溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“有哪些高可用Prometheus架構實踐中的坑”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
幾點原則
監控是基礎設施,目的是為了解決問題,不要只朝著大而全去做,尤其是不必要的指標采集,浪費人力和存儲資源(To B商業產品例外)。
需要處理的告警才發出來,發出來的告警必須得到處理。
簡單的架構就是最好的架構,業務系統都掛了,監控也不能掛。Google SRE 里面也說避免使用 Magic 系統,例如機器學習報警閾值、自動修復之類。這一點見仁見智吧,感覺很多公司都在搞智能 AI 運維。
Prometheus 的局限
Prometheus 是基于 Metric 的監控,不適用于日志(Logs)、事件(Event)、調用鏈(Tracing)。
Prometheus 默認是 Pull 模型,合理規劃你的網絡,盡量不要轉發。
對于集群化和水平擴展,官方和社區都沒有銀彈,需要合理選擇 Federate、Cortex、Thanos 等方案。
監控系統一般情況下可用性大于一致性,容忍部分副本數據丟失,保證查詢請求成功。這個后面說 Thanos 去重的時候會提到。
Prometheus 不一定保證數據準確,這里的不準確一是指 rate、histogram_quantile 等函數會做統計和推斷,產生一些反直覺的結果,這個后面會詳細展開。二來查詢范圍過長要做降采樣,勢必會造成數據精度丟失,不過這是時序數據的特點,也是不同于日志系統的地方。
Kubernetes 集群中常用的 Exporter
Prometheus 屬于 CNCF 項目,擁有完整的開源生態,與 Zabbix 這種傳統 Agent 監控不同,它提供了豐富的 Exporter 來滿足你的各種需求。你可以在這里[2]看到官方、非官方的 Exporter。如果還是沒滿足你的需求,你還可以自己編寫 Exporter,簡單方便、自由開放,這是優點。
但是過于開放就會帶來選型、試錯成本。之前只需要在 Zabbix Agent 里面幾行配置就能完成的事,現在你會需要很多 Exporter 搭配才能完成。還要對所有 Exporter 維護、監控。尤其是升級 Exporter 版本時,很痛苦。非官方 Exporter 還會有不少 bug。這是使用上的不足,當然也是 Prometheus 的設計原則。
Kubernetes 生態的組件都會提供 /metric 接口以提供自監控,這里列下我們正在使用的:
cAdvisor:集成在 Kubelet 中。
kubelet:10255 為非認證端口,10250 為認證端口。
apiserver:6443 端口,關心請求數、延遲等。
scheduler:10251 端口。
controller-manager:10252 端口。
etcd:如 etcd 寫入讀取延遲、存儲容量等。
Docker:需要開啟 experimental 實驗特性,配置 metrics-addr,如容器創建耗時等指標。
kube-proxy:默認 127 暴露,10249 端口。外部采集時可以修改為 0.0.0.0 監聽,會暴露:寫入 iptables 規則的耗時等指標。
kube-state-metrics:Kubernetes 官方項目,采集 Pod、Deployment 等資源的元信息。
node-exporter:Prometheus 官方項目,采集機器指標如 CPU、內存、磁盤。
blackbox_exporter:Prometheus 官方項目,網絡探測,DNS、ping、http 監控。
process-exporter:采集進程指標。
NVIDIA Exporter:我們有 GPU 任務,需要 GPU 數據監控。
node-problem-detector:即 NPD,準確的說不是 Exporter,但也會監測機器狀態,上報節點異常打 taint。
應用層 Exporter:MySQL、Nginx、MQ 等,看業務需求。
還有各種場景下的自定義 Exporter,如日志提取,后面會再做介紹。
Kubernetes 核心組件監控與 Grafana 面板
Kubernetes 集群運行中需要關注核心組件的狀態、性能。如 kubelet、apiserver 等,基于上面提到的 Exporter 的指標,可以在 Grafana 中繪制如下圖表:
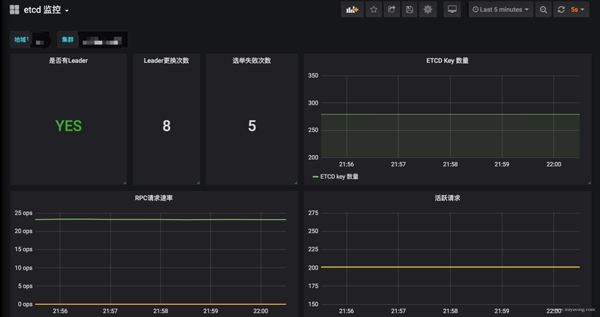
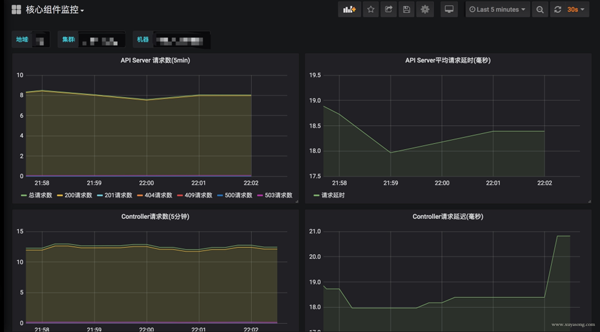
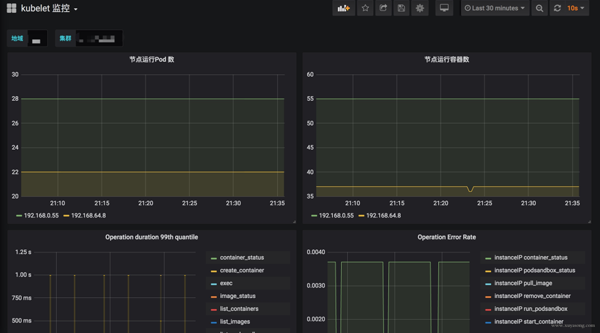
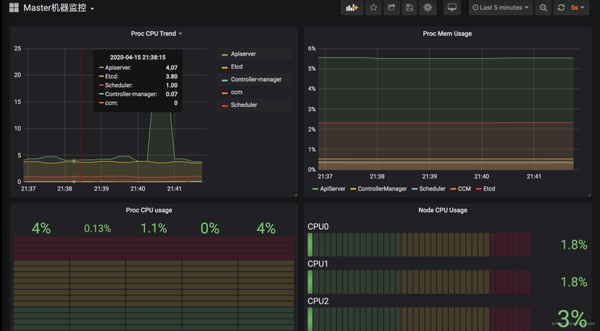
模板可以參考Grafana Dashboards for Kubernetes Administrators[3],根據運行情況不斷調整報警閾值。
這里提一下 Grafana 雖然支持了 templates 能力,可以很方便地做多級下拉框選擇,但是不支持templates 模式下配置報警規則,相關 issue[4]。
官方對這個功能解釋了一堆,可最新版本仍然沒有支持。借用 issue 的一句話吐槽下:
It would be grate to add templates support in alerts. Otherwise the feature looks useless a bit.
