溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Flink與Storm的性能對比”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Flink與Storm的性能對比”吧!
一、背景
Apache Flink 和 Apache Storm 是當前業界廣泛使用的兩個分布式實時計算框架。其中 Apache Storm(以下簡稱“Storm”)在美團點評實時計算業務中已有較為成熟的運用,有管理平臺、常用 API 和相應的文檔,大量實時作業基于 Storm 構建。
Apache Storm參考鏈接:http://storm.apache.org/
而 Apache Flink(以下簡稱“Flink”)在近期倍受關注,具有高吞吐、低延遲、高可靠和精確計算等特性,對事件窗口有很好的支持,目前在美團點評實時計算業務中也已有一定應用。
Apache Flink參考鏈接:https://flink.apache.org/
為深入熟悉了解 Flink 框架,驗證其穩定性和可靠性,評估其實時處理性能,識別該體系中的缺點,找到其性能瓶頸并進行優化,給用戶提供最適合的實時計算引擎,我們以實踐經驗豐富的 Storm 框架作為對照,進行了一系列實驗測試 Flink 框架的性能。
計算 Flink 作為確保“至少一次”和“恰好一次”語義的實時計算框架時對資源的消耗,為實時計算平臺資源規劃、框架選擇、性能調優等決策及 Flink 平臺的建設提出建議并提供數據支持,為后續的 SLA 建設提供一定參考。
Flink 與 Storm 兩個框架對比:

二、測試目標
評估不同場景、不同數據壓力下 Flink 和 Storm 兩個實時計算框架目前的性能表現,獲取其詳細性能數據并找到處理性能的極限;了解不同配置對 Flink 性能影響的程度,分析各種配置的適用場景,從而得出調優建議。
1、測試場景
1)“輸入-輸出”簡單處理場景
通過對“輸入-輸出”這樣簡單處理邏輯場景的測試,盡可能減少其它因素的干擾,反映兩個框架本身的性能。
同時測算框架處理能力的極限,處理更加復雜的邏輯的性能不會比純粹“輸入-輸出”更高。
2)用戶作業耗時較長的場景
如果用戶的處理邏輯較為復雜,或是訪問了數據庫等外部組件,其執行時間會增大,作業的性能會受到影響。因此,我們測試了用戶作業耗時較長的場景下兩個框架的調度性能。
3)窗口統計場景
實時計算中常有對時間窗口或計數窗口進行統計的需求,例如一天中每五分鐘的訪問量,每 100 個訂單中有多少個使用了優惠等。Flink 在窗口支持上的功能比 Storm 更加強大,API 更加完善,但是我們同時也想了解在窗口統計這個常用場景下兩個框架的性能。
4)精確計算場景(即消息投遞語義為“恰好一次”)
