溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Consul故障分析與優化是怎么樣的,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
從微服務平臺的角度出發希望提供統一的服務注冊中心,讓任何的業務和團隊只要使用這套基礎設施,相互發現只需要協商好服務名即可;還需要支持業務做多DC部署和故障切換。由于在擴展性和多DC支持上的良好設計,我們選擇了Consul,并采用了Consul推薦的架構,單個DC內有Consul Server和Consul Agent,DC之間是WAN模式并且相互對等,結構如下圖所示:
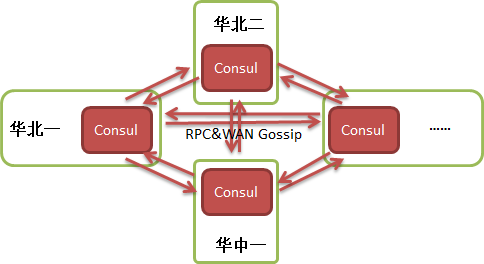
注:圖中只畫了四個DC,實際生產環境根據公司機房建設以及第三方云的接入情況,共有十幾個DC。
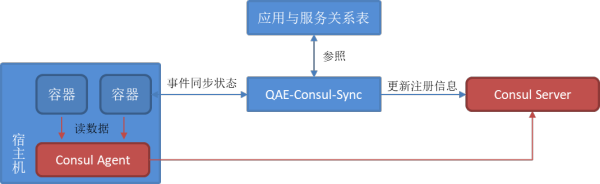
愛奇藝內部的容器應用平臺QAE與Consul進行了集成。由于早期是基于Mesos/Marathon體系開發,沒有Pod容器組概念,無法友好的注入sidecar的容器,因此我們選擇了微服務模式中的第三方注冊模式,即由QAE系統實時向Consul同步注冊信息,如下圖所示;并且使用了Consul的external service模式,這樣可以避免兩個系統狀態不一致時引起故障,例如Consul已經將節點或服務實例判定為不健康,但是QAE沒有感知到,也就不會重啟或重新調度,導致沒有健康實例可用。
其中QAE應用與服務的關系表示例如下:
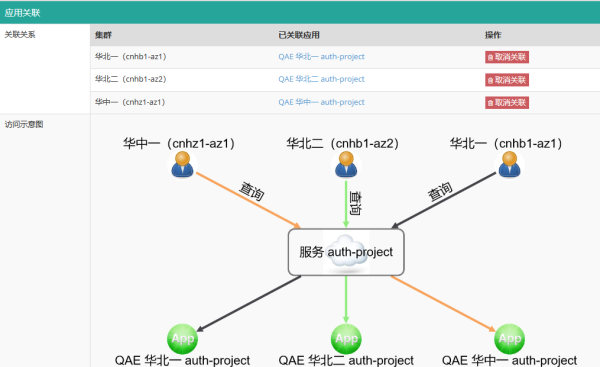
每個QAE應用代表一組容器,應用與服務的映射關系是松耦合的,根據應用實際所在的DC將其關聯到對應Consul DC即可,后續應用容器的更新、擴縮容、失敗重啟等狀態變化都會實時體現在Consul的注冊數據中。
微服務平臺API網關是服務注冊中心最重要的使用方之一。網關會根據地區、運營商等因素部署多個集群,每個網關集群會根據內網位置對應到一個Consul集群,并且從Consul查詢最近的服務實例,如下圖所示:
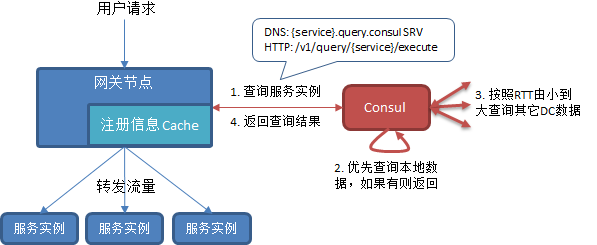
這里我們使用了Consul的PreparedQuery功能,對所有服務優先返回本DC服務實例,如果本DC沒有則根據DC間RTT由近到遠查詢其它DC數據。
Consul故障
Consul從2016年底上線開始,已經穩定運行超過三年時間,但是最近我們卻遇到了故障,收到了某個DC多臺Consul Server不響應請求、大量Consul Agent連不上Server的告警,并且沒有自動恢復。Server端觀察到的現象主要有:
raft協議不停選舉失敗,無法獲得leader;
HTTP&DNS查詢接口大量超時,觀察到有些超過幾十秒才返回(正常應當是毫秒級別返回);
goroutine快速線性上升,內存同步上升,最終觸發系統OOM;在日志中沒能找到明確的問題,從監控metrics則觀察到PreparedQuery的執行耗時異常增大,如下圖所示:
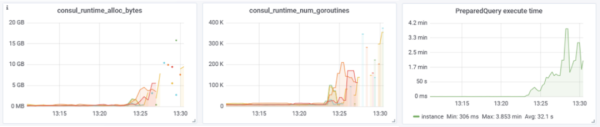