關于 Grafana 的基礎用法,可以看這個文章[5]。
采集組件 All in One
Prometheus 體系中 Exporter 都是獨立的,每個組件各司其職,如機器資源用 Node-Exporter,GPU 有Nvidia Exporter等等。但是 Exporter 越多,運維壓力越大,尤其是對 Agent 做資源控制、版本升級。我們嘗試對一些 Exporter 進行組合,方案有二:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
通過主進程拉起 N 個 Exporter 進程,仍然可以跟著社區版本做更新、bug fix。
用Telegraf來支持各種類型的 Input,N 合 1。
另外,Node-Exporter 不支持進程監控,可以加一個 Process-Exporter,也可以用上邊提到的 Telegraf,使用 procstat 的 input 來采集進程指標。
合理選擇黃金指標
采集的指標有很多,我們應該關注哪些?Google 在“SRE Handbook”中提出了“四個黃金信號”:延遲、流量、錯誤數、飽和度。實際操作中可以使用 Use 或 Red 方法作為指導,Use 用于資源,Red 用于服務。
Use 方法:Utilization、Saturation、Errors。如 Cadvisor 數據
Red 方法:Rate、Errors、Duration。如 Apiserver 性能指標
Prometheus 采集中常見的服務分三種:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
在線服務:如 Web 服務、數據庫等,一般關心請求速率,延遲和錯誤率即 RED 方法
離線服務:如日志處理、消息隊列等,一般關注隊列數量、進行中的數量,處理速度以及發生的錯誤即 Use 方法
批處理任務:和離線任務很像,但是離線任務是長期運行的,批處理任務是按計劃運行的,如持續集成就是批處理任務,對應 Kubernetes 中的 Job 或 CronJob, 一般關注所花的時間、錯誤數等,因為運行周期短,很可能還沒采集到就運行結束了,所以一般使用 Pushgateway,改拉為推。
對 Use 和 Red 的實際示例可以參考《容器監控實踐——Kubernetes 常用指標分析[6]》這篇文章。
Kubernetes 1.16 中 cAdvisor 的指標兼容問題
在 Kubernetes 1.16版本,cAdvisor 的指標去掉了 pod_Name 和 container_name 的 label,替換為了 Pod 和 Container。如果你之前用這兩個 label 做查詢或者 Grafana 繪圖,需要更改下 SQL 了。因為我們一直支持多個 Kubernetes 版本,就通過 relabel 配置繼續保留了原來的**_name。
metric_relabel_configs: - source_labels: [container] regex: (.+) target_label: container_name replacement: $1 action: replace - source_labels: [pod] regex: (.+) target_label: pod_name replacement: $1 action: replace
注意要用 metric_relabel_configs,不是 relabel_configs,采集后做的 replace。
Prometheus 采集外部 Kubernetes 集群、多集群
Prometheus 如果部署在 Kubernetes 集群內采集是很方便的,用官方給的 Yaml 就可以,但我們因為權限和網絡需要部署在集群外,二進制運行,采集多個 Kubernetes 集群。
以 Pod 方式運行在集群內是不需要證書的(In-Cluster 模式),但集群外需要聲明 token 之類的證書,并替換 __address__,即使用 Apiserver Proxy 采集,以 cAdvisor 采集為例,Job 配置為:
- job_name: cluster-cadvisor honor_timestamps: true scrape_interval: 30s scrape_timeout: 10s metrics_path: /metrics scheme: https kubernetes_sd_configs: - api_server: https://xx:6443 role: node bearer_token_file: token/cluster.token tls_config: insecure_skip_verify: true bearer_token_file: token/cluster.token tls_config: insecure_skip_verify: true relabel_configs: - separator: ; regex: __meta_kubernetes_node_label_(.+) replacement: $1 action: labelmap - separator: ; regex: (.*) target_label: __address__ replacement: xx:6443 action: replace - source_labels: [__meta_kubernetes_node_name] separator: ; regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor action: replace metric_relabel_configs: - source_labels: [container] separator: ; regex: (.+) target_label: container_name replacement: $1 action: replace - source_labels: [pod] separator: ; regex: (.+) target_label: pod_name replacement: $1 action: replacebearer_token_file 需要提前生成,這個參考官方文檔即可。記得 base64 解碼。
對于 cAdvisor 來說,__metrics_path__ 可以轉換為 /api/v1/nodes/${1}/proxy/metrics/cadvisor,代表 Apiserver proxy 到 Kubelet。
