溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何理解MySQL高可用數據庫內核深度優化的四重定制,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。

近期我們的數據庫團隊對原生復制的多個方面進行了深度優化,提升了UDB高可用數據庫的功能和性能。今天借社群這個平臺,跟大家分享一二。
一、UDB高可用數據庫架構
UDB以虛擬IP、HAProxy、單節點UDB數據庫搭建雙節點高可用架構:
雙節點的UDB數據庫保證數據庫數據的全量冗余,同時保證數據庫的可用性;
HAProxy在同一時間只連接一個UDB節點,避免多點寫入帶來的數據沖突問題;
雙節點HAProxy保證Proxy的可用性;
虛擬IP在HAProxy發生宕機時通過IP漂移的方式對HAProxy進行切換,用戶不需要再次修改IP。
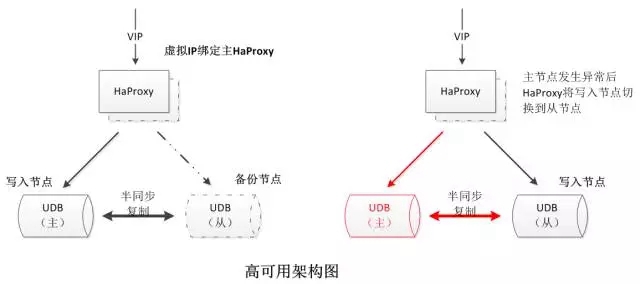
在上述架構中,從節點UDB的數據是否完整、是否與主庫保證數據一致性是整個高可用架構的關鍵,所以用于數據傳輸的半同步復制起著至關重要的作用。針對原生的半同步復制,我們作了內核層面的深度優化。
二、UDB數據庫深度優化
UDB是以開源數據庫MySQL Community Server 5.7.16為基線版本,圍繞高可用架構做內核深度優化。
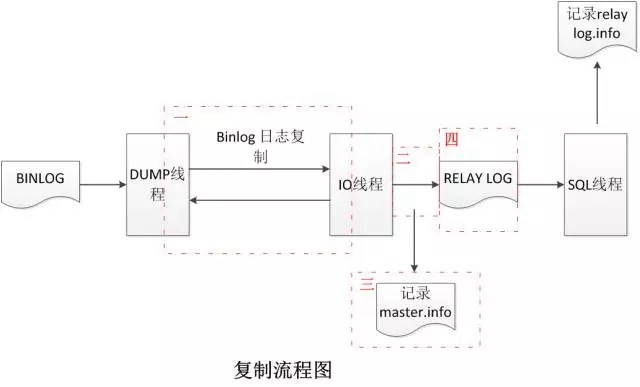
復制流程,如上圖所示,主要經過如下幾個步驟:
MySQL Server執行SQL成功后,記錄binlog;
Dump線程讀取binlog后,發送到從機IO線程;
IO線程將接收到的binlog記錄到relay log中,同時記錄接收進度到master.info中;
SQL讀取relay log中的日志內容進行復現,同時記錄復制日志的進度到relay-log.info中。
我們在原生復制的基礎上做了內核的深度優化,針對上述流程中的部分步驟,在功能和性能上做了改進,使得 UDB更加穩定。
1、Binlog日志復制優化
存在的問題
原生半同步復制存在退化問題,在網絡抖動導致超時或者從庫追趕主庫日志進度時,復制會由半同步復制退化為異步復制。
相比于可靠的半同步復制,異步復制過程中,從庫是沒有辦法感知接收到relay log與主庫的binlog是否一致。如果發生宕機,也就沒有辦法確認從庫數據是否與主庫一致,是否可以發生數據庫切換,這種不確定的情況是我們不希望看到的。
優化方案
建立雙通道復制,在原有半同步復制的基礎上增加一條UDB復制通道:
建立一條新的復制通道與原有的復制并行,兩條通道互相獨立;
新的復制通道不傳輸數據,只傳輸主庫的SQL執行進度 (binlog的文件名和位置);
新的復制通道使用半同步復制協議,但是不退化,超時后重連,只接收***的SQL執行進度 ;
新的復制通道不存在追補數據的問題,只要網絡正常的情況下,從庫永遠可以感知SQL的執行進度。
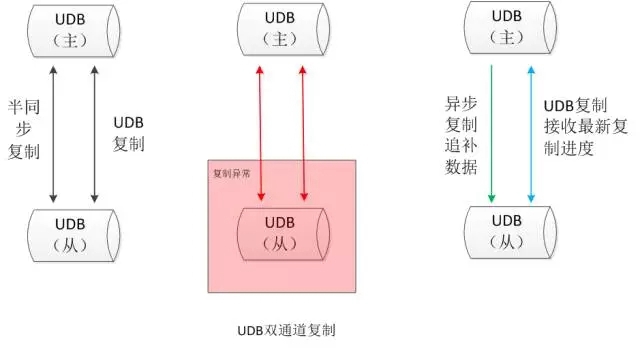
如上圖所示,當從庫發生宕機或者網絡發生故障后,主從復制停止。當從庫復制恢復正常后,原生復制通道通過異步復制的方式進行數據追補,UDB復制通道只接收***的binlog記錄位置,這樣可以***限度地減少主從之間異步復制的時間。即在網絡可連通的情況下,無論何時發生宕機,從庫均知道與主庫是否處于數據一致的狀態(或者落后了多少)。
2、Relay log文件記錄的優化
