相關的計算,然后將結果輸出。這里的計算有兩種:
一種是只有邊界內的數據進行計算,這種好理解,比如統計每個用戶最近五分鐘內瀏覽的新聞數量,就可以取最近五分鐘內的所有數據,然后根據每個用戶分組,統計新聞的總數。
另一種是邊界內數據與外部數據進行關聯計算,比如:統計最近五分鐘內瀏覽新聞的用戶都是來自哪些地區,這種就需要將五分鐘內瀏覽新聞的用戶信息與 hive 中的地區維表進行關聯,然后在進行相關計算。
在Flink中,如果以時間段劃分邊界的話,那么時間就是一個極其重要的字段。
Flink中的時間有三種類型,如下圖所示:
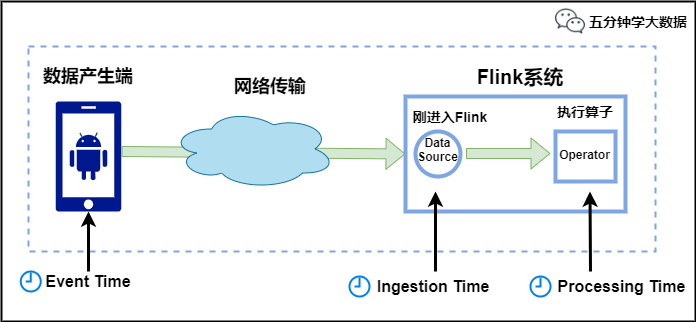
Event Time:是事件創建的時間。它通常由事件中的時間戳描述,例如采集的日志數據中,每一條日志都會記錄自己的生成時間,Flink通過時間戳分配器訪問事件時間戳。
Ingestion Time:是數據進入Flink的時間。
Processing Time:是每一個執行基于時間操作的算子的本地系統時間,與機器相關,默認的時間屬性就是Processing Time。
例如,一條日志進入Flink的時間為2021-01-22 10:00:00.123,到達Window的系統時間為2021-01-22 10:00:01.234,日志的內容如下:
2021-01-06 18:37:15.624 INFO Fail over to rm2
對于業務來說,要統計1min內的故障日志個數,哪個時間是最有意義的?—— eventTime,因為我們要根據日志的生成時間進行統計。
Window,即窗口,我們前面一直提到的邊界就是這里的Window(窗口)。
官方解釋:流式計算是一種被設計用于處理無限數據集的數據處理引擎,而無限數據集是指一種不斷增長的本質上無限的數據集,而window是一種切割無限數據為有限塊進行處理的手段。
所以Window是無限數據流處理的核心,Window將一個無限的stream拆分成有限大小的”buckets”桶,我們可以在這些桶上做計算操作。
本文剛開始提到,劃分窗口就兩種方式:
根據時間進行截取(time-driven-window),比如每1分鐘統計一次或每10分鐘統計一次。
根據數據進行截取(data-driven-window),比如每5個數據統計一次或每50個數據統計一次。
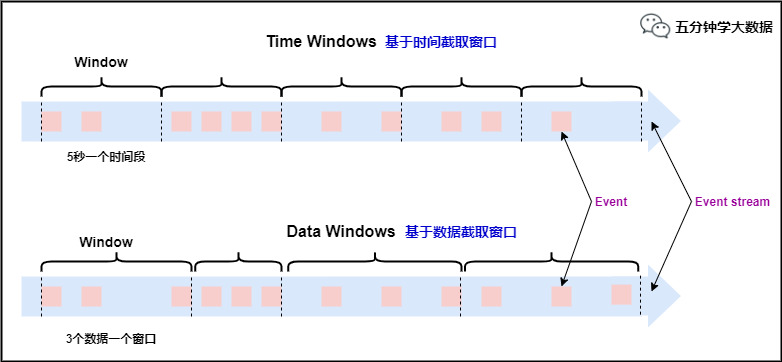
對于TimeWindow(根據時間劃分窗口), 可以根據窗口實現原理的不同分成三類:滾動窗口(Tumbling Window)、滑動窗口(Sliding Window)和會話窗口(Session Window)。
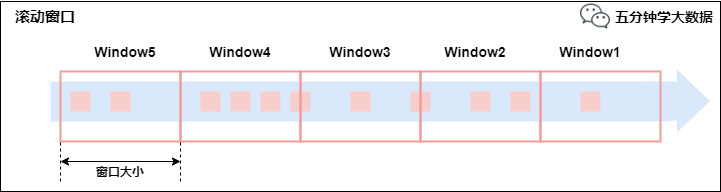
滾動窗口(Tumbling Windows)
將數據依據固定的窗口長度對數據進行切片。
特點:時間對齊,窗口長度固定,沒有重疊。
滾動窗口分配器將每個元素分配到一個指定窗口大小的窗口中,滾動窗口有一個固定的大小,并且不會出現重疊。
例如:如果你指定了一個5分鐘大小的滾動窗口,窗口的創建如下圖所示:
適用場景:適合做BI統計等(做每個時間段的聚合計算)。
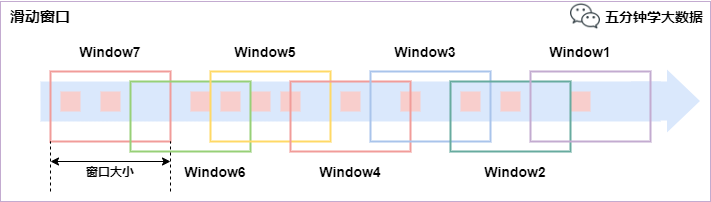
滑動窗口(Sliding Windows)
滑動窗口是固定窗口的更廣義的一種形式,滑動窗口由固定的窗口長度和滑動間隔組成。
特點:時間對齊,窗口長度固定,有重疊。
滑動窗口分配器將元素分配到固定長度的窗口中,與滾動窗口類似,窗口的大小由窗口大小參數來配置,另一個窗口滑動參數控制滑動窗口開始的頻率。因此,滑動窗口如果滑動參數小于窗口大小的話,窗口是可以重疊的,在這種情況下元素會被分配到多個窗口中。
例如,你有10分鐘的窗口和5分鐘的滑動,那么每個窗口中5分鐘的窗口里包含著上個10分鐘產生的數據,如下圖所示:
適用場景:對最近一個時間段內的統計(求某接口最近5min的失敗率來決定是否要報警)。
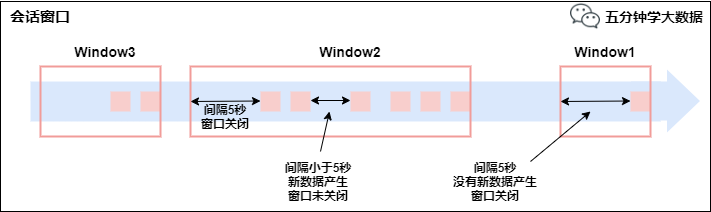
會話窗口(Session Windows)
由一系列事件組合一個指定時間長度的timeout間隙組成,類似于web應用的session,也就是一段時間沒有接收到新數據就會生成新的窗口。
特點:時間無對齊。
session窗口分配器通過session活動來對元素進行分組,session窗口跟滾動窗口和滑動窗口相比,不會有重疊和固定的開始時間和結束時間的情況,相反,當它在一個固定的時間周期內不再收到元素,即非活動間隔產生,那個這個窗口就會關閉。一個session窗口通過一個session間隔來配置,這個session間隔定義了非活躍周期的長度,當這個非活躍周期產生,那么當前的session將關閉并且后續的元素將被分配到新的session窗口中去。
