溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關MySQL中怎么實現索引和鎖,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
索引
索引常見的幾種類型
索引常見的類型有哈希索引,有序數組索引,二叉樹索引,跳表等等。本文主要探討 MySQL 的默認存儲引擎 InnoDB 的索引結構。
InnoDB的索引結構
在InnoDB中是通過一種多路搜索樹——B+樹實現索引結構的。在B+樹中是只有葉子結點會存儲數據,而且所有葉子結點會形成一個鏈表。而在InnoDB中維護的是一個雙向鏈表。
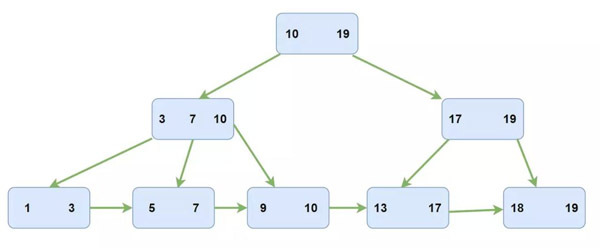
你可能會有一個疑問,為什么使用 B+樹 而不使用二叉樹或者B樹?
首先,我們知道訪問磁盤需要訪問到指定塊中,而訪問指定塊是需要 盤片旋轉 和 磁臂移動 的,這是一個比較耗時的過程,如果增加樹高那么就意味著你需要進行更多次的磁盤訪問,所以會采用n叉樹。
而使用B+樹是因為如果使用B樹在進行一個范圍查找的時候每次都會進行重新檢索,而在B+樹中可以充分利用葉子結點的鏈表。
在建表的時候你可能會添加多個索引,而 InnDB 會為每個索引建立一個 B+樹 進行存儲索引。
比如這個時候我們建立了一個簡單的測試表
create table test( id int primary key, a int not null, name varchar, index(a) )engine = InnoDB;
這個時候 InnDB 就會為我們建立兩個 B+索引樹
一個是 主鍵 的 聚簇索引,另一個是 普通索引 的 輔助索引,這里我直接貼上 MySQL淺談(索引、鎖) 這篇文章上面的貼圖(因為我懶不想畫圖了。。。)
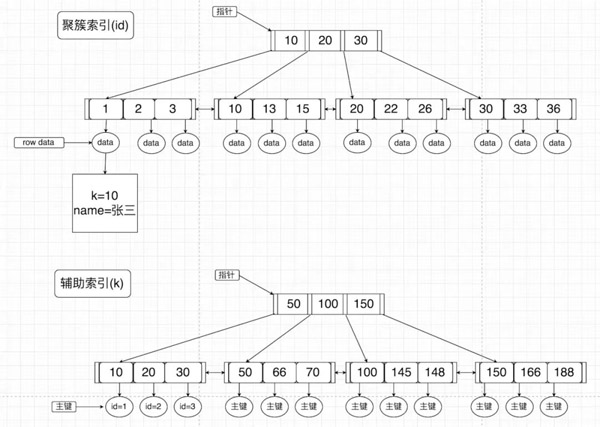
可以看到在輔助索引上面的葉子節點的值只是存了主鍵的值,而在主鍵的聚簇索引上的葉子節點才是存上了整條記錄的值。
回表
所以這里就會引申出一個概念叫回表,比如這個時候我們進行一個查詢操作
select name from test where a = 30;
我們知道因為條件 MySQL 是會走 a 的索引的,但是 a 索引上并沒有存儲 name 的值,此時我們就需要拿到相應 a 上的主鍵值,然后通過這個主鍵值去走 聚簇索引 最終拿到其中的name值,這個過程就叫回表。
我們來總結一下回表是什么?MySQL在輔助索引上找到對應的主鍵值并通過主鍵值在聚簇索引上查找所要的數據就叫回表。
索引維護
我們知道索引是需要占用空間的,索引雖能提升我們的查詢速度但是也是不能濫用。
比如我們在用戶表里用身份證號做主鍵,那么每個二級索引的葉子節點占用約20個字節,而如果用整型做主鍵,則只要4個字節,如果是長整型(bigint)則是8個字節。也就是說如果我用整型后面維護了4個g的索引列表,那么用身份證將會是20個g。
所以我們可以通過縮減索引的大小來減少索引所占空間。
當然B+樹為了維護索引的有序性會在刪除,插入的時候進行一些必要的維護(在InnoDB中刪除會將節點標記為“可復用”以減少對結構的變動)。
比如在增加一個節點的時候可能會遇到數據頁滿了的情況,這個時候就需要做頁的分裂,這是一個比較耗時的工作,而且頁的分裂還會導致數據頁的利用率變低,比如原來存放三個數據的數據頁再次添加一個數據的時候需要做頁分裂,這個時候就會將現有的四個數據分配到兩個數據頁中,這樣就減少了數據頁利用率。
覆蓋索引
上面提到了 回表,而有時候我們查輔助索引的時候就已經滿足了我們需要查的數據,這個時候 InnoDB 就會進行一個叫 覆蓋索引 的操作來提升效率,減少回表。