如果網絡能通,其實也可以直接把 Kubelet 的 10255 作為 target,可以直接寫為:${1}:10255/metrics/cadvisor,代表直接請求 Kubelet,規模大的時候還減輕了 Apiserver 的壓力,即服務發現使用 Apiserver,采集不走 Apiserver。
因為 cAdvisor 是暴露主機端口,配置相對簡單,如果是 kube-state-metric 這種 Deployment,以 Endpoint 形式暴露,寫法應該是:
- job_name: cluster-service-endpoints honor_timestamps: true scrape_interval: 30s scrape_timeout: 10s metrics_path: /metrics scheme: https kubernetes_sd_configs: - api_server: https://xxx:6443 role: endpoints bearer_token_file: token/cluster.token tls_config: insecure_skip_verify: true bearer_token_file: token/cluster.token tls_config: insecure_skip_verify: true relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] separator: ; regex: (https?) target_label: __scheme__ replacement: $1 action: replace - separator: ; regex: (.*) target_label: __address__ replacement: xxx:6443 action: replace - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_service_annotation_prometheus_io_port] separator: ; regex: (.+);(.+);(.*) target_label: __metrics_path__ replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics action: replace - separator: ; regex: __meta_kubernetes_service_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: kubernetes_namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_name] separator: ; regex: (.*) target_label: kubernetes_name replacement: $1 action: replace對于 Endpoint 類型,需要轉換 __metrics_path__ 為 /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics,需要替換 namespace、svc 名稱端口等。
這里的寫法只適合接口為 /metrics 的 exporter,如果你的 exporter 不是 /metrics 接口,需要替換這個路徑。或者像我們一樣統一約束都使用這個地址。
這里的 __meta_kubernetes_service_annotation_prometheus_io_port 來源就是 exporter 部署時寫的那個 annotation,大多數文章中只提到 prometheus.io/scrape: 'true',但也可以定義端口、路徑、協議。以方便在采集時做替換處理。
其他的一些 relabel 如 kubernetes_namespace 是為了保留原始信息,方便做 PromQL 查詢時的篩選條件。
如果是多集群,同樣的配置多寫幾遍就可以了,一般一個集群可以配置三類 Job:
role:node 的,包括 cAdvisor、 node-exporter、kubelet 的 summary、kube-proxy、Docker 等指標
role:endpoint 的,包括 kube-state-metric 以及其他自定義 Exporter
普通采集:包括 etcd、Apiserver 性能指標、進程指標等。
GPU 指標的獲取
nvidia-smi 可以查看機器上的 GPU 資源,而 cAdvisor 其實暴露了 Metric 來表示容器使用 GPU 情況。
container_accelerator_duty_cycle container_accelerator_memory_total_bytes container_accelerator_memory_used_bytes
如果要更詳細的 GPU 數據,可以安裝 dcgm exporter,不過 Kubernetes 1.13 才能支持。
更改 Prometheus 的顯示時區
Prometheus 為避免時區混亂,在所有組件中專門使用 Unix Time 和 Utc 進行顯示。不支持在配置文件中設置時區,也不能讀取本機 /etc/timezone 時區。
其實這個限制是不影響使用的:
如果做可視化,Grafana 是可以做時區轉換的。
如果是調接口,拿到了數據中的時間戳,你想怎么處理都可以。
如果因為 Prometheus 自帶的 UI 不是本地時間,看著不舒服,2.16 版本的新版 Web UI已經引入了 Local Timezone 的選項,區別見下圖。
如果你仍然想改 Prometheus 代碼來適應自己的時區,可以參考這篇文章[7]。
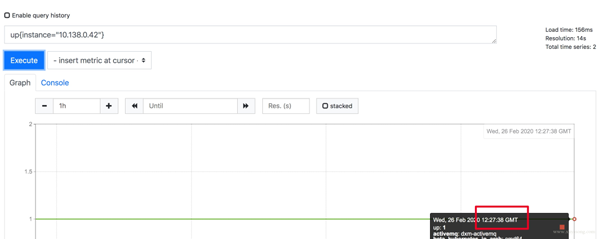
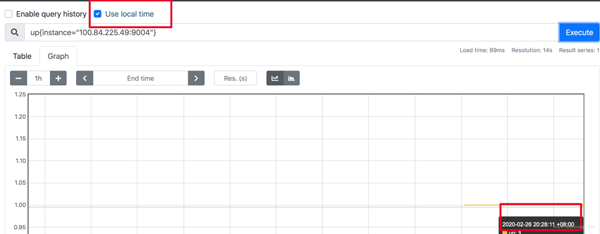
關于 timezone 的討論,可以看這個 issue[8]。
如何采集 LB 后面的 RS 的 Metric
假如你有一個負載均衡 LB,但網絡上 Prometheus 只能訪問到 LB 本身,訪問不到后面的 RS,應該如何采集 RS 暴露的 Metric?
