溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“分享一次數據庫SQL查詢的數次輪回”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“分享一次數據庫SQL查詢的數次輪回”吧!
我們使用數據庫,直觀感受上是客戶端發送一個 SQL,數據庫把這個SQL執行一下,查出來數據返回給客戶端。但其實SQL在背后被轉換,優化,歷經許多「磨難」才把結果給取回來。
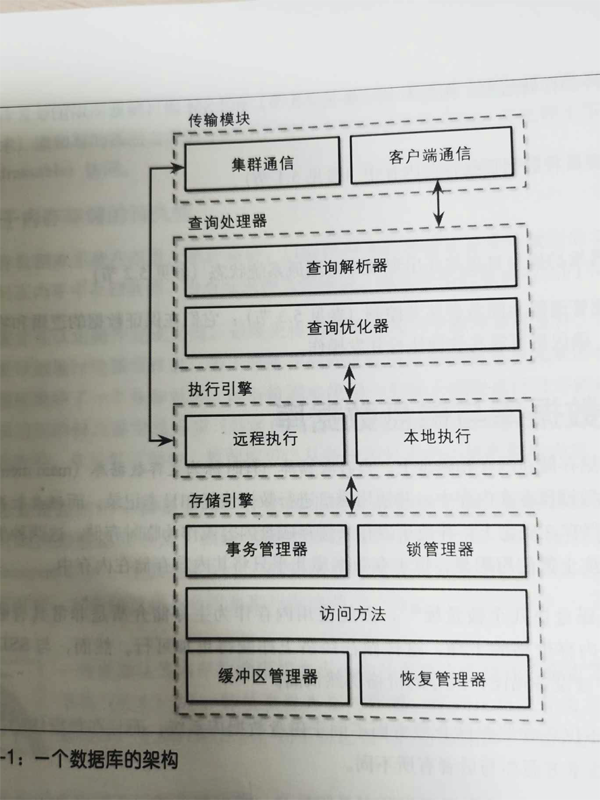
如上圖, 我們看到是從查詢處理器里經過解析器,優化器,才進入的執行引擎。
今天我們先來看查詢管理器,后面再重點來看查詢的優化器是怎樣精打細算的。
查詢管理器
這一部分是數據庫功能體現。在這部分里,會將寫得不好的查詢轉換成可以快速執行代碼, 然后執行它,并將結果返回給客戶端。這個過程會包含多個步驟:
首先解析查詢是否是合法的
然后會將查詢重寫,去除沒用的操作符,并做一些預優化
對查詢優化以提升性能,將查詢轉換成執行和數據訪問計劃
編譯查詢計劃
執行
這部分里,對最后兩點我們不會說太多,相對來說他倆沒那么關鍵。
查詢解析器
每個SQL語句都會經過分析器去校驗語法是否正確。如果你寫錯了,解析器會拒絕查詢。比如你手誤,把SELECT 寫成了 SLECT,那直接會停止在這兒。
此外,還會檢查關鍵詞順序是否正確。
然后,查詢SQL中的表名和列名也會分析,解析器會通過數據庫的 metadata 來檢查以下內容:
表是否存在
表中對應的查詢字段是否存在
對應的操作符是不是能作用在指定的列上(比如不能把一個數字和字符串比大小,也不能給一個integer用substring)
之后會檢查查詢中對應的表你是否有權限去讀或寫,畢竟這些訪問權限是DBA分配的。
在解析的過程中, 查詢SQL 會被轉換成數據庫的內部表示形式(一般是一棵樹)。如果一切 OK,這個轉換后的內容會發送給查詢「重寫器」
查詢 Rewriter
在這一步,我們拿到了一個查詢的內部表示形式,重寫器的目標是要:
對查詢做預優化
避免無用的操作
幫助優化器發現最佳方案
重寫器會對查詢執行一系列已知的規則。如果查詢符合某個規則的模式,就會應用這個規則來重寫查詢。以下是(可選)的規則:
視圖合并:如果在查詢中使用了視圖,那視圖將會隨著該視圖的SQL代碼進行轉換。
子查詢打平:有子查詢的查詢很難優化,因此重寫器將嘗試修改查詢,甚至刪除子查詢。
例如
SELECT PERSON.* FROM PERSON WHERE PERSON.person_key IN (SELECT MAILS.person_key FROM MAILS WHERE MAILS.mail LIKE 'christophe%');
就會被這條SQL替換
SELECT PERSON.* FROM PERSON, MAILS WHERE PERSON.person_key = MAILS.person_key and MAILS.mail LIKE 'christophe%';