此時API網關查詢服務信息也超時失敗,我們將對應的網關集群切到了其它DC,之后重啟Consul進程,恢復正常。
故障分析
經過日志排查,發現故障前發生過DC間的網絡抖動(RTT增加,伴隨丟包),持續時間大約1分鐘,我們初步分析是DC間網絡抖動導致正常收到的PreparedQuery請求積壓在Server中無法快速返回,隨著時間積累越來越多,占用的goroutine和內存也越來越多,最終導致Server異常。
跟隨這個想法,嘗試在測試環境復現,共有4個DC,單臺Server的PreparedQuery QPS為1.5K,每個PreparedQuery查詢都會觸發3次跨DC查詢,然后使用tc-netem工具模擬DC間的RTT增加的情況,得到了以下結果:
當DC間RTT由正常的2ms變為800ms之后,Consul Server的goroutine、內存確實會線性增長,PreparedQuery執行耗時也線性增長,如下圖所示:
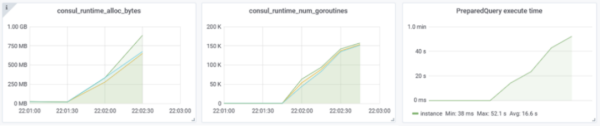
雖然goroutine、內存在增長,但是在OOM之前,Consul Server的其它功能未受影響,Raft協議工作正常,本DC的數據查詢請求也能正常響應;
在DC間RTT恢復到2ms的一瞬間,Consul Server丟失leader,接著Raft不停選舉失敗,無法恢復。
以上操作能夠穩定的復現故障,使分析工作有了方向。首先基本證實了goroutine和內存的增長是由于PreparedQuery請求積壓導致的,而積壓的原因在初期是網絡請求阻塞,在網絡恢復后仍然積壓原因暫時未知,這時整個進程應當是處于異常狀態;那么,為什么網絡恢復之后Consul反而故障了呢?Raft只有DC內網絡通信,為什么也異常了呢?是最讓我們困惑的問題。
最開始的時候將重點放在了Raft問題上,通過跟蹤社區issue,找到了hashicorp/raft#6852,其中描述到我們的版本在高負載、網絡抖動情況下可能出現raft死鎖,現象與我們十分相似。但是按照issue更新Raft庫以及Consul相關代碼之后,測試環境復現時故障依然存在。
之后嘗試給Raft庫添加日志,以便看清楚Raft工作的細節,這次我們發現Raft成員從進入Candidate狀態,到請求peer節點為自己投票,日志間隔了10s,而代碼中僅僅是執行了一行metrics更新,如下圖所示:
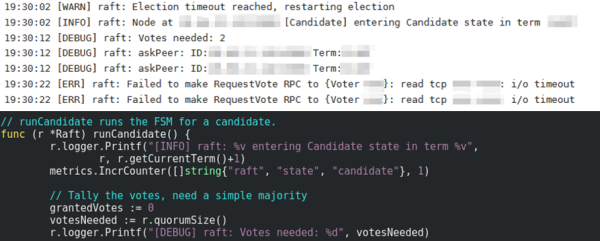
因此懷疑metrics調用出現了阻塞,導致整個系統運行異常,之后我們在發布歷史中找到了相關優化,低版本的armon/go-metrics在Prometheus實現中采用了全局鎖sync.Mutex,所有metrics更新都需要先獲取這個鎖,而v0.3.3版本改用了sync.Map,每個metric作為字典的一個鍵,只在鍵初始化的時候需要獲取全局鎖,之后不同metric更新值的時候就不存在鎖競爭,相同metric更新時使用sync.Atomic保證原子操作,整體上效率更高。更新對應的依賴庫之后,復現網絡抖動之后,Consul Server可以自行恢復正常。