比如這個時候我們進行一個 select 操作
select id from test where a = 1;
這個時候很明顯我們走了 a 的索引直接能獲取到 id 的值,這個時候就不需要進行回表,我們這個時候就使用了 覆蓋索引。
簡單來說 覆蓋索引 就是當我們走輔助索引的時候能獲取到我們所需要的數據的時候不需要再次進行回表操作的操作。
聯合索引
這個時候我們新建一個學生表
CREATE TABLE `stu` ( `id` int(11) NOT NULL, `class` int(11) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `class_name` (`class`,`name`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8
我們使用 class(班級號) 和 name 做一個 聯合索引,你可能會問這個聯合索引有什么用呢?我們可以結合著上面的 覆蓋索引 去理解,比如這個時候我們有一個需求,我們需要通過班級號去找對應的學生姓名 。
select name from stu where class = 102;
這個時候我們就可以直接在 輔助索引 上查找到學生姓名而不需要再次回表。
總的來說,設計好索引,充分利用覆蓋索引能很大提升檢索速度。
最左前綴原則
這個是以 聯合索引 作為基礎的,是一種聯合索引的匹配規則。
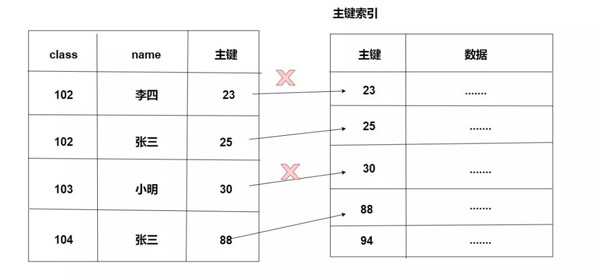
這個時候,我們將上面的需求稍微變動一下,這時我們有個學生遲到,但是他在門衛記錄信息的時候只寫了自己的名字張三而沒有寫班級,所以我們需要通過學生姓名去查找相應的班級號。
select class from stu where name = '張三';
這個時候我們就不會走我們的聯合索引了,而是進行了全表掃描。
為什么?因為 最左匹配原則。我們可以畫一張簡單的圖來理解一下。
我們可以看到整個索引設計就是這么設計的,所以我們需要查找的時候也需要遵循著這個規則,如果我們直接使用name,那么InnoDB是不知道我們需要干什么的。
當然最左匹配原則還有這些規則
全值匹配的時候優化器會改變順序,也就是說你全值匹配時的順序和原先的聯合索引順序不一致沒有關系,優化器會幫你調好。
索引匹配從最左邊的地方開始,如果沒有則會進行全表掃描,比如你設計了一個(a,b,c)的聯合索引,然后你可以使用(a),(a,b),(a,b,c) 而你使用 (b),(b,c),(c)就用不到索引了。
遇到范圍匹配會取消索引。比如這個時候你進行一個這樣的 select 操作
select * from stu where class > 100 and name = '張三';
這個時候 InnoDB 就會放棄索引而進行全表掃描,因為這個時候 InnoDB 會不知道怎么進行遍歷索引,所以進行全表掃描。
索引下推
我給你挖了個坑。剛剛的操作在 MySQL5.6 版本以前是需要進行回表的,但是5.6之后的版本做了一個叫 索引下推 的優化。
select * from stu where class > 100 and name = '張三';
如何優化的呢?因為剛剛的最左匹配原則我們放棄了索引,后面我們緊接著會通過回表進行判斷 name,這個時候我們所要做的操作應該是這樣的

但是有了索引下推之后就變成這樣了,此時 "李四" 和 "小明" 這兩個不會再進行回表。
因為這里匹配了后面的name = 張三,也就是說,如果最左匹配原則因為范圍查詢終止了,InnoDB還是會索引下推來優化性能。
一些實踐
哪些情況需要創建索引?