存在的問題
在MySQL中,binlog是以event為基本單位進行記錄,以MySQL 5.7 ROW格式(開啟GTID)的binlog為例,一個DML(insert)會以5個event的格式記錄到binlog中(其他操作均以一個或者多個event組成,不再一一羅列),分別為:
GTID_EVENT:記錄當前事務的GTID
QUERY_EVENT:事務開始
TABLE_MAP_EVENT:操作對應的表
WRITE_ROW_EVENT:插入記錄
XID_EVENT:提交事務
全部event組成一個完整的事務,完整的事務才會被SQL線程正確復現到從庫上。當前IO線程接收binlog時,是以event為單位進行接收,即接收到一個event,記錄到relay log中后再繼續接收下一個。這種做法是低效的,也沒有充分利用到MySQL本身的文件緩存。
優化方案
優化IO線程記錄relay log的方式,將以event為單位記錄,修改為以事務為單位進行記錄。合并IO線程小的IO操作,提高IO性能。
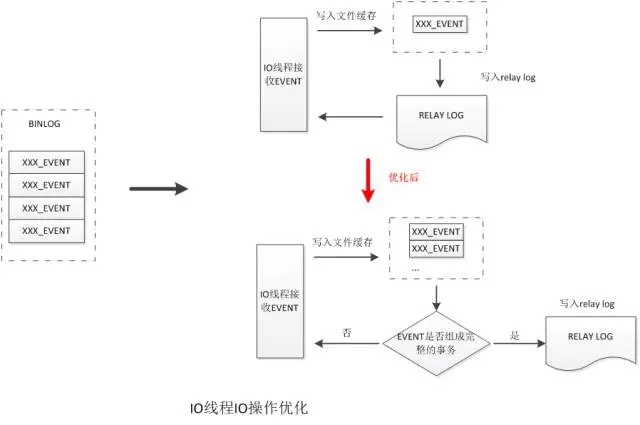
將單個的event寫操作合并為多個event統一寫操作,將小的IO操作合并成較大的IO操作,提高IO性能。
3、Master.info文件記錄的優化
存在的問題
Master.info文件在搭建復制時,記錄主庫IP、PORT等連接主庫的相關信息,在復制過程中,記錄IO線程從主庫接收到的binlog的文件名和位置,文件和位置會在每次記錄relay log成功后更新。
在基于GTID搭建復制后,master.info中記錄的binlog文件和位置不再作為復制的依據,所以master.info中記錄的binlog的文件和位置不再是有效的數據,也就沒有必要每次進行更新。
優化方案
在IO線程記錄relay log成功后,更新master.info文件之前,添加判斷。如果開啟了GTID并且使用GTID作為復制的依據(auto_position=1),那么不再更新master.info中binlog的文件和位置。
其它的master.info操作仍然保留,如change master、shutdown等操作。
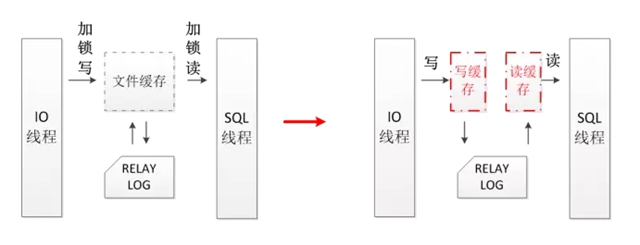
4、Relay log鎖的優化
存在的問題
在IO線程和SQL線程復制進度相似的情況下,在操作relay log時,會使用同一塊文件緩存,在讀寫文件緩存時,需要加鎖來保證操作的正確性。而IO線程和SQL線程需要頻繁地讀寫這塊公共內存,就需要對同一把鎖頻繁的競爭,從而導致性能下降。
優化方案
將IO線程和SQL線程對relay log的操作拆分開來,不再使用同一塊文件緩存。雖然這樣做會導致SQL線程增加一次讀IO操作。但是消除了對鎖的競爭,大大地提高了IO線程和SQL線程整體的性能。
三、總結
優化后的復制流程圖如下:
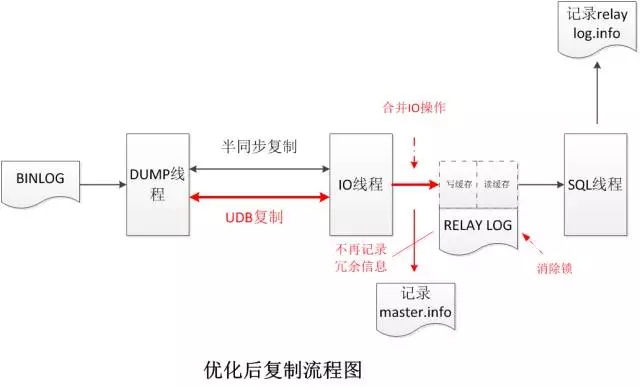
數據庫原生復制流程中包括記錄binlog、記錄relay log、記錄master.info、relay-log.info等,針對上述流程中的部分步驟以及其它未列出的優化,在功能和性能上進行改進,UDB高可用數據庫在功能和性能上均得到了明顯的提升。
看完上述內容,你們掌握如何理解MySQL高可用數據庫內核深度優化的四重定制的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