RS 的服務加 Sidecar Proxy,或者本機增加 Proxy 組件,保證 Prometheus 能訪問到。
LB 增加 /backend1 和 /backend2請求轉發到兩個單獨的后端,再由 Prometheus 訪問 LB 采集。
版本的選擇
Prometheus 當前最新版本為 2.16,Prometheus 還在不斷迭代,因此盡量用最新版,1.X版本就不用考慮了。
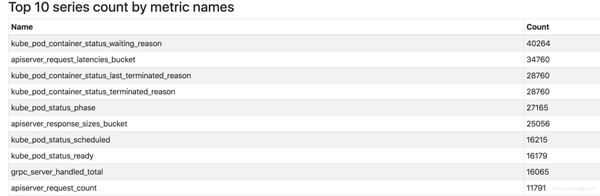
2.16 版本上有一套實驗 UI,可以查看 TSDB 的狀態,包括Top 10的 Label、Metric。
Prometheus 大內存問題
隨著規模變大,Prometheus 需要的 CPU 和內存都會升高,內存一般先達到瓶頸,這個時候要么加內存,要么集群分片減少單機指標。這里我們先討論單機版 Prometheus 的內存問題。
原因:
Prometheus 的內存消耗主要是因為每隔 2 小時做一個 Block 數據落盤,落盤之前所有數據都在內存里面,因此和采集量有關。
加載歷史數據時,是從磁盤到內存的,查詢范圍越大,內存越大。這里面有一定的優化空間。
一些不合理的查詢條件也會加大內存,如 Group 或大范圍 Rate。
我的指標需要多少內存:
作者給了一個計算器,設置指標量、采集間隔之類的,計算 Prometheus 需要的理論內存值:計算公式[9]。
以我們的一個 Prometheus Server 為例,本地只保留 2 小時數據,95 萬 Series,大概占用的內存如下:


有什么優化方案:
Sample 數量超過了 200 萬,就不要單實例了,做下分片,然后通過 Victoriametrics,Thanos,Trickster 等方案合并數據。
評估哪些 Metric 和 Label 占用較多,去掉沒用的指標。2.14 以上可以看 TSDB 狀態
查詢時盡量避免大范圍查詢,注意時間范圍和 Step 的比例,慎用 Group。
如果需要關聯查詢,先想想能不能通過 Relabel 的方式給原始數據多加個 Label,一條 SQL 能查出來的何必用 Join,時序數據庫不是關系數據庫。
Prometheus 內存占用分析:
通過 pprof 分析:https://www.robustperception.io/optimising-prometheus-2-6-0-memory-usage-with-pprof
1.X 版本的內存:https://www.robustperception.io/how-much-ram-does-my-prometheus-need-for-ingestion
相關 issue:
https://groups.google.com/forum/#!searchin/prometheus-users/memory%7Csort:date/prometheus-users/q4oiVGU6Bxo/uifpXVw3CwAJ
https://github.com/prometheus/prometheus/issues/5723
https://github.com/prometheus/prometheus/issues/1881
Prometheus 容量規劃
容量規劃除了上邊說的內存,還有磁盤存儲規劃,這和你的 Prometheus 的架構方案有關。
如果是單機 Prometheus,計算本地磁盤使用量。
如果是 Remote-Write,和已有的 TSDB 共用即可。
如果是 Thanos 方案,本地磁盤可以忽略(2H),計算對象存儲的大小就行。
Prometheus 每 2 小時將已緩沖在內存中的數據壓縮到磁盤上的塊中。包括Chunks、Indexes、Tombstones、Metadata,這些占用了一部分存儲空間。一般情況下,Prometheus 中存儲的每一個樣本大概占用 1-2 字節大小(1.7Byte)。可以通過 PromQL 來查看每個樣本平均占用多少空間:
rate(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h]) rate(prometheus_tsdb_compaction_chunk_samples_sum[1h]) instance="0.0.0.0:8890", job="prometheus"} 1.252747585939941
如果大致估算本地磁盤大小,可以通過以下公式:
磁盤大小 = 保留時間 * 每秒獲取樣本數 * 樣本大小
保留時間(retention_time_seconds)和樣本大小(bytes_per_sample)不變的情況下,如果想減少本地磁盤的容量需求,只能通過減少每秒獲取樣本數(ingested_samples_per_second)的方式。
查看當前每秒獲取的樣本數:
rate(prometheus_tsdb_head_samples_appended_total[1h])