TimeWindow是將指定時間范圍內的所有數據組成一個window,一次對一個window里面的所有數據進行計算(就是本文開頭說的對一個邊界內的數據進行計算)。
我們以 紅綠燈路口通過的汽車數量 為例子:
紅綠燈路口會有汽車通過,一共會有多少汽車通過,無法計算。因為車流源源不斷,計算沒有邊界。
所以我們統計每15秒鐘通過紅路燈的汽車數量,如第一個15秒為2輛,第二個15秒為3輛,第三個15秒為1輛 …
tumbling-time-window (無重疊數據)
我們使用 Linux 中的 nc 命令模擬數據的發送方
11.開啟發送端口,端口號為9999
2nc -lk 9999
3
42.發送內容(key 代表不同的路口,value 代表每次通過的車輛)
5一次發送一行,發送的時間間隔代表汽車經過的時間間隔
69,3
79,2
89,7
94,9
102,6
111,5
122,3
135,7
145,4
Flink 進行采集數據并計算:
1object Window {
2 def main(args: Array[String]): Unit = {
3 //TODO time-window
4 //1.創建運行環境
5 val env = StreamExecutionEnvironment.getExecutionEnvironment
6
7 //2.定義數據流來源
8 val text = env.socketTextStream("localhost", 9999)
9
10 //3.轉換數據格式,text->CarWc
11 case class CarWc(sensorId: Int, carCnt: Int)
12 val ds1: DataStream[CarWc] = text.map {
13 line => {
14 val tokens = line.split(",")
15 CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
16 }
17 }
18
19 //4.執行統計操作,每個sensorId一個tumbling窗口,窗口的大小為5秒
20 //也就是說,每5秒鐘統計一次,在這過去的5秒鐘內,各個路口通過紅綠燈汽車的數量。
21 val ds2: DataStream[CarWc] = ds1
22 .keyBy("sensorId")
23 .timeWindow(Time.seconds(5))
24 .sum("carCnt")
25
26 //5.顯示統計結果
27 ds2.print()
28
29 //6.觸發流計算
30 env.execute(this.getClass.getName)
31
32 }
33}
我們發送的數據并沒有指定時間字段,所以Flink使用的是默認的 Processing Time,也就是Flink系統處理數據時的時間。
sliding-time-window (有重疊數據)
1//1.創建運行環境
2val env = StreamExecutionEnvironment.getExecutionEnvironment
3
4//2.定義數據流來源
5val text = env.socketTextStream("localhost", 9999)
6
7//3.轉換數據格式,text->CarWc
8case class CarWc(sensorId: Int, carCnt: Int)
9
10val ds1: DataStream[CarWc] = text.map {
11 line => {
12 val tokens = line.split(",")
13 CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
14 }
15}
16//4.執行統計操作,每個sensorId一個sliding窗口,窗口時間10秒,滑動時間5秒
17//也就是說,每5秒鐘統計一次,在這過去的10秒鐘內,各個路口通過紅綠燈汽車的數量。
18val ds2: DataStream[CarWc] = ds1
19 .keyBy("sensorId")
20 .timeWindow(Time.seconds(10), Time.seconds(5))
21 .sum("carCnt")
22
23//5.顯示統計結果
24ds2.print()
25
26//6.觸發流計算
27env.execute(this.getClass.getName)
CountWindow根據窗口中相同key元素的數量來觸發執行,執行時只計算元素數量達到窗口大小的key對應的結果。
注意:CountWindow的window_size指的是相同Key的元素的個數,不是輸入的所有元素的總數。
tumbling-count-window (無重疊數據)
1//1.創建運行環境
2val env = StreamExecutionEnvironment.getExecutionEnvironment
