溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Hadoop的數據分析平臺怎么搭建”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
企業發展到一定規模都會搭建單獨的BI平臺來做數據分析,即OLAP(聯機分析處理),一般都是基于數據庫技術來構建,基本都是單機產品。除了業務數據的相關分析外,互聯網企業還會對用戶行為進行分析,進一步挖掘潛在價值,這時數據就會膨脹得很厲害,一天的數據量可能會成千萬或上億,對基于數據庫的傳統數據分析平臺的數據存儲和分析計算帶來了很大挑戰。
為了應對隨著數據量的增長、數據處理性能的可擴展性,許多企業紛紛轉向Hadoop平臺來搭建數據分析平臺。Hadoop平臺具有分布式存儲及并行計算的特性,因此可輕松擴展存儲結點和計算結點,解決數據增長帶來的性能瓶頸。
隨著越來越多的企業開始使用Hadoop平臺,也為Hadoop平臺引入了許多的技術,如Hive、Spark SQL、Kafka等,豐富的組件使得用Hadoop構建數據分析平臺代替傳統數據分析平臺成為可能。
一、數據分析平臺架構原理
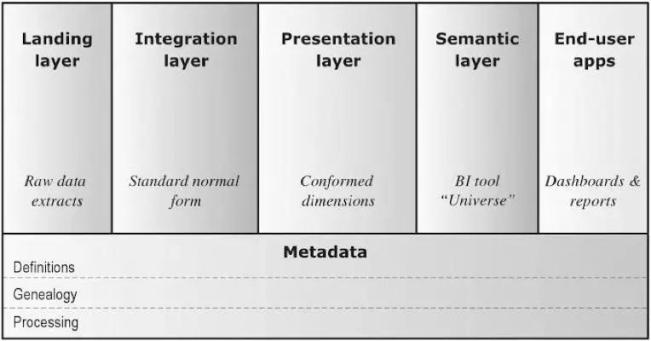
從概念上講,我們可以把數據分析平臺分為接入層(Landing)、整合層(Integration)、表現層(Persentation)、語義層(Semantic)、終端用戶應用(End-user applications)、元數據(Metadata)。基于Hadoop和數據庫的分析平臺基本概念和邏輯架構是通用的,只是技術選型的不同:
接入層(Landing):以和源系統相同的結構暫存原始數據,有時被稱為“貼源層”或ODS;
整合層(Integration):持久存儲整合后的企業數據,針對企業信息實體和業務事件建模,代表組織的“***真相來源”,有時被稱為“數據倉庫”;
表現層(Presentation):為滿足最終用戶的需求提供可消費的數據,針對商業智能和查詢性能建模,有時被稱為“數據集市”;
語義層(Semantic):提供數據的呈現形式和訪問控制,例如某種報表工具;
終端用戶應用(End-user applications):使用語義層的工具,將表現層數據最終呈現給用戶,包括儀表板、報表、圖表等多種形式;
元數據(Metadata):記錄各層數據項的定義(Definitions)、血緣(Genealogy)、處理過程(Processing)。
來自不同數據源的“生”數據(接入層),和經過中間處理之后得到的整合層、表現層的數據模型,都會存儲在數據湖里備用。
數據湖的實現通常建立在Hadoop生態上,可能直接存儲在HDFS上,也可能存儲在HBase或Hive上,也有用關系型數據庫作為數據湖存儲的可能性存在。

下圖說明了數據分析平臺的數據處理流程:
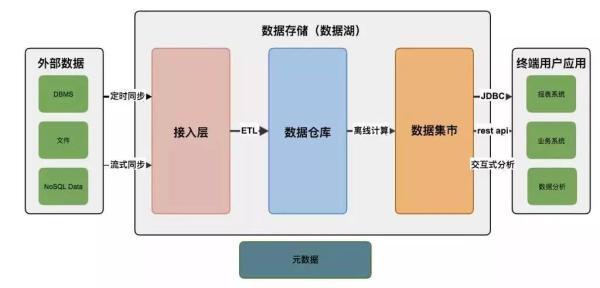
數據分析基本都是單獨的系統,會將其他數據源的數據(即外部數據)同步到數據平臺的存儲體系來(即數據湖),一般數據先進入到接入層,這一層只簡單的將外部數據同步到數據分析平臺,沒有做其他處理,這樣同步出錯后重試即可,有定時同步和流式同步兩種:
定時同步即我們設定在指定時間觸發同步動作;
流式同步即外部數據通過Kafka或MQ發送數據修改通知及內容。
數據分析平臺執行對應操作修改數據。