頻繁作為查詢條件的字段應創建索引。
多表關聯查詢的時候,關聯字段應該創建索引。
查詢中的排序字段,應該創建索引。
統計或者分組字段需要創建索引。
哪些情況不需要創建索引
表記錄少。
經常增刪改查的表。
頻繁更新的字段。
where 條件使用不高的字段。
字段很大的時候。
其他
盡量選擇區分度高的列作為索引。
不要對索引進行一些函數操作,還應注意隱式的類型轉換和字符編碼轉換。
盡可能的擴展索引,不要新建立索引。比如表中已經有了a的索引,現在要加(a,b)的索引,那么只需要修改原來的索引即可。
多考慮覆蓋索引,索引下推,最左匹配。
鎖
全局鎖
MySQL提供了一個加全局讀鎖的方法,命令是 Flush tables with read lock (FTWRL)。當你需要讓整個庫處于只讀狀態的時候,可以使用這個命令,之后其他線程的以下語句會被阻塞:數據更新語句(數據的增刪改)、數據定義語句(包括建表、修改表結構等)和更新類事務的提交語句。
一般會在進行 全庫邏輯備份 的時候使用,這樣就能確保 其他線程不能對該數據庫做更新操作。
在 MVCC 中提供了獲取 一致性視圖 的操作使得備份變得非常簡單,如果想了解 MVCC 可以參考
https://juejin.im/post/5da8493ae51d4524b25add55
表鎖
MDL(Meta Data Lock)元數據鎖
MDL鎖用來保證只有一個線程能對該表進行表結構更改。
怎么說呢?MDL分為 MDL寫鎖 和 MDL讀鎖,加鎖規則是這樣的
當線程對一個表進行 CRUD 操作的時候會加 MDL讀鎖
當線程對一個表進行 表結構更改 操作的時候會加 MDL寫鎖
寫鎖和讀鎖,寫鎖和寫鎖互斥,讀鎖之間不互斥
lock tables xxx read/write;
這是給一個表設置讀鎖和寫鎖的命令,如果在某個線程A中執行lock tables t1 read, t2 write; 這個語句,則其他線程寫t1、讀寫t2的語句都會被阻塞。同時,線程A在執行unlock tables之前,也只能執行讀t1、讀寫t2的操作。連寫t1都不允許,自然也不能訪問其他表。
這種表鎖是一種處理并發的方式,但是在InnoDB中常用的是行鎖。
行鎖
我們知道在5.5版本以前 MySQL 的默認存儲引擎是 MyISAM,而 MyISAM 和 InnoDB 最大的區別就是兩個
事務
行鎖
其中行鎖是我們今天的主題,如果不了解事務可以去補習一下。
其實行鎖就是兩個鎖,你可以理解為 寫鎖(排他鎖 X鎖)和讀鎖(共享鎖 S鎖)
共享鎖(S鎖):允許一個事務去讀一行,阻止其他事務獲得相同數據集的排他鎖。也叫做讀鎖:讀鎖是共享的,多個客戶可以同時讀取同一個資源,但不允許其他客戶修改。
排他鎖(X鎖):允許獲得排他鎖的事務更新數據,阻止其他事務取得相同數據集的共享讀鎖和排他寫鎖。也叫做寫鎖:寫鎖是排他的,寫鎖會阻塞其他的寫鎖和讀鎖。
而行鎖還會引起一個一個很頭疼的問題,那就是死鎖。
如果事務A對行100加了寫鎖,事務B對行101加了寫鎖,此時事務A想要修改行101而事務B又想修改行100,這樣占有且等待就導致了死鎖問題,而面對死鎖問題就只有檢測和預防了。
next-key鎖
MVCC 和行鎖是無法解決 幻讀 問題的,這個時候 InnoDB 使用了 一個叫 GAP鎖(間隙鎖) 的東西,它配合 行鎖 形成了 next-key鎖,解決了幻讀的問題。
但是因為它的加鎖規則,又導致了擴大了一些加鎖范圍從而減少數據庫并發能力。具體的加鎖規則如下:
加鎖的基本單位是next-key lock 就是行鎖和GAP鎖結合。
查找過程中訪問到的對象就會加鎖。
索引上的等值查詢,給唯一索引加鎖的時候,next-key lock退化為行鎖。
索引上的等值查詢,向右遍歷時且最后一個值不滿足等值條件的時候,next-key lock退化為間隙鎖。
唯一索引上的范圍查詢會訪問到不滿足條件的第一個值為止。
關于MySQL中怎么實現索引和鎖就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