Storm 僅能保證“至多一次” (At Most Once) 和“至少一次” (At Least Once) 的消息投遞語義,即可能存在重復發送的情況。
有很多業務場景對數據的精確性要求較高,希望消息投遞不重不漏。Flink 支持“恰好一次” (Exactly Once) 的語義,但是在限定的資源條件下,更加嚴格的精確度要求可能帶來更高的代價,從而影響性能。
因此,我們測試了在不同消息投遞語義下兩個框架的性能,希望為精確計算場景的資源規劃提供數據參考。
2、性能指標
1)吞吐量(Throughput)
單位時間內由計算框架成功地傳送數據的數量,本次測試吞吐量的單位為:條/秒。
反映了系統的負載能力,在相應的資源條件下,單位時間內系統能處理多少數據。
吞吐量常用于資源規劃,同時也用于協助分析系統性能瓶頸,從而進行相應的資源調整以保證系統能達到用戶所要求的處理能力。假設商家每小時能做二十份午餐(吞吐量 20 份/小時),一個外賣小哥每小時只能送兩份(吞吐量 2 份/小時),這個系統的瓶頸就在小哥配送這個環節,可以給該商家安排十個外賣小哥配送。
2)延遲(Latency)
數據從進入系統到流出系統所用的時間,本次測試延遲的單位為:毫秒。
反映了系統處理的實時性。
金融交易分析等大量實時計算業務對延遲有較高要求,延遲越低,數據實時性越強。
假設商家做一份午餐需要 5 分鐘,小哥配送需要 25 分鐘,這個流程中用戶感受到了 30 分鐘的延遲。如果更換配送方案后延遲變成了 60 分鐘,等送到了飯菜都涼了,這個新的方案就是無法接受的。
三、測試環境
為 Storm 和 Flink 分別搭建由 1 臺主節點和 2 臺從節點構成的 Standalone 集群進行本次測試。其中為了觀察 Flink 在實際生產環境中的性能,對于部分測內容也進行了 on Yarn 環境的測試。
1、集群參數

2、框架參數
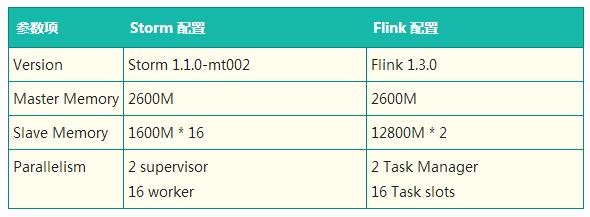
四、測試方法
1、測試流程
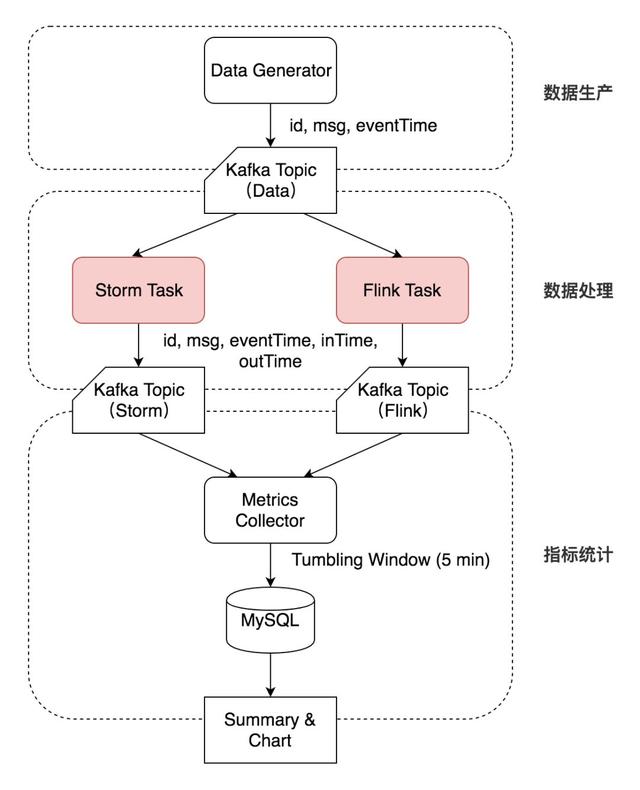
1)數據生產
Data Generator 按特定速率生成數據,帶上自增的 id 和 eventTime 時間戳寫入 Kafka 的一個 Topic(Topic Data)。
2)數據處理
Storm Task 和 Flink Task (每個測試用例不同)從 Kafka Topic Data 相同的 Offset 開始消費,并將結果及相應 inTime、outTime 時間戳分別寫入兩個 Topic(Topic Storm 和 Topic Flink)中。
3)指標統計
Metrics Collector 按 outTime 的時間窗口從這兩個 Topic 中統計測試指標,每五分鐘將相應的指標寫入 MySQL 表中。