有兩種手段,一是減少時間序列的數量,二是增加采集樣本的時間間隔。考慮到 Prometheus 會對時間序列進行壓縮,因此減少時間序列的數量效果更明顯。
舉例說明:
采集頻率 30s,機器數量 1000,Metric 種類 6000,1000600026024 約 200 億,30G 左右磁盤。
只采集需要的指標,如 match[], 或者統計下最常使用的指標,性能最差的指標。
以上磁盤容量并沒有把 wal 文件算進去,wal 文件(Raw Data)在 Prometheus 官方文檔中說明至少會保存 3 個 Write-Ahead Log Files,每一個最大為 128M(實際運行發現數量會更多)。
因為我們使用了 Thanos 的方案,所以本地磁盤只保留 2H 熱數據。Wal 每 2 小時生成一份 Block 文件,Block 文件每 2 小時上傳對象存儲,本地磁盤基本沒有壓力。
關于 Prometheus 存儲機制,可以看這篇[10]。
對 Apiserver 的性能影響
如果你的 Prometheus 使用了 kubernetes_sd_config 做服務發現,請求一般會經過集群的 Apiserver,隨著規模的變大,需要評估下對 Apiserver 性能的影響,尤其是 Proxy 失敗的時候,會導致 CPU 升高。當然了,如果單 Kubernetes 集群規模太大,一般都是拆分集群,不過隨時監測下 Apiserver 的進程變化還是有必要的。
在監控 cAdvisor、Docker、Kube-Proxy 的 Metric 時,我們一開始選擇從 Apiserver Proxy 到節點的對應端口,統一設置比較方便,但后來還是改為了直接拉取節點,Apiserver 僅做服務發現。
Rate 的計算邏輯
Prometheus 中的 Counter 類型主要是為了 Rate 而存在的,即計算速率,單純的 Counter 計數意義不大,因為 Counter 一旦重置,總計數就沒有意義了。
Rate 會自動處理 Counter 重置的問題,Counter 一般都是一直變大的,例如一個 Exporter 啟動,然后崩潰了。本來以每秒大約 10 的速率遞增,但僅運行了半個小時,則速率(x_total [1h])將返回大約每秒 5 的結果。另外,Counter 的任何減少也會被視為 Counter 重置。例如,如果時間序列的值為[5,10,4,6],則將其視為[5,10,14,16]。
Rate 值很少是精確的。由于針對不同目標的抓取發生在不同的時間,因此隨著時間的流逝會發生抖動,query_range 計算時很少會與抓取時間完美匹配,并且抓取有可能失敗。面對這樣的挑戰,Rate 的設計必須是健壯的。
Rate 并非想要捕獲每個增量,因為有時候增量會丟失,例如實例在抓取間隔中掛掉。如果 Counter 的變化速度很慢,例如每小時僅增加幾次,則可能會導致【假象】。比如出現一個 Counter 時間序列,值為 100,Rate 就不知道這些增量是現在的值,還是目標已經運行了好幾年并且才剛剛開始返回。
建議將 Rate 計算的范圍向量的時間至少設為抓取間隔的四倍。這將確保即使抓取速度緩慢,且發生了一次抓取故障,您也始終可以使用兩個樣本。此類問題在實踐中經常出現,因此保持這種彈性非常重要。例如,對于 1 分鐘的抓取間隔,您可以使用 4 分鐘的 Rate 計算,但是通常將其四舍五入為 5 分鐘。
如果 Rate 的時間區間內有數據缺失,他會基于趨勢進行推測,比如:
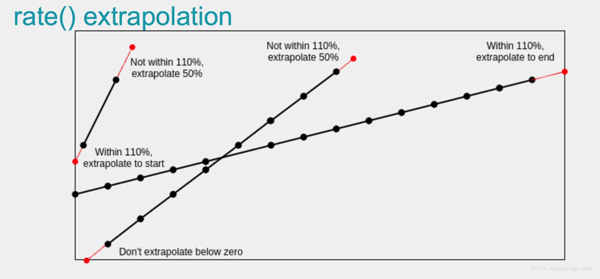
詳細的內容可以看下這個視頻[11]。
反直覺的 P95 統計
histogram_quantile 是 Prometheus 常用的一個函數,比如經常把某個服務的 P95 響應時間來衡量服務質量。不過它到底是什么意思很難解釋得清,特別是面向非技術的同學,會遇到很多“靈魂拷問”。
我們常說 P95(P99,P90都可以) 響應延遲是 100ms,實際上是指對于收集到的所有響應延遲,有 5% 的請求大于 100ms,95% 的請求小于 100ms。Prometheus 里面的 histogram_quantile 函數接收的是 0-1 之間的小數,將這個小數乘以 100 就能很容易得到對應的百分位數,比如 0.95 就對應著 P95,而且還可以高于百分位數的精度,比如 0.9999。
當你用 histogram_quantile 畫出響應時間的趨勢圖時,可能會被問:為什么 P95 大于或小于我的平均值?
正如中位數可能比平均數大也可能比平均數小,P99 比平均值小也是完全有可能的。通常情況下 P99 幾乎總是比平均值要大的,但是如果數據分布比較極端,最大的 1% 可能大得離譜從而拉高了平均值。一種可能的例子:
1, 1, ... 1, 901 // 共 100 條數據,平均值=10,P99=1
服務 X 由順序的 A,B 兩個步驟完成,其中 X 的 P99 耗時 100ms,A 過程 P99 耗時 50ms,那么推測 B 過程的 P99 耗時情況是?