接入層數據需要經過ETL處理步驟才會進入數據倉庫,數據分析人員都是基于數據倉庫的數據來做分析計算,數據倉庫可以看作數據分析的***來源,ETL會將接入層的數據做數據清洗、轉換,再加載到數據倉庫,過濾或處理不合法、不完整的數據,并使用統一的維度來表示數據狀態。有的系統會在這一層就將數據倉庫構建成數據立方體、將維度信息構建成雪花或星型模式;也有的系統這一層只是統一了所有數據信息,沒有做數據立方體,留在數據集市做。
數據集市是基于數據倉庫數據對業務關心的信息做計算提取后得到的進一步信息,是業務人員直接面對的信息,是數據倉庫的進一步計算和深入分析的結果,一般都會構建數據立方體。系統開發人員一般會開發頁面來向用戶展示數據集市的數據。
二、基于Hadoop構建數據分析平臺
基于Hadoop構建的數據分析平臺建構理論與數據處理流程與前面講的相同。傳統分析平臺使用數據庫套件構建,這里我們使用Hadoop平臺的組件。
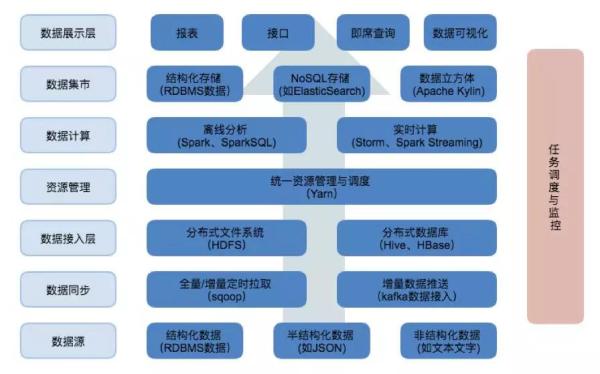
上面這張圖是我們使用到的Hadoop平臺的組件,數據從下到上流動,數據處理流程和上面說的一致。
任務調度負責將數據處理的流程串聯起來,這里我選擇使用的是Oozie,也有很多其它選擇。
1、數據存儲
基于Hadoop的數據湖主要用到了HDFS、Hive和HBase,HDFS是Hadoop平臺的文件存儲系統,我們直接操縱文件是比較復雜的,所以可以使用分布式數據庫Hive或HBase用來做數據湖,存儲接入層、數據倉庫、數據集市的數據。
Hive和HBase各有優勢:HBase是一個NoSQL數據庫,隨機查詢性能和可擴展性都比較好;而Hive是一個基于HDFS的數據庫,數據文件都以HDFS文件(夾)形式存放,存儲了表的存儲位置(即在HDFS中的位置)、存儲格式等元數據,Hive支持SQL查詢,可將查詢解析成Map/Reduce執行,這對傳統的數據分析平臺開發人員更友好。
Hive數據格式可選擇文本格式或二進制格式,文本格式有csv、json或自定義分隔,二進制格式有orc或parquet,他們都基于行列式存儲,在查詢時性能更好。同時可選擇分區(partition),這樣在查詢時可通過條件過濾進一步減少數據量。接入層一般選擇csv或json等文本格式,也不做分區,以盡量簡化數據同步。數據倉庫則選擇orc或parquet,以提升數據離線計算性能。
數據集市這塊可以選擇將數據灌回傳統數據庫(RDBMS),也可以停留在數據分析平臺,使用NoSQL提供數據查詢或用Apache Kylin來構建數據立方體,提供SQL查詢接口。
2、數據同步
我們通過數據同步功能使得數據到達接入層,使用到了Sqoop和Kafka。數據同步可以分為全量同步和增量同步,對于小表可以采用全量同步,對于大表全量同步是比較耗時的,一般都采用增量同步,將變動同步到數據平臺執行,以達到兩邊數據一致的目的。
全量同步使用Sqoop來完成,增量同步如果考慮定時執行,也可以用Sqoop來完成。或者,也可以通過Kafka等MQ流式同步數據,前提是外部數據源會將變動發送到MQ。
3、ETL及離線計算
我們使用Yarn來統一管理和調度計算資源。相較Map/Reduce,Spark SQL及Spark RDD對開發人員更友好,基于內存計算效率也更高,所以我們使用Spark on Yarn作為分析平臺的計算選型。
ETL可以通過Spark SQL或Hive SQL來完成,Hive在2.0以后支持存儲過程,使用起來更方便。當然,出于性能考慮Saprk SQL還是不錯的選擇。
“Hadoop的數據分析平臺怎么搭建”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