3
4//2.定義數據流來源
5val text = env.socketTextStream("localhost", 9999)
6
7//3.轉換數據格式,text->CarWc
8case class CarWc(sensorId: Int, carCnt: Int)
9
10val ds1: DataStream[CarWc] = text.map {
11 (f) => {
12 val tokens = f.split(",")
13 CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
14 }
15}
16//4.執行統計操作,每個sensorId一個tumbling窗口,窗口的大小為5
17//按照key進行收集,對應的key出現的次數達到5次作為一個結果
18val ds2: DataStream[CarWc] = ds1
19 .keyBy("sensorId")
20 .countWindow(5)
21 .sum("carCnt")
22
23//5.顯示統計結果
24ds2.print()
25
26//6.觸發流計算
27env.execute(this.getClass.getName)
sliding-count-window (有重疊數據)
同樣也是窗口長度和滑動窗口的操作:窗口長度是5,滑動長度是3
1//1.創建運行環境
2val env = StreamExecutionEnvironment.getExecutionEnvironment
3
4//2.定義數據流來源
5val text = env.socketTextStream("localhost", 9999)
6
7//3.轉換數據格式,text->CarWc
8case class CarWc(sensorId: Int, carCnt: Int)
9
10val ds1: DataStream[CarWc] = text.map {
11 (f) => {
12 val tokens = f.split(",")
13 CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
14 }
15}
16//4.執行統計操作,每個sensorId一個sliding窗口,窗口大小3條數據,窗口滑動為3條數據
17//也就是說,每個路口分別統計,收到關于它的3條消息時統計在最近5條消息中,各自路口通過的汽車數量
18val ds2: DataStream[CarWc] = ds1
19 .keyBy("sensorId")
20 .countWindow(5, 3)
21 .sum("carCnt")
22
23//5.顯示統計結果
24ds2.print()
25
26//6.觸發流計算
27env.execute(this.getClass.getName)
Window 總結
flink支持兩種劃分窗口的方式(time和count)
如果根據時間劃分窗口,那么它就是一個time-window
如果根據數據劃分窗口,那么它就是一個count-window
flink支持窗口的兩個重要屬性(size和interval)
如果size=interval,那么就會形成tumbling-window(無重疊數據)
如果size>interval,那么就會形成sliding-window(有重疊數據)
如果size<interval,那么這種窗口將會丟失數據。比如每5秒鐘,統計過去3秒的通過路口汽車的數據,將會漏掉2秒鐘的數據。
通過組合可以得出四種基本窗口
time-tumbling-window 無重疊數據的時間窗口,設置方式舉例:timeWindow(Time.seconds(5))
time-sliding-window 有重疊數據的時間窗口,設置方式舉例:timeWindow(Time.seconds(5), Time.seconds(3))
count-tumbling-window無重疊數據的數量窗口,設置方式舉例:countWindow(5)
count-sliding-window 有重疊數據的數量窗口,設置方式舉例:countWindow(5,3)
WindowedStream → DataStream:給window賦一個reduce功能的函數,并返回一個聚合的結果。
1import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
2import org.apache.flink.api.scala._
3import org.apache.flink.streaming.api.windowing.time.Time
4
5object StreamWindowReduce {
6 def main(args: Array[String]): Unit = {