Metrics Collector 按 outTime 取五分鐘的滾動時間窗口,計算五分鐘的平均吞吐(輸出數據的條數)、五分鐘內的延遲(outTime - eventTime 或 outTime - inTime)的中位數及 99 線等指標,寫入 MySQL 相應的數據表中。最后對 MySQL 表中的吞吐計算均值,延遲中位數及延遲 99 線選取中位數,繪制圖像并分析。
2、默認參數
Storm 和 Flink 默認均為 At Least Once語義。
Storm 開啟 ACK,ACKer 數量為 1。
Flink 的 Checkpoint 時間間隔為 30 秒,默認 StateBackend 為 Memory。
保證 Kafka 不是性能瓶頸,盡可能排除 Kafka 對測試結果的影響。
測試延遲時數據生產速率小于數據處理能力,假設數據被寫入 Kafka 后立刻被讀取,即 eventTime 等于數據進入系統的時間。
測試吞吐量時從 Kafka Topic 的最舊開始讀取,假設該 Topic 中的測試數據量充足。
3、測試用例
1)Identity
Identity 用例主要模擬“輸入-輸出”簡單處理場景,反映兩個框架本身的性能。
輸入數據為“msgId, eventTime”,其中 eventTime 視為數據生成時間。單條輸入數據約 20 B。
進入作業處理流程時記錄 inTime,作業處理完成后(準備輸出時)記錄 outTime。
作業從 Kafka Topic Data 中讀取數據后,在字符串末尾追加時間戳,然后直接輸出到 Kafka。
輸出數據為“msgId, eventTime, inTime, outTime”。單條輸出數據約 50 B。
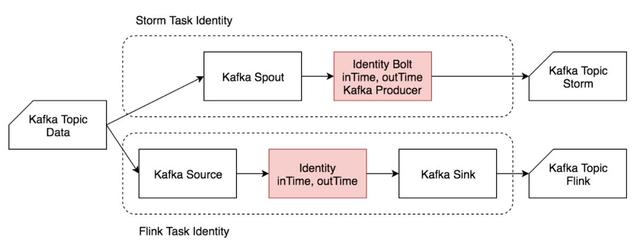
Identity 流程圖
2)Sleep
Sleep 用例主要模擬用戶作業耗時較長的場景,反映復雜用戶邏輯對框架差異的削弱,比較兩個框架的調度性能。
輸入數據和輸出數據均與 Identity 相同。
讀入數據后,等待一定時長(1 ms)后在字符串末尾追加時間戳后輸出。
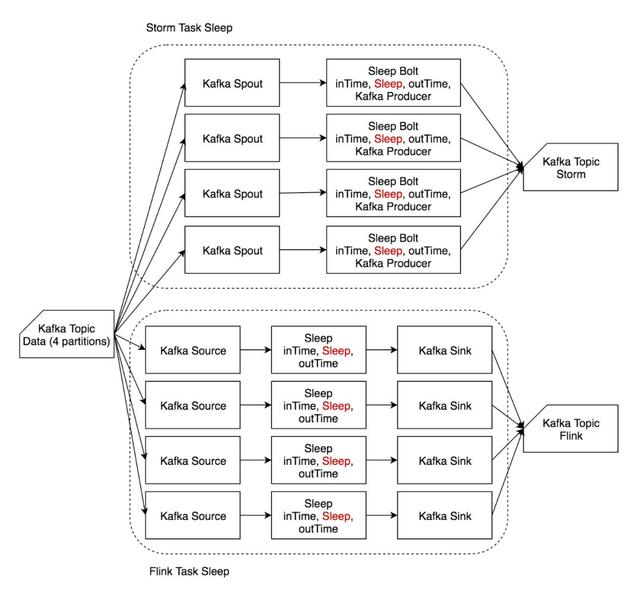
Sleep 流程圖
3)Windowed Word Count
Windowed Word Count 用例主要模擬窗口統計場景,反映兩個框架在進行窗口統計時性能的差異。
此外,還用其進行了精確計算場景的測試,反映 Flink 恰好一次投遞的性能。
輸入為 JSON 格式,包含 msgId、eventTime 和一個由若干單詞組成的句子,單詞之間由空格分隔。單條輸入數據約 150 B。
