溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關數據庫中怎么使用batch-import工具向neo4j中導入海量數據的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
1、batch-import原始項目地址:https://github.com/jexp/batch-import
這個工具是neo4j的作者之一Michael Hunger所編寫,是在neo4j自帶批量導入工具基礎之上做的進一步優化,但是它在導入.gz壓縮文件時,會出現關系無法導入的情況,所以如果要使用.gz壓縮包進行導入,請使用我修改過的版本:https://github.com/mo9527/batch-import
2、環境準備
jdk:7以上
內存:8G以上,導入數據多的話會非常消耗內存,我自己導入的是將近1.5億節點,3億關系,用的是32G內存
3、導入步驟
a)從github上clone下代碼,并使用maven進行打包,打完包后的jar文件,與項目本身的依賴jar一起放到lib文件夾下,batch.properties文件和執行導入的腳本放在lib同級目錄下,***的目錄結構如下圖:
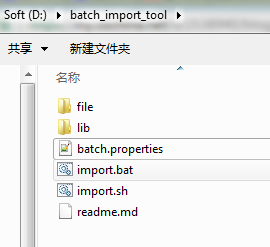
ps:file文件夾是我自己將要導入的csv文件和.gz壓縮包。
b)組裝csv文件
說起這一步,可能需要你們根據自己的實際業務需求,手動寫代碼導csv文件了,這里我只講一下csv文件格式一些要點:
1)、節點csv文件
節點csv文件的***列是固定的,列值為此節點的label名稱,第二列是index,它的列頭是id:string:indexName 這種格式,解釋一下,id是這一列的property名字,可以根據需要自己命名,string為字段的數據類型,indexName是neo4j數據庫中將要導入的索引名稱,我自己的文件格式如下:
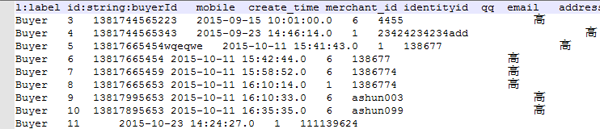
然后,后面的列就是節點的property了,沒什么特別的要求
2)、關系csv文件
先看下我的關系csv文件:
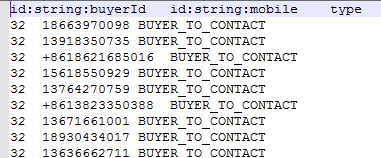
關系的csv文件前兩列要特別注意,***列是關系的起始節點,第二列是關系的結束節點,第三列是關系類型,后面的列是關系的property,可以隨意了。他github上的說明沒有說出一些注意點,這里要特別標明:
***列的起始節點的列頭,也就是id:string:buyerId這個東西,這個玩意一定要和節點csv文件(上圖)中定義的一模一樣,第二列也是如此,要和結束節點的csv文件里的一樣,不然他會找不到對應的關系。
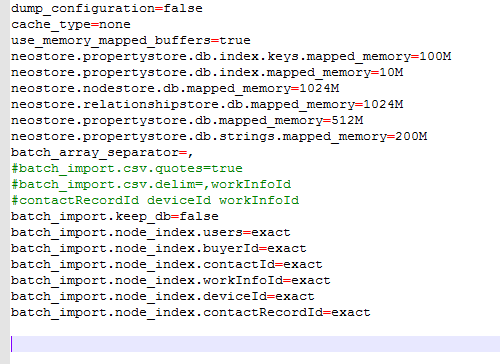
3)、修改batch.properties文件
主要修改兩個地方,
如果是在現有的neo4j數據庫中進行導入,請設置:
batch_import.keep_db=true
將節點csv文件中所有的索引名稱加入到文件中,例如上面這個節點csv文件中的索引名稱是buyerId,那就在文件中加入batch_import.node_index.buyerId=exact
以下是我本人的配置文件:
4、導入
linux和win環境的導入都差不多,只不過執行的腳本不一樣,這里以win環境為例。
文件都準備好了,現在開始導入了。
打開cmd,cd到導入腳本的目錄,也就是import.bat所在目錄,執行命令:
import.bat test.db node.csv rel.csv
解釋一下命令的幾個參數:***個參數是數據庫的目錄,可以絕對路徑指定到任意位置,第二個參數是節點csv文件,多個csv文件用逗號分隔,如果是壓縮包,一定要注意,這里有個坑,不能把所有類型的node都放到一個壓縮包中,一定要每個類型的node分開壓縮,不然它只會導入***個類型的node節點,同理,關系的壓縮包也要分開壓縮,然后導入時用逗號分隔.gz文件。
好了,如果你的csv文件沒有問題,內存足夠用的話,現在就開始等待吧。
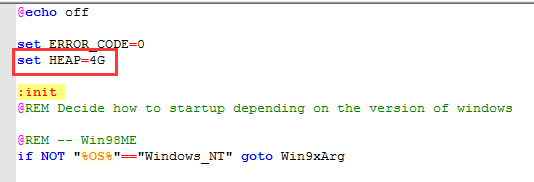
如果想修改導入工具的Heap大小,可以修改腳本文件中的 set HEAP=4G
溫馨提示:如果節點文件中有中文的話,導入會非常慢的,除非你內存有128G,我有一個節點文件,里面只有一列是中文,而且中文最長不超過4個漢字,2000多萬記錄導了2個小時,注意我是32G內存,其他4000多萬的節點,沒有漢字的,基本上不超過2分鐘。
感謝各位的閱讀!關于“數據庫中怎么使用batch-import工具向neo4j中導入海量數據”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