7 // 獲取執行環境
8 val env = StreamExecutionEnvironment.getExecutionEnvironment
9
10 // 創建SocketSource
11 val stream = env.socketTextStream("node01", 9999)
12
13 // 對stream進行處理并按key聚合
14 val streamKeyBy = stream.map(item => (item, 1)).keyBy(0)
15
16 // 引入時間窗口
17 val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
18
19 // 執行聚合操作
20 val streamReduce = streamWindow.reduce(
21 (item1, item2) => (item1._1, item1._2 + item2._2)
22 )
23
24 // 將聚合數據寫入文件
25 streamReduce.print()
26
27 // 執行程序
28 env.execute("TumblingWindow")
29 }
30}
apply方法可以進行一些自定義處理,通過匿名內部類的方法來實現。當有一些復雜計算時使用。
用法
實現一個 WindowFunction 類
指定該類的泛型為 [輸入數據類型, 輸出數據類型, keyBy中使用分組字段的類型, 窗口類型]
示例:使用apply方法來實現單詞統計
步驟:
獲取流處理運行環境
構建socket流數據源,并指定IP地址和端口號
對接收到的數據轉換成單詞元組
使用 keyBy 進行分流(分組)
使用 timeWinodw 指定窗口的長度(每3秒計算一次)
實現一個WindowFunction匿名內部類
apply方法中實現聚合計算
使用Collector.collect收集數據
核心代碼如下:
1 //1. 獲取流處理運行環境
2 val env = StreamExecutionEnvironment.getExecutionEnvironment
3
4 //2. 構建socket流數據源,并指定IP地址和端口號
5 val textDataStream = env.socketTextStream("node01", 9999).flatMap(_.split(" "))
6
7 //3. 對接收到的數據轉換成單詞元組
8 val wordDataStream = textDataStream.map(_->1)
9
10 //4. 使用 keyBy 進行分流(分組)
11 val groupedDataStream: KeyedStream[(String, Int), String] = wordDataStream.keyBy(_._1)
12
13 //5. 使用 timeWinodw 指定窗口的長度(每3秒計算一次)
14 val windowDataStream: WindowedStream[(String, Int), String, TimeWindow] = groupedDataStream.timeWindow(Time.seconds(3))
15
16 //6. 實現一個WindowFunction匿名內部類
17 val reduceDatStream: DataStream[(String, Int)] = windowDataStream.apply(new RichWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
18 //在apply方法中實現數據的聚合
19 override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
20 println("hello world")
21 val tuple = input.reduce((t1, t2) => {
22 (t1._1, t1._2 + t2._2)
23 })
24 //將要返回的數據收集起來,發送回去
25 out.collect(tuple)
26 }
27 })
28 reduceDatStream.print()
29 env.execute()
WindowedStream → DataStream:給窗口賦一個fold功能的函數,并返回一個fold后的結果。
1import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
2import org.apache.flink.api.scala._
3import org.apache.flink.streaming.api.windowing.time.Time
4
5object StreamWindowFold {