讀入數據后解析 JSON,然后將句子分割為相應單詞,帶 eventTime 和 inTime 時間戳發給 CountWindow 進行單詞計數,同時記錄一個窗口中最大最小的 eventTime 和 inTime,最后帶 outTime 時間戳輸出到 Kafka 相應的 Topic。
Spout/Source 及 OutputBolt/Output/Sink 并發度恒為 1,增大并發度時僅增大 JSONParser、CountWindow 的并發度。
由于 Storm 對 window 的支持較弱,CountWindow 使用一個 HashMap 手動實現,Flink 用了原生的 CountWindow 和相應的 Reduce 函數。
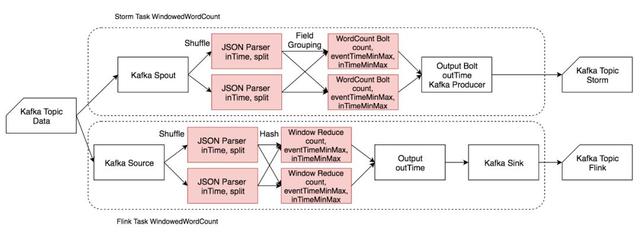
Windowed Word Count 流程圖
五、測試結果
① Identity 單線程吞吐量
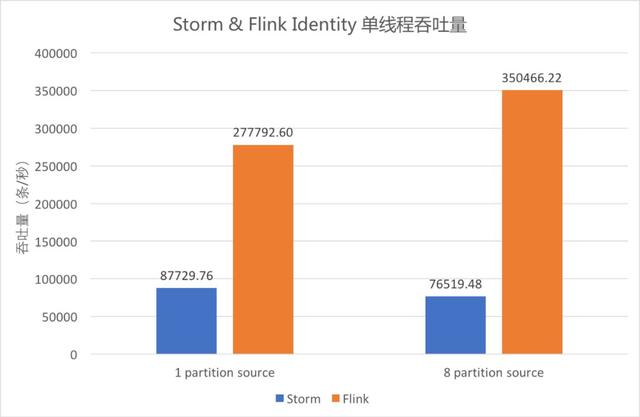
Identity 單線程吞吐量
上圖中藍色柱形為單線程 Storm 作業的吞吐,橙色柱形為單線程 Flink 作業的吞吐。
Identity 邏輯下,Storm 單線程吞吐為 8.7萬條/秒,Flink 單線程吞吐可達35萬條/秒。
當 Kafka Data 的 Partition 數為 1 時,Flink 的吞吐約為 Storm 的 3.2 倍;當其 Partition 數為 8 時,Flink 的吞吐約為 Storm 的 4.6 倍。
由此可以看出,Flink 吞吐約為 Storm 的 3-5 倍。
② Identity 單線程作業延遲

Identity 單線程作業延遲
采用 outTime - eventTime 作為延遲,圖中藍色折線為 Storm,橙色折線為 Flink。虛線為 99 線,實線為中位數。
從圖中可以看出隨著數據量逐漸增大,Identity 的延遲逐漸增大。其中 99 線的增大速度比中位數快,Storm 的 增大速度比 Flink 快。
其中 QPS 在 80000 以上的測試數據超過了 Storm 單線程的吞吐能力,無法對 Storm 進行測試,只有 Flink 的曲線。
對比折線最右端的數據可以看出,Storm QPS 接近吞吐時延遲中位數約 100 毫秒,99 線約 700 毫秒,Flink 中位數約 50 毫秒,99 線約 300 毫秒。Flink 在滿吞吐時的延遲約為 Storm 的一半。
③ Sleep吞吐量
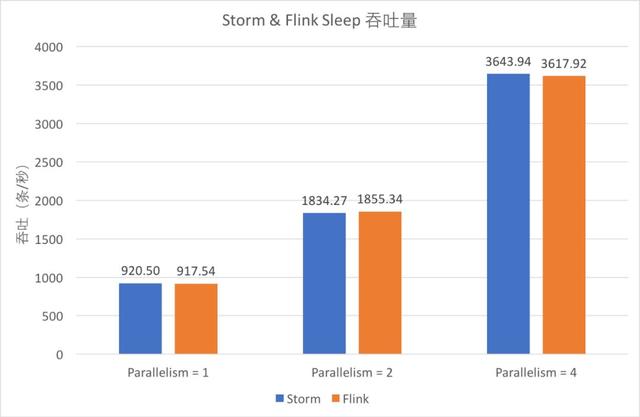
Sleep 吞吐量
從圖中可以看出,Sleep 1 毫秒時,Storm 和 Flink 單線程的吞吐均在 900 條/秒左右,且隨著并發增大基本呈線性增大。