直覺上來看,因為有 X=A+B,所以答案可能是 50ms,或者至少應該要小于 50ms。實際上 B 是可以大于 50ms 的,只要 A 和 B 最大的 1% 不恰好遇到,B 完全可以有很大的 P99:
A = 1, 1, ... 1, 1, 1, 50, 50 // 共 100 條數據,P99=50 B = 1, 1, ... 1, 1, 1, 99, 99 // 共 100 條數據,P99=99 X = 2, 2, ... 1, 51, 51, 100, 100 // 共 100 條數據,P99=100
如果讓 A 過程最大的 1% 接近 100ms,我們也能構造出 P99 很小的 B:
A = 50, 50, ... 50, 50, 99 // 共 100 條數據,P99=50 B = 1, 1, ... 1, 1, 50 // 共 100 條數據,P99=1 X = 51, 51, ... 51, 100, 100 // 共 100 條數據,P99=100
所以我們從題目唯一能確定的只有 B 的 P99 應該不能超過 100ms,A 的 P99 耗時 50ms 這個條件其實沒啥用。
類似的疑問很多,因此對于 histogram_quantile 函數,可能會產生反直覺的一些結果,最好的處理辦法是不斷試驗調整你的 Bucket 的值,保證更多的請求時間落在更細致的區間內,這樣的請求時間才有統計意義。
慢查詢問題
PromQL 的基礎知識看這篇文章[12]。
Prometheus 提供了自定義的 PromQL 作為查詢語句,在 Graph 上調試的時候,會告訴你這條 SQL 的返回時間,如果太慢你就要注意了,可能是你的用法出現了問題。
評估 Prometheus 的整體響應時間,可以用這個默認指標:
prometheus_engine_query_duration_seconds{}一般情況下響應過慢都是 PromQL 使用不當導致,或者指標規劃有問題,如:
大量使用 join 來組合指標或者增加 label,如將 kube-state-metric 中的一些 meta label 和 node-exporter 中的節點屬性 label 加入到 cAdvisor容器數據里,像統計 Pod 內存使用率并按照所屬節點的機器類型分類,或按照所屬 RSS 歸類。
范圍查詢時,大的時間范圍 step 值卻很小,導致查詢到的數量過大。
rate 會自動處理 counter 重置的問題,最好由 PromQL 完成,不要自己拿出來全部元數據在程序中自己做 rate 計算。
在使用 rate 時,range duration 要大于等于 step,否則會丟失部分數據。
Prometheus 是有基本預測功能的,如 deriv 和 predict_linear(更準確)可以根據已有數據預測未來趨勢。
如果比較復雜且耗時的 SQL,可以使用 record rule 減少指標數量,并使查詢效率更高,但不要什么指標都加 record,一半以上的 metric 其實不太會查詢到。同時 label 中的值不要加到 record rule 的 name 中。
高基數問題 Cardinality
高基數是數據庫避不開的一個話題,對于 MySQL 這種 DB 來講,基數是指特定列或字段中包含的唯一值的數量。基數越低,列中重復的元素越多。對于時序數據庫而言,就是 tags、label 這種標簽值的數量多少。
比如 Prometheus 中如果有一個指標 http_request_count{method="get",path="/abc",originIP="1.1.1.1"} 表示訪問量,method 表示請求方法,originIP 是客戶端 IP,method 的枚舉值是有限的,但 originIP 卻是無限的,加上其他 label 的排列組合就無窮大了,也沒有任何關聯特征,因此這種高基數不適合作為 Metric 的 label,真要的提取 originIP,應該用日志的方式,而不是 Metric 監控。
時序數據庫會為這些 Label 建立索引,以提高查詢性能,以便你可以快速找到與所有指定標簽匹配的值。如果值的數量過多,索引是沒有意義的,尤其是做 P95 等計算的時候,要掃描大量 Series 數據。
官方文檔中對于 Label 的建議:
CAUTION: Remember that every unique combination of key-value label pairs represents a new time series, which can dramatically increase the amount of data stored. Do not use labels to store dimensions with high cardinality (many different label values), such as user IDs, email addresses, or other unbounded sets of values.
如何查看當前的 Label 分布情況呢,可以使用 Prometheus 提供的 TSDB 工具。可以使用命令行查看,也可以在 2.16 版本以上的 Prometheus Graph 查看。
[work@xxx bin]$ ./tsdb analyze ../data/prometheus/ Block ID: 01E41588AJNGM31SPGHYA3XSXG Duration: 2h0m0s Series: 955372 Label names: 301 Postings (unique label pairs): 30757 Postings entries (total label pairs): 10842822 ....
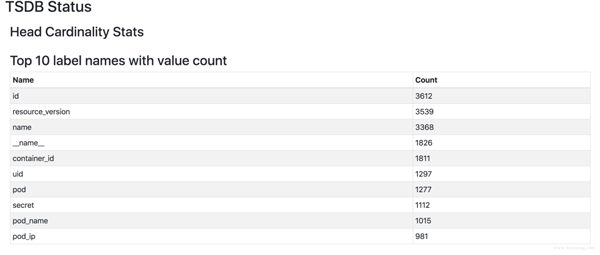

top10 高基數的 metric:
Highest cardinality metric names: 87176 apiserver_request_latencies_bucket 59968 apiserver_response_sizes_bucket 39862 apiserver_request_duration_seconds_bucket 37555 container_tasks_state ....
高基數的 label:
Highest cardinality labels: 4271 resource_version 3670 id 3414 name 1857 container_id 1824 __name__ 1297 uid 1276 pod ...