6 def main(args: Array[String]): Unit = {
7 // 獲取執行環境
8 val env = StreamExecutionEnvironment.getExecutionEnvironment
9
10 // 創建SocketSource
11 val stream = env.socketTextStream("node01", 9999,'\n',3)
12
13 // 對stream進行處理并按key聚合
14 val streamKeyBy = stream.map(item => (item, 1)).keyBy(0)
15
16 // 引入滾動窗口
17 val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
18
19 // 執行fold操作
20 val streamFold = streamWindow.fold(100){
21 (begin, item) =>
22 begin + item._2
23 }
24
25 // 將聚合數據寫入文件
26 streamFold.print()
27
28 // 執行程序
29 env.execute("TumblingWindow")
30 }
31}
WindowedStream → DataStream:對一個window內的所有元素做聚合操作。min和 minBy的區別是min返回的是最小值,而minBy返回的是包含最小值字段的元素(同樣的原理適用于 max 和 maxBy)。
1import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
2import org.apache.flink.streaming.api.windowing.time.Time
3import org.apache.flink.api.scala._
4
5object StreamWindowAggregation {
6 def main(args: Array[String]): Unit = {
7 // 獲取執行環境
8 val env = StreamExecutionEnvironment.getExecutionEnvironment
9
10 // 創建SocketSource
11 val stream = env.socketTextStream("node01", 9999)
12
13 // 對stream進行處理并按key聚合
14 val streamKeyBy = stream.map(item => (item.split(" ")(0), item.split(" ")(1))).keyBy(0)
15
16 // 引入滾動窗口
17 val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
18
19 // 執行聚合操作
20 val streamMax = streamWindow.max(1)
21
22 // 將聚合數據寫入文件
23 streamMax.print()
24
25 // 執行程序
26 env.execute("TumblingWindow")
27 }
28}
與現實世界中的時間是不一致的,在flink中被劃分為事件時間,提取時間,處理時間三種。
如果以EventTime為基準來定義時間窗口那將形成EventTimeWindow,要求消息本身就應該攜帶EventTime
如果以IngesingtTime為基準來定義時間窗口那將形成IngestingTimeWindow,以source的systemTime為準。
如果以ProcessingTime基準來定義時間窗口那將形成ProcessingTimeWindow,以operator的systemTime為準。
在Flink的流式處理中,絕大部分的業務都會使用eventTime,一般只在eventTime無法使用時,才會被迫使用ProcessingTime或者IngestionTime。
如果要使用EventTime,那么需要引入EventTime的時間屬性,引入方式如下所示:
1val env = StreamExecutionEnvironment.getExecutionEnvironment
2
3// 從調用時刻開始給env創建的每一個stream追加時間特征
4env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
我們知道,流處理從事件產生,到流經 source,再到 operator,中間是有一個過程和時間的,雖然大部分情況下,流到 operator 的數據都是按照事件產生的時間順序來的,但是也不排除由于網絡、背壓等原因,導致亂序的產生,所謂亂序,就是指 Flink 接收到的事件的先后順序不是嚴格按照事件的 Event Time 順序排列的,所以 Flink 最初設計的時候,就考慮到了網絡延遲,網絡亂序等問題,所以提出了一個抽象概念:水印(WaterMark);