去除無用的操作符:如果你用了DISTINCT,但你已經有一個UNIQUE約束以保證數據唯一,那DISTINCT關鍵字就會被刪除。
消除多余的連接:如果你有兩次相同的連接條件,因為一個連接條件被隱藏在視圖中,或者由于傳遞性而導致無用的連接,則將其刪除。
持續的算術評估:如果查詢是需要計算的內容,那么在重寫過程中將對其進行一次計算。比如,把WHERE AGE> 10 + 2轉換為WHERE AGE> 12,然后將TODATE(“ 日期”)轉換為datetime格式的日期
(高級)分區修正:如果你使用了分區表,重寫器可以找到要使用的分區。
(高級)實例化視圖重寫:如果已經有了和查詢子集匹配的實例化視圖,重寫器會檢查該視圖是否是最新視圖,并修改查詢使用實例化視圖而不是原始表。
(高級)自定義規則:如果你創建了重寫查詢的自定義規則,那重寫器會執行這些規則(高級)Olap轉換:分析/窗口函數,星型連接,匯總…也都會進行轉換(但是具體是由重寫器還是優化器完成的取決于數據庫,因為這兩個過程鄰近)。
這個重寫后的查詢會發送給查詢優化器,有趣的來了。
統計
在進入數據庫如何優化查詢之前,我們需要先談談統計信息,因為沒有統計信息,數據庫就會很傻。如果你不告訴數據庫分析自己的數據,它不會這樣做,而且會做出錯誤的假設。
那數據庫需要什么信息呢?
我們大概說一下論數據庫和操作系統如何存儲數據的。他們使用的最小單位稱為頁或塊(默認為4或8 KB)。也就是說,如果你只需要1 KB,也會占一頁。如果頁面占用8 KB,那就會浪費7 KB。
回到統計來,當你要求數據庫獲取統計信息時,它會計算這些內容:
一個表中的行或頁的數量
一個表里的每一列
單獨的數據內容
數據的長度(最小,最大,平均)
數據區間信息(最小、最大、平均)
表的索引信息
這些統計信息會幫助優化器更好的預估查詢中磁盤I/O,CPU以及內存的使用。
每一列的統計信息都很重要。比如一個 PERSON 表,需要在 LAST_NAME, FIRST_NAME兩列做連接,通過統計,數據庫能知道FIRST_NAME這一列共多少個不同的值,LAST_NAME有多少個不同的值。所以數據庫會使用LAST_NAME,FIRST_NAME來連接,而不是FIRST_NAME,LAST_NAME,因為LAST_NAME不太可能相同,會少產生數據。大多數情況下,數據庫的前兩三個字符比較 LAST_NAME就足夠了。
當然這些是基本的統計信息,你也可以讓數據庫計算 histograms 這種更高階的統計數據。最常使用的值,質量等等,通過這些附加信息,可以幫助數據庫找到更高效的查詢計劃,特別是像等值查詢,以及范圍查詢這種。因為數據庫已經知道這種情況下有多少條記錄。
這些統計信息記錄在數據庫的元數據中。因此也是需要花時間不斷更新的。這也是為啥在大多數數據庫里他都不自動更新。
到此,相信大家對“分享一次數據庫SQL查詢的數次輪回”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