這樣看來的確是由于metrics代碼阻塞,導致了系統整體異常。但我們依然有疑問,復現環境下單臺Server 的PreparedQuery QPS為1.5K,而穩定的網絡環境下單臺Server壓測QPS到2.8K時依然工作正常。也就是說正常情況下原有代碼是滿足性能需求的,只有在故障時出現了性能問題。
接下來的排查陷入了困境,經過反復試驗,我們發現了一個有趣的現象:使用go 1.9編譯的版本(也是生產環境使用的版本)能復現出故障;同樣的代碼使用go 1.14編譯就無法復現出故障。經過仔細查看,我們在go的發布歷史中找到了以下兩條記錄:

根據代碼我們找到了用戶反饋在go1.9~1.13版本,在大量goroutine同時競爭一個sync.Mutex時,會出現性能急劇下降的情況,這能很好的解釋我們的問題。由于Consul代碼依賴了go 1.9新增的內置庫,我們無法用更低的版本編譯,因此我們將go 1.14中sync.Mutex相關的優化去掉,如下圖所示,然后用這個版本的go編譯Consul,果然又可以復現我們的故障了。
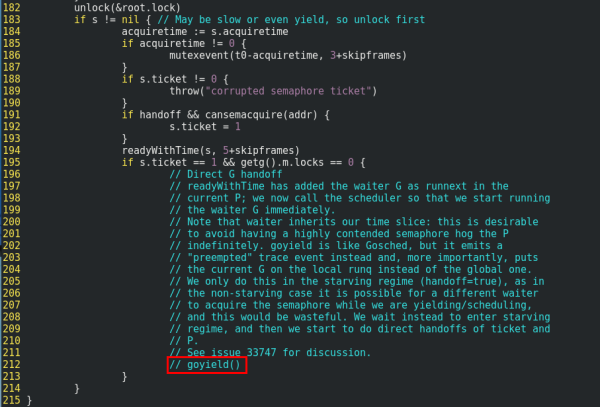
回顧語言的更新歷史,go 1.9版本添加了公平鎖特性,在原有normal模式上添加了starvation模式,來避免鎖等待的長尾效應。但是normal模式下新的goroutine在運行時有較高的幾率競爭鎖成功,從而免去goroutine的切換,整體效率是較高的;而在starvation模式下,新的goroutine不會直接競爭鎖,而是會把自己排到等待隊列末端,然后休眠等待喚醒,鎖按照等待隊列FIFO分配,獲取到鎖的goroutine被調度執行,這樣會增加goroutine調度、切換的成本。在go 1.14中針對性能問題進行了改善,在starvation模式下,當goroutine執行解鎖操作時,會直接將CPU時間讓給下一個等待鎖的goroutine執行,整體上會使得被鎖保護部分的代碼得到加速執行。
到此故障的原因就清楚了,首先網絡抖動,導致大量PreparedQuery請求積壓在Server中,同時也造成了大量的goroutine和內存使用;在網絡恢復之后,積壓的PreparedQuery繼續執行,在我們的復現場景下,積壓的goroutine量會超過150K,這些goroutine在執行時都會更新metrics從而去獲取全局的sync.Mutex,此時切換到starvation模式并且性能下降,大量時間都在等待sync.Mutex,請求阻塞超時;除了積壓的goroutine,新的PreparedQuery還在不停接收,獲取鎖時同樣被阻塞,結果是sync.Mutex保持在starvation模式無法自動恢復;另一方面raft代碼運行會依賴定時器、超時、節點間消息的及時傳遞與處理,并且這些超時通常是秒、毫秒級別的,但metrics代碼阻塞過久,直接導致時序相關的邏輯無法正常運行。
接著生產環境中我們將發現的問題都進行了更新,升級到go 1.14,armon/go-metrics v0.3.3,以及hashicorp/raft v1.1.2版本,使Consul達到一個穩定狀態。此外還整理完善了監控指標,核心監控包括以下維度:
進程:CPU、內存、goroutine、連接數