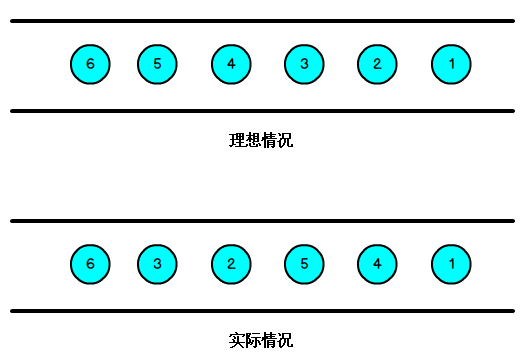
如上圖所示,就出現一個問題,一旦出現亂序,如果只根據 EventTime 決定 Window 的運行,我們不能明確數據是否全部到位,但又不能無限期的等下去,此時必須要有個機制來保證一個特定的時間后,必須觸發 Window 去進行計算了,這個特別的機制,就是 Watermark。
Watermark 是用于處理亂序事件的,而正確的處理亂序事件,通常用 Watermark 機制結合 Window 來實現。
數據流中的 Watermark 用于表示 timestamp 小于 Watermark 的數據,都已經到達了,因此,Window 的執行也是由 Watermark 觸發的。
Watermark 可以理解成一個延遲觸發機制,我們可以設置 Watermark 的延時時長 t,每次系統會校驗已經到達的數據中最大的 maxEventTime,然后認定 EventTime 小于 maxEventTime - t 的所有數據都已經到達,如果有窗口的停止時間等于 maxEventTime – t,那么這個窗口被觸發執行。
有序流的Watermarker如下圖所示:(Watermark設置為0)

亂序流的Watermarker如下圖所示:(Watermark設置為2)

當 Flink 接收到每一條數據時,都會產生一條 Watermark,這條 Watermark 就等于當前所有到達數據中的 maxEventTime - 延遲時長,也就是說,Watermark 是由數據攜帶的,一旦數據攜帶的 Watermark 比當前未觸發的窗口的停止時間要晚,那么就會觸發相應窗口的執行。由于 Watermark 是由數據攜帶的,因此,如果運行過程中無法獲取新的數據,那么沒有被觸發的窗口將永遠都不被觸發。
上圖中,我們設置的允許最大延遲到達時間為2s,所以時間戳為7s的事件對應的Watermark是5s,時間戳為12s的事件的Watermark是10s,如果我們的窗口1是1s~5s,窗口2是6s~10s,那么時間戳為7s的事件到達時的Watermarker恰好觸發窗口1,時間戳為12s的事件到達時的Watermark恰好觸發窗口2。
waterMark和Window機制解決了流式數據的亂序問題,對于因為延遲而順序有誤的數據,可以根據eventTime進行業務處理,于延遲的數據Flink也有自己的解決辦法,主要的辦法是給定一個允許延遲的時間,在該時間范圍內仍可以接受處理延遲數據。
設置允許延遲的時間是通過 allowedLateness(lateness: Time) 設置
保存延遲數據則是通過 sideOutputLateData(outputTag: OutputTag[T]) 保存
獲取延遲數據是通過 DataStream.getSideOutput(tag: OutputTag[X]) 獲取
具體的用法如下:
1def allowedLateness(lateness: Time): WindowedStream[T, K, W] = {
2 javaStream.allowedLateness(lateness)
3 this
4} 該方法傳入一個Time值,設置允許數據遲到的時間,這個時間和 WaterMark 中的時間概念不同。再來回顧一下:
WaterMark=數據的事件時間-允許亂序時間值
隨著新數據的到來,waterMark的值會更新為最新數據事件時間-允許亂序時間值,但是如果這時候來了一條歷史數據,waterMark值則不會更新。總的來說,waterMark是為了能接收到盡可能多的亂序數據。
那這里的Time值,主要是為了等待遲到的數據,在一定時間范圍內,如果屬于該窗口的數據到來,仍會進行計算,后面會對計算方式仔細說明
注意:該方法只針對于基于event-time的窗口,如果是基于processing-time,并且指定了非零的time值則會拋出異常。
1def sideOutputLateData(outputTag: OutputTag[T]): WindowedStream[T, K, W] = {
2 javaStream.sideOutputLateData(outputTag)
3 this
4} 該方法是將遲來的數據保存至給定的outputTag參數,而OutputTag則是用來標記延遲數據的一個對象。
通過window等操作返回的DataStream調用該方法,傳入標記延遲數據的對象來獲取延遲的數據。
延遲數據是指:
在當前窗口【假設窗口范圍為10-15】已經計算之后,又來了一個屬于該窗口的數據【假設事件時間為13】,這時候仍會觸發 Window 操作,這種數據就稱為延遲數據。
那么問題來了,延遲時間怎么計算呢?