對比藍色和橙色的柱形可以發現,此時兩個框架的吞吐能力基本一致。
④ Sleep 單線程作業延遲(中位數)
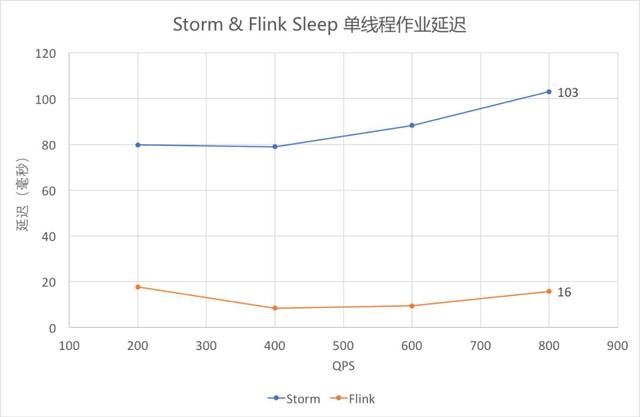
Sleep 單線程作業延遲(中位數)
依然采用 outTime - eventTime 作為延遲,從圖中可以看出,Sleep 1 毫秒時,Flink 的延遲仍低于 Storm。
⑤ Windowed Word Count 單線程吞吐量
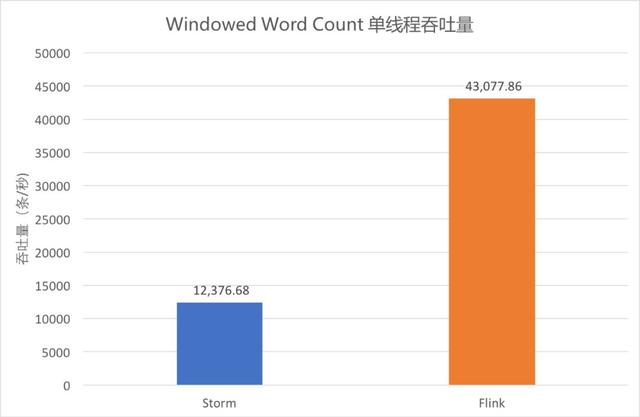
Windowed Word Count 單線程吞吐量
單線程執行大小為 10 的計數窗口,吞吐量統計如圖。
從圖中可以看出,Storm 吞吐約為 1.2 萬條/秒,Flink Standalone 約為 4.3 萬條/秒。Flink 吞吐依然為 Storm 的 3 倍以上。
⑥ Windowed Word Count Flink At Least Once 與 Exactly Once 吞吐量對比
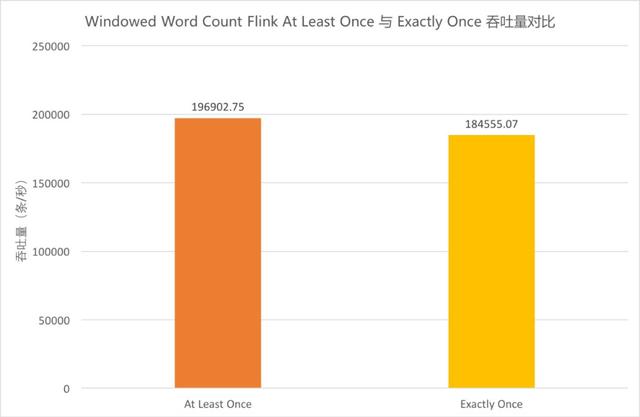
Windowed Word Count Flink At Least Once 與 Exactly Once 吞吐量對比
由于同一算子的多個并行任務處理速度可能不同,在上游算子中不同快照里的內容,經過中間并行算子的處理,到達下游算子時可能被計入同一個快照中。這樣一來,這部分數據會被重復處理。因此,Flink 在 Exactly Once 語義下需要進行對齊,即當前最早的快照中所有數據處理完之前,屬于下一個快照的數據不進行處理,而是在緩存區等待。當前測試用例中,在 JSON Parser 和 CountWindow、CountWindow 和 Output 之間均需要進行對齊,有一定消耗。為體現出對齊場景,Source/Output/Sink 并發度的并發度仍為 1,提高了 JSONParser/CountWindow 的并發度。具體流程細節參見前文 Windowed Word Count 流程圖。
上圖中橙色柱形為 At Least Once 的吞吐量,黃色柱形為 Exactly Once 的吞吐量。對比兩者可以看出,在當前并發條件下,Exactly Once 的吞吐較 At Least Once 而言下降了 6.3%。
⑦ Windowed Word Count Storm At Least Once 與 At Most Once 吞吐量對比
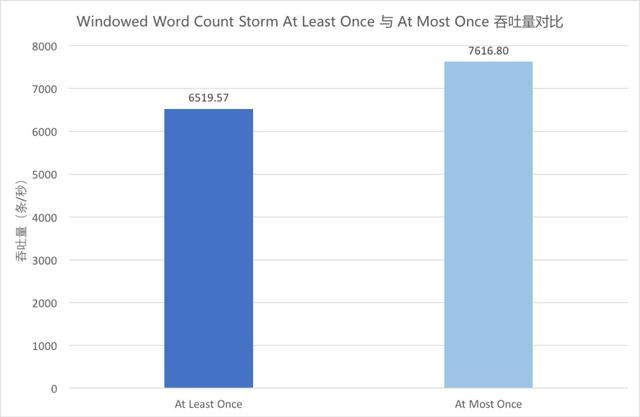
Windowed Word Count Storm At Least Once 與 At Most Once 吞吐量對比