找到最大的 Metric 或 Job
top10的 Metric 數量:按 Metric 名字分。
topk(10, count by (__name__)({__name__=~".+"})) apiserver_request_latencies_bucket{} 62544 apiserver_response_sizes_bucket{} 44600top10的 Job 數量:按 Job 名字分。
topk(10, count by (__name__, job)({__name__=~".+"})) {job="master-scrape"} 525667 {job="xxx-kubernetes-cadvisor"} 50817 {job="yyy-kubernetes-cadvisor"} 44261Prometheus 重啟慢與熱加載
Prometheus 重啟的時候需要把 Wal 中的內容 Load 到內存里,保留時間越久、Wal 文件越大,重啟的實際越長,這個是 Prometheus 的機制,沒得辦法,因此能 Reload 的就不要重啟,重啟一定會導致短時間的不可用,而這個時候Prometheus高可用就很重要了。
Prometheus 也曾經對啟動時間做過優化,在 2.6 版本中對于 Wal 的 Load 速度就做過速度的優化,希望重啟的時間不超過 1 分鐘。
Prometheus 提供了熱加載能力,不過需要開啟 web.enable-lifecycle 配置,更改完配置后,curl 下 reload 接口即可。prometheus-operator 中更改了配置會默認觸發 reload,如果你沒有使用 Operator,又希望可以監聽 ConfigMap 配置變化來 reload 服務,可以試下這個簡單的腳本。
#!/bin/sh FILE=$1 URL=$2 HASH=$(md5sum $(readlink -f $FILE)) while true; do NEW_HASH=$(md5sum $(readlink -f $FILE)) if [ "$HASH" != "$NEW_HASH" ]; then HASH="$NEW_HASH" echo "[$(date +%s)] Trigger refresh" curl -sSL -X POST "$2" > /dev/null fi sleep 5 done
使用時和 Prometheus 掛載同一個 ConfigMap,傳入如下參數即可:
args: - /etc/prometheus/prometheus.yml - http://prometheus.kube-system.svc.cluster.local:9090/-/reload args: - /etc/alertmanager/alertmanager.yml - http://prometheus.kube-system.svc.cluster.local:9093/-/reload
你的應用需要暴露多少指標
當你開發自己的服務的時候,你可能會把一些數據暴露 Metric 出去,比如特定請求數、Goroutine 數等,指標數量多少合適呢?
雖然指標數量和你的應用規模相關,但也有一些建議(Brian Brazil),比如簡單的服務,如緩存等,類似 Pushgateway,大約 120 個指標,Prometheus 本身暴露了 700 左右的指標,如果你的應用很大,也盡量不要超過 10000 個指標,需要合理控制你的 Label。
node-exporter 的問題
鴻蒙官方戰略合作共建——HarmonyOS技術社區
node-exporter 不支持進程監控,這個前面已經提到了。
node-exporter 只支持 Unix 系統,Windows 機器請使用 wmi_exporter。因此以 yaml 形式不是 node-exporter 的時候,node-selector 要表明 OS 類型。
因為 node_exporter 是比較老的組件,有一些最佳實踐并沒有 merge 進去,比如符合 Prometheus 命名規范,因此建議使用較新的 0.16 和 0.17 版本。
一些指標名字的變化:
* node_cpu -> node_cpu_seconds_total * node_memory_MemTotal -> node_memory_MemTotal_bytes * node_memory_MemFree -> node_memory_MemFree_bytes * node_filesystem_avail -> node_filesystem_avail_bytes * node_filesystem_size -> node_filesystem_size_bytes * node_disk_io_time_ms -> node_disk_io_time_seconds_total * node_disk_reads_completed -> node_disk_reads_completed_total * node_disk_sectors_written -> node_disk_written_bytes_total * node_time -> node_time_seconds * node_boot_time -> node_boot_time_seconds * node_intr -> node_intr_total
如果你之前用的舊版本 Exporter,在繪制 Grafana 的時候指標名稱就會有差別,解決方法有兩種:
一是在機器上啟動兩個版本的 node-exporter,都讓 Prometheus 去采集。
二是使用指標轉換器,他會將舊指標名稱轉換為新指標。
kube-state-metric 的問題
kube-state-metric 的使用和原理可以先看下這篇[13]。
除了文章中提到的作用,kube-state-metric 還有一個很重要的使用場景,就是和 cAdvisor 指標組合,原始的 cAdvisor 中只有 Pod 信息,不知道屬于哪個 Deployment 或者 sts,但是和 kube-state-metric 中的 kube_pod_info 做 join 查詢之后就可以顯示出來,kube-state-metric 的元數據指標,在擴展 cAdvisor 的 label 中起到了很多作用,prometheus-operator 的很多 record rule 就使用了 kube-state-metric 做組合查詢。