假設窗口范圍為10-15,延遲時間為2s,則只要 WaterMark<15+2,并且屬于該窗口,就能觸發 Window 操作。而如果來了一條數據使得 WaterMark>=15+2,10-15這個窗口就不能再觸發 Window 操作,即使新來的數據的 Event Time 屬于這個窗口時間內 。
Flink 1.12 支持了 Hive 最新的分區作為時態表的功能,可以通過 SQL 的方式直接關聯 Hive 分區表的最新分區,并且會自動監聽最新的 Hive 分區,當監控到新的分區后,會自動地做維表數據的全量替換。通過這種方式,用戶無需編寫 DataStream 程序即可完成 Kafka 流實時關聯最新的 Hive 分區實現數據打寬。
具體用法:
在 Sql Client 中注冊 HiveCatalog:
1vim conf/sql-client-defaults.yaml
2catalogs:
3 - name: hive_catalog
4 type: hive
5 hive-conf-dir: /disk0/soft/hive-conf/ #該目錄需要包hive-site.xml文件
創建 Kafka 表
1CREATE TABLE hive_catalog.flink_db.kfk_fact_bill_master_12 (
2 master Row<reportDate String, groupID int, shopID int, shopName String, action int, orderStatus int, orderKey String, actionTime bigint, areaName String, paidAmount double, foodAmount double, startTime String, person double, orderSubType int, checkoutTime String>,
3proctime as PROCTIME() -- PROCTIME用來和Hive時態表關聯
4) WITH (
5 'connector' = 'kafka',
6 'topic' = 'topic_name',
7 'format' = 'json',
8 'properties.bootstrap.servers' = 'host:9092',
9 'properties.group.id' = 'flinkTestGroup',
10 'scan.startup.mode' = 'timestamp',
11 'scan.startup.timestamp-millis' = '1607844694000'
12);
Flink 事實表與 Hive 最新分區數據關聯
dim_extend_shop_info 是 Hive 中已存在的表,所以我們用 table hint 動態地開啟維表參數。
1CREATE VIEW IF NOT EXISTS hive_catalog.flink_db.view_fact_bill_master as
2SELECT * FROM
3 (select t1.*, t2.group_id, t2.shop_id, t2.group_name, t2.shop_name, t2.brand_id,
4 ROW_NUMBER() OVER (PARTITION BY groupID, shopID, orderKey ORDER BY actionTime desc) rn
5 from hive_catalog.flink_db.kfk_fact_bill_master_12 t1
6 JOIN hive_catalog.flink_db.dim_extend_shop_info
7 /*+ OPTIONS('streaming-source.enable'='true',
8 'streaming-source.partition.include' = 'latest',
9 'streaming-source.monitor-interval' = '1 h',
10 'streaming-source.partition-order' = 'partition-name') */
11 FOR SYSTEM_TIME AS OF t1.proctime AS t2 --時態表
12 ON t1.groupID = t2.group_id and t1.shopID = t2.shop_id
13 where groupID in (202042)) t where t.rn = 1
參數解釋:
streaming-source.enable 開啟流式讀取 Hive 數據。
streaming-source.partition.include 有以下兩種值:
latest 屬性: 只讀取最新分區數據。
all: 讀取全量分區數據 ,默認值為 all,表示讀所有分區,latest 只能用在 temporal join 中,用于讀取最新分區作為維表,不能直接讀取最新分區數據。
streaming-source.monitor-interval 監聽新分區生成的時間、不宜過短 、最短是1 個小時,因為目前的實現是每個 task 都會查詢 metastore,高頻的查可能會對metastore 產生過大的壓力。需要注意的是,1.12.1 放開了這個限制,但仍建議按照實際業務不要配個太短的 interval。
streaming-source.partition-order 分區策略,主要有以下 3 種,其中最為推薦的是 partition-name:
partition-name 使用默認分區名稱順序加載最新分區
create-time 使用分區文件創建時間順序
partition-time 使用分區時間順序
感謝各位的閱讀,以上就是“Flink中的Time與Window有什么作用”的內容了,經過本文的學習后,相信大家對Flink中的Time與Window有什么作用這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