Raft:成員狀態變動、提交速率、提交耗時、同步心跳、同步延時
RPC:連接數、跨DC請求數
寫負載:注冊&解注冊速率
讀負載:Catalog/Health/PreparedQuery請求量,執行耗時
冗余注冊
根據Consul的故障期間的故障現象,我們對服務注冊中心的架構進行了重新審視。
在Consul的架構中,某個DC Consul Server全部故障了就代表這個DC故障,要靠其它DC來做災備。但是實際情況中,很多不在關鍵路徑上的服務、SLA要求不是特別高的服務并沒有多DC部署,這時如果所在DC的Consul故障,那么整個服務就會故障。
針對本身并沒有做多DC部署的服務,如果可以在冗余DC注冊,那么單個DC Consul故障時,其它DC還可以正常發現。因此我們修改了QAE注冊關系表,對于本身只有單DC部署的服務,系統自動在其它DC也注冊一份,如下圖所示:
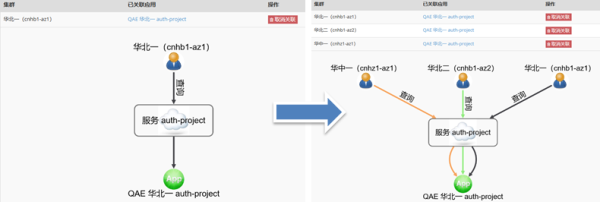
QAE這種冗余注冊相當于在上層做了數據多寫操作。Consul本身不會在各DC間同步服務注冊數據,因此直接通過Consul Agent方式注冊的服務還沒有較好的冗余注冊方法,還是依賴服務本身做好多DC部署。
保障API網關
目前API網關的正常工作依賴于Consul PreparedQuery查詢結果在本地的緩存,目前的交互方式有兩方面問題:
網關緩存是lazy的,網關第一次用到時才會從Consul查詢加載,Consul故障時查詢失敗會導致請求轉發失敗;
PreparedQuery內部可能會涉及多次跨DC查詢,耗時較多,屬于復雜查詢,由于每個網關節點需要單獨構建緩存,并且緩存有TTL,會導致相同的PreparedQuery查詢執行很多次,查詢QPS會隨著網關集群規模線性增長。
為了提高網關查詢Consul的穩定性和效率,我們選擇為每個網關集群部署一個單獨的Consul集群,如下圖所示:

圖中紅色的是原有的Consul集群,綠色的是為網關單獨部署的Consul集群,它只在單DC內部工作。我們開發了Gateway-Consul-Sync組件,它會周期性的從公共Consul集群讀取服務的PreparedQuery查詢結果,然后寫入到綠色的Consul集群,網關則直接訪問綠色的Consul進行數據查詢。這樣改造之后有以下幾方面好處:
從支持網關的角度看,公共集群的負載原來是隨網關節點數線性增長,改造后變成隨服務個數線性增長,并且單個服務在同步周期內只會執行一次PreparedQuery查詢,整體負載會降低;
圖中綠色Consul只供網關使用,其PreparedQuery執行時所有數據都在本地,不涉及跨DC查詢,因此復雜度降低,不受跨DC網絡影響,并且集群整體的讀寫負載更可控,穩定性更好;
當公共集群故障時,Gateway-Consul-Sync無法正常工作,但綠色的Consul仍然可以返回之前同步好的數據,網關還可以繼續工作;
由于網關在改造前后查詢Consul的接口和數據格式是完全一致的,當圖中綠色Consul集群故障時,可以切回到公共Consul集群,作為一個備用方案。
關于Consul故障分析與優化是怎么樣的問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