Storm 將 ACKer 數量設置為零后,每條消息在發送時就自動 ACK,不再等待 Bolt 的 ACK,也不再重發消息,為 At Most Once 語義。
上圖中藍色柱形為 At Least Once 的吞吐量,淺藍色柱形為 At Most Once 的吞吐量。對比兩者可以看出,在當前并發條件下,At Most Once 語義下的吞吐較 At Least Once 而言提高了 16.8%。
⑧ Windowed Word Count 單線程作業延遲
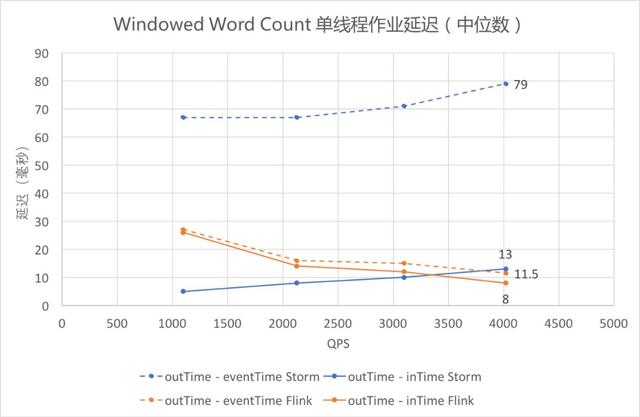
Windowed Word Count 單線程作業延遲
Identity 和 Sleep 觀測的都是 outTime - eventTime,因為作業處理時間較短或 Thread.sleep 精度不高,outTime - inTime 為零或沒有比較意義;Windowed Word Count 中可以有效測得 outTime - inTime 的數值,將其與 outTime - eventTime 畫在同一張圖上,其中 outTime - eventTime 為虛線,outTime - InTime 為實線。
觀察橙色的兩條折線可以發現,Flink 用兩種方式統計的延遲都維持在較低水平;觀察兩條藍色的曲線可以發現,Storm 的 outTime - inTime 較低,outTime - eventTime 一直較高,即 inTime 和 eventTime 之間的差值一直較大,可能與 Storm 和 Flink 的數據讀入方式有關。
藍色折線表明 Storm 的延遲隨數據量的增大而增大,而橙色折線表明 Flink 的延遲隨著數據量的增大而減小(此處未測至 Flink 吞吐量,接近吞吐時 Flink 延遲依然會上升)。
即使僅關注 outTime - inTime(即圖中實線部分),依然可以發現,當 QPS 逐漸增大的時候,Flink 在延遲上的優勢開始體現出來。
⑨ Windowed Word Count Flink At Least Once 與 Exactly Once 延遲對比
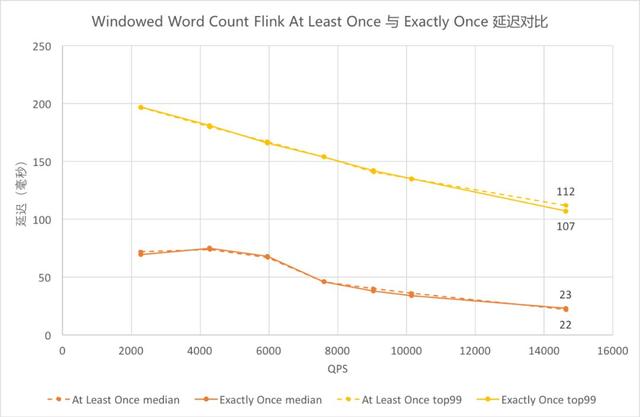
Windowed Word Count Flink At Least Once 與 Exactly Once 延遲對比
圖中黃色為 99 線,橙色為中位數,虛線為 At Least Once,實線為 Exactly Once。圖中相應顏色的虛實曲線都基本重合,可以看出 Flink Exactly Once 的延遲中位數曲線與 At Least Once 基本貼合,在延遲上性能沒有太大差異。
⑩ Windowed Word Count Storm At Least Once 與 At Most Once 延遲對比
