溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark程序運行常見錯誤解決方法以及優化是怎樣的,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
一.org.apache.spark.shuffle.FetchFailedException
1.問題描述
這種問題一般發生在有大量shuffle操作的時候,task不斷的failed,然后又重執行,一直循環下去,非常的耗時。
2.報錯提示
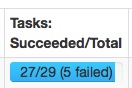
(1) missing output location
org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 0
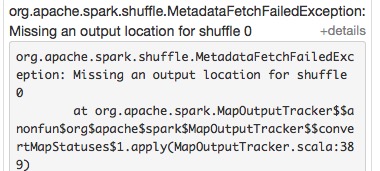
(2) shuffle fetch faild
org.apache.spark.shuffle.FetchFailedException: Failed to connect to spark047215/192.168.47.215:50268
當前的配置為每個executor使用1cpu,5GRAM,啟動了20個executor
3.解決方案
一般遇到這種問題提高executor內存即可,同時增加每個executor的cpu,這樣不會減少task并行度。
spark.executor.memory 15G
spark.executor.cores 3
spark.cores.max 21
啟動的execuote數量為:7個
execuoteNum = spark.cores.max/spark.executor.cores
每個executor的配置:
3core,15G RAM
消耗的內存資源為:105G RAM
15G*7=105G
可以發現使用的資源并沒有提升,但是同樣的任務原來的配置跑幾個小時還在卡著,改了配置后幾分鐘就結束了。
二.Executor&Task Lost
1.問題描述
因為網絡或者gc的原因,worker或executor沒有接收到executor或task的心跳反饋
2.報錯提示
(1) executor lost
WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, aa.local): ExecutorLostFailure (executor lost)
(2) task lost
WARN TaskSetManager: Lost task 69.2 in stage 7.0 (TID 1145, 192.168.47.217): java.io.IOException: Connection from /192.168.47.217:55483 closed
(3) 各種timeout
java.util.concurrent.TimeoutException: Futures timed out after [120 second
ERROR TransportChannelHandler: Connection to /192.168.47.212:35409 has been quiet for 120000 ms while there are outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong
3.解決方案
提高 spark.network.timeout 的值,根據情況改成300(5min)或更高。
默認為 120(120s),配置所有網絡傳輸的延時,如果沒有主動設置以下參數,默認覆蓋其屬性
spark.core.connection.ack.wait.timeout
spark.akka.timeout
spark.storage.blockManagerSlaveTimeoutMs
spark.shuffle.io.connectionTimeout
spark.rpc.askTimeout or spark.rpc.lookupTimeout
三.傾斜
1.問題描述
大多數任務都完成了,還有那么一兩個任務怎么都跑不完或者跑的很慢。
分為數據傾斜和task傾斜兩種。
2.錯誤提示
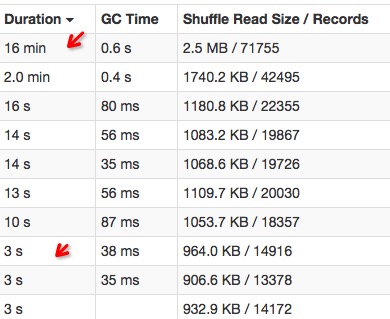
(1) 數據傾斜
(2) 任務傾斜
差距不大的幾個task,有的運行速度特別慢。
3.解決方案
(1) 數據傾斜
數據傾斜大多數情況是由于大量null值或者""引起,在計算前過濾掉這些數據既可。
例如:
sqlContext.sql("...where col is not null and col != ''")(2) 任務傾斜
task傾斜原因比較多,網絡io,cpu,mem都有可能造成這個節點上的任務執行緩慢,可以去看該節點的性能監控來分析原因。以前遇到過同事在spark的一臺worker上跑R的任務導致該節點spark task運行緩慢。
或者可以開啟spark的推測機制,開啟推測機制后如果某一臺機器的幾個task特別慢,推測機制會將任務分配到其他機器執行,***Spark會選取最快的作為最終結果。
spark.speculation true
spark.speculation.interval 100 - 檢測周期,單位毫秒;
spark.speculation.quantile 0.75 - 完成task的百分比時啟動推測
spark.speculation.multiplier 1.5 - 比其他的慢多少倍時啟動推測。
四.OOM(內存溢出)
1.問題描述
內存不夠,數據太多就會拋出OOM的Exeception
因為報錯提示很明顯,這里就不給報錯提示了。。。
2.解決方案
主要有driver OOM和executor OOM兩種
(1) driver OOM
一般是使用了collect操作將所有executor的數據聚合到driver導致。盡量不要使用collect操作即可。
(2) executor OOM
1.可以按下面的內存優化的方法增加code使用內存空間
2.增加executor內存總量,也就是說增加spark.executor.memory的值
3.增加任務并行度(大任務就被分成小任務了),參考下面優化并行度的方法
優化
1.內存
當然如果你的任務shuffle量特別大,同時rdd緩存比較少可以更改下面的參數進一步提高任務運行速度。
spark.storage.memoryFraction - 分配給rdd緩存的比例,默認為0.6(60%),如果緩存的數據較少可以降低該值。
spark.shuffle.memoryFraction - 分配給shuffle數據的內存比例,默認為0.2(20%)
剩下的20%內存空間則是分配給代碼生成對象等。
如果任務運行緩慢,jvm進行頻繁gc或者內存空間不足,或者可以降低上述的兩個值。
"spark.rdd.compress","true" - 默認為false,壓縮序列化的RDD分區,消耗一些cpu減少空間的使用
如果數據只使用一次,不要采用cache操作,因為并不會提高運行速度,還會造成內存浪費。
2.并行度
spark.default.parallelism
發生shuffle時的并行度,在standalone模式下的數量默認為core的個數,也可手動調整,數量設置太大會造成很多小任務,增加啟動任務的開銷,太小,運行大數據量的任務時速度緩慢。
spark.sql.shuffle.partitions
sql聚合操作(發生shuffle)時的并行度,默認為200,如果任務運行緩慢增加這個值。
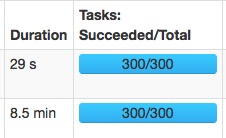
相同的兩個任務:
spark.sql.shuffle.partitions=300:
spark.sql.shuffle.partitions=500:
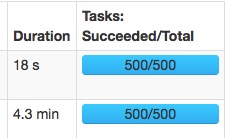
速度變快主要是大量的減少了gc的時間。
修改map階段并行度主要是在代碼中使用rdd.repartition(partitionNum)來操作。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