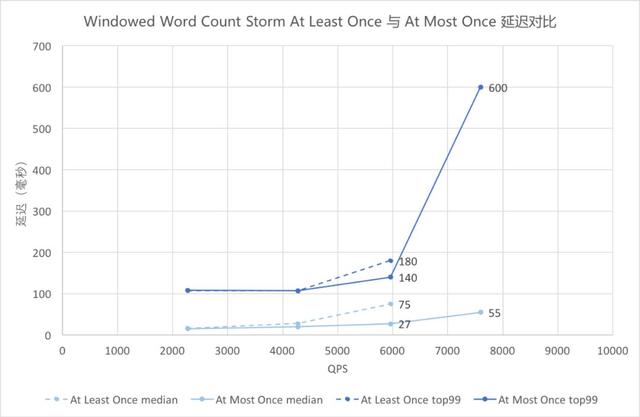
Windowed Word Count Storm At Least Once 與 At Most Once 延遲對比
圖中藍色為 99 線,淺藍色為中位數,虛線為 At Least Once,實線為 At Most Once。QPS 在 4000 及以前的時候,虛線實線基本重合;QPS 在 6000 時兩者已有差異,虛線略高;QPS 接近 8000 時,已超過 At Least Once 語義下 Storm 的吞吐,因此只有實線上的點。
可以看出,QPS 較低時 Storm At Most Once 與 At Least Once 的延遲觀察不到差異,隨著 QPS 增大差異開始增大,At Most Once 的延遲較低。
?Windowed Word Count Flink 不同 StateBackends 吞吐量對比
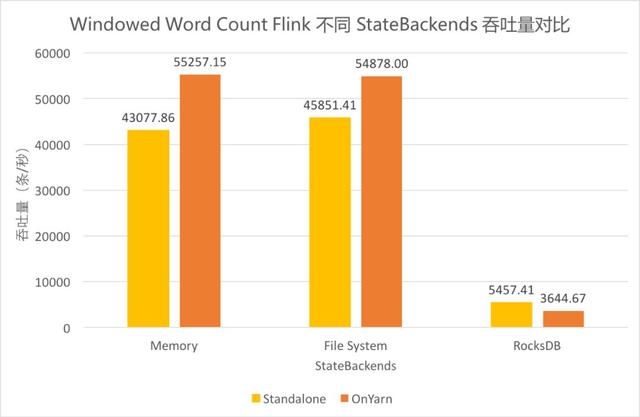
Windowed Word Count Flink 不同 StateBackends 吞吐量對比
Flink 支持 Standalone 和 on Yarn 的集群部署模式,同時支持 Memory、FileSystem、RocksDB 三種狀態存儲后端(StateBackends)。由于線上作業需要,測試了這三種 StateBackends 在兩種集群部署模式上的性能差異。其中,Standalone 時的存儲路徑為 JobManager 上的一個文件目錄,on Yarn 時存儲路徑為 HDFS 上一個文件目錄。
對比三組柱形可以發現,使用 FileSystem 和 Memory 的吞吐差異不大,使用 RocksDB 的吞吐僅其余兩者的十分之一左右。
對比兩種顏色可以發現,Standalone 和 on Yarn 的總體差異不大,使用 FileSystem 和 Memory 時 on Yarn 模式下吞吐稍高,使用 RocksDB 時 Standalone 模式下的吞吐稍高。
?Windowed Word Count Flink 不同 StateBackends 延遲對比
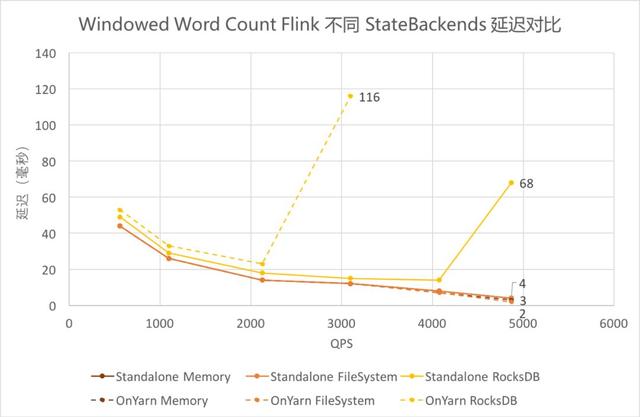
Windowed Word Count Flink 不同 StateBackends 延遲對
使用 FileSystem 和 Memory 作為 Backends 時,延遲基本一致且較低。
使用 RocksDB 作為 Backends 時,延遲稍高,且由于吞吐較低,在達到吞吐瓶頸前的延遲陡增。其中 on Yarn 模式下吞吐更低,接近吞吐時的延遲更高。
六、結論及建議
1、框架本身性能
由①、⑤的測試結果可以看出,Storm 單線程吞吐約為 8.7 萬條/秒,Flink 單線程吞吐可達 35 萬條/秒。Flink 吞吐約為 Storm 的 3-5 倍。
由②、⑧的測試結果可以看出,Storm QPS 接近吞吐時延遲(含 Kafka 讀寫時間)中位數約 100 毫秒,99 線約 700 毫秒,Flink 中位數約 50 毫秒,99 線約 300 毫秒。Flink 在滿吞吐時的延遲約為 Storm 的一半,且隨著 QPS 逐漸增大,Flink 在延遲上的優勢開始體現出來。
綜上可得,Flink 框架本身性能優于 Storm。
2、復雜用戶邏輯對框架差異的削弱
對比①和③、②和④的測試結果可以發現,單個 Bolt Sleep 時長達到 1 毫秒時,Flink 的延遲仍低于 Storm,但吞吐優勢已基本無法體現。
因此,用戶邏輯越復雜,本身耗時越長,針對該邏輯的測試體現出來的框架的差異越小。
3、不同消息投遞語義的差異
由⑥、⑦、⑨、⑩的測試結果可以看出,Flink Exactly Once 的吞吐較 At Least Once 而言下降 6.3%,延遲差異不大;Storm At Most Once 語義下的吞吐較 At Least Once 提升 16.8%,延遲稍有下降。
由于 Storm 會對每條消息進行 ACK,Flink 是基于一批消息做的檢查點,不同的實現原理導致兩者在 At Least Once 語義的花費差異較大,從而影響了性能。而 Flink 實現 Exactly Once 語義僅增加了對齊操作,因此在算子并發量不大、沒有出現慢節點的情況下對 Flink 性能的影響不大。Storm At Most Once 語義下的性能仍然低于 Flink。
4、Flink 狀態存儲后端選擇
Flink 提供了內存、文件系統、RocksDB 三種 StateBackends,結合?、?的測試結果,三者的對比如下:
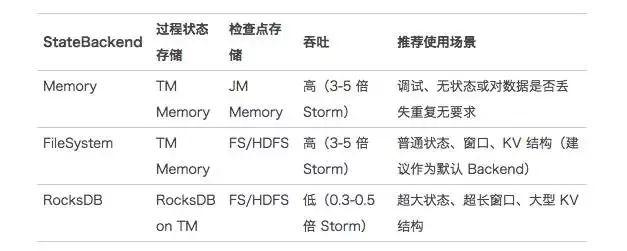
5、推薦使用 Flink 的場景
綜合上述測試結果,以下實時計算場景建議考慮使用 Flink 框架進行計算:
要求消息投遞語義為 Exactly Once的場景;
數據量較大,要求高吞吐低延遲的場景;
需要進行狀態管理或窗口統計的場景。
七、展望
本次測試中尚有一些內容沒有進行更加深入的測試,有待后續測試補充。例如:
Exactly Once 在并發量增大的時候是否吞吐會明顯下降?
用戶耗時到 1ms 時框架的差異已經不再明顯(Thread.sleep() 的精度只能到毫秒),用戶耗時在什么范圍內 Flink 的優勢依然能體現出來?
到此,相信大家對“Flink與Storm的性能對比”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