kube-state-metric 中也可以展示 Pod 的 label 信息,可以在拿到 cAdvisor 數據后更方便地做 group by,如按照 Pod 的運行環境分類。但是 kube-state-metric 不暴露 Pod 的 annotation,原因是下面會提到的高基數問題,即 annotation 的內容太多,不適合作為指標暴露。
relabel_configs 與 metric_relabel_configs
relabel_config 發生在采集之前,metric_relabel_configs 發生在采集之后,合理搭配可以滿足很多場景的配置。
如:
metric_relabel_configs: - separator: ; regex: instance replacement: $1 action: labeldrop
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_service_annotation_prometheus_io_port] separator: ; regex: (.+);(.+);(.*) target_label: __metrics_path__ replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics action: replacePrometheus 的預測能力
場景 1:你的磁盤剩余空間一直在減少,并且降低的速度比較均勻,你希望知道大概多久之后達到閾值,并希望在某一個時刻報警出來。
場景 2:你的 Pod 內存使用率一直升高,你希望知道大概多久之后會到達 Limit 值,并在一定時刻報警出來,在被殺掉之前上去排查。
Prometheus 的 Deriv 和 Predict_Linear 方法可以滿足這類需求, Promtheus 提供了基礎的預測能力,基于當前的變化速度,推測一段時間后的值。
以 mem_free 為例,最近一小時的 free 值一直在下降。
mem_free 僅為舉例,實際內存可用以 mem_available 為準
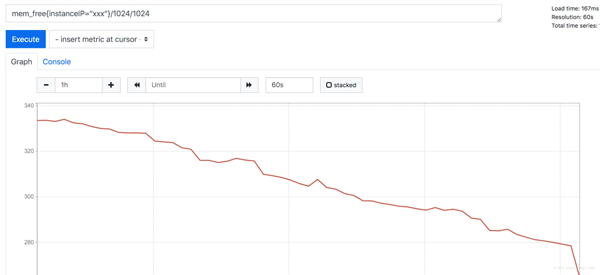
Deriv 函數可以顯示指標在一段時間的變化速度:
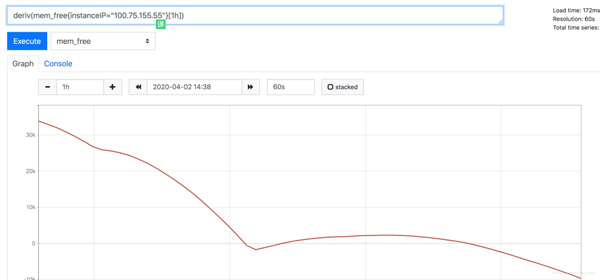
predict_linear 方法是預測基于這種速度,最后可以達到的值:
predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024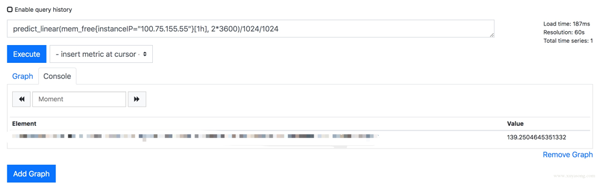
你可以基于設置合理的報警規則,如小于 10 時報警:
bash rule: predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024 <10predict_linear 與 Deriv 的關系:含義上約等于如下表達式,不過 predict_linear 稍微準確一些。
deriv(mem_free{instanceIP="100.75.155.55"}[1h]) * 2 * 3600 + mem_free{instanceIP="100.75.155.55"}[1h]如果你要基于 Metric 做模型預測,可以參考下 forecast-prometheus[14]。
alertmanager 的上層封裝
Prometheus 部署之后很少會改動,尤其是做了服務發現,就不需要頻繁新增 target。但報警的配置是很頻繁的,如修改閾值、修改報警人等。alertmanager 擁有豐富的報警能力如分組、抑制等,但如果你要想把它給業務部門使用,就要做一層封裝了,也就是報警配置臺。用戶喜歡表單操作,而非晦澀的 yaml,同時他們也并不愿意去理解 PromQL。而且大多數公司內已經有現成的監控平臺,也只有一份短信或郵件網關,所以最好能使用 webhook 直接集成。
例如:機器磁盤使用量超過 90% 就報警,rule 應該寫為:disk_used/disk_total > 0.9。
如果不加 label 篩選,這條報警會對所有機器生效,但如果你想去掉其中幾臺機器,就得在 disk_used 和 disk_total 后面加上 {instance != ""}。這些操作在 PromQL 中是很簡單的,但是如果放在表單里操作,就得和內部的 CMDB 做聯動篩選了。
對于一些簡單的需求,我們使用了 Grafana 的報警能力,所見即所得,直接在圖表下面配置告警即可,報警閾值和狀態很清晰。不過 Grafana 的報警能力很弱,只是實驗功能,可以作為調試使用。
對于常見的 Pod 或應用監控,我們做了一些表單化,如下圖所示:提取了 CPU、內存、磁盤 IO 等常見的指標作為選擇項,方便配置。
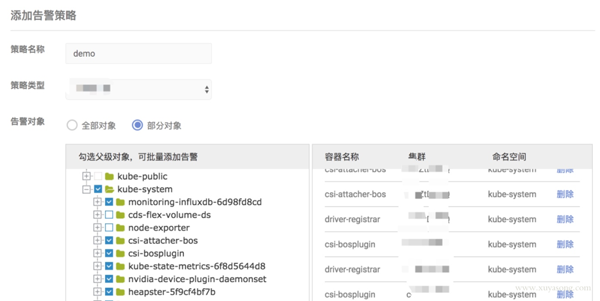
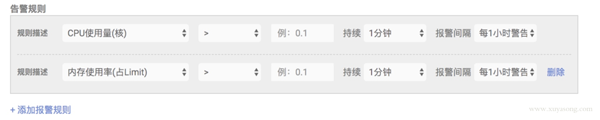
使用 webhook 擴展報警能力,改造 alertmanager, 在 send message 時做加密和認證,對接內部已有報警能力,并聯動用戶體系,做限流和權限控制。
調用 alertmanager api 查詢報警事件,進行展示和統計。
對于用戶來說,封裝 alertmanager yaml 會變的易用,但也會限制其能力,在增加報警配置時,研發和運維需要有一定的配合。如新寫了一份自定義的 exporter,要將需要的指標供用戶選擇,并調整好展示和報警用的 PromQL。還有報警模板、原生 PromQL 暴露、用戶分組等,需要視用戶需求做權衡。
錯誤的高可用設計
有些人提出過這種類型的方案,想提高其擴展性和可用性。

應用程序將 Metric 推到到消息隊列如 Kafaka,然后經過 Exposer 消費中轉,再被 Prometheus 拉取。產生這種方案的原因一般是有歷史包袱、復用現有組件、想通過 MQ 來提高擴展性。
這種方案有幾個問題:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
增加了 Queue 組件,多了一層依賴,如果 App 與 Queue 之間連接失敗,難道要在 App 本地緩存監控數據?
抓取時間可能會不同步,延遲的數據將會被標記為陳舊數據,當然你可以通過添加時間戳來標識,但就失去了對陳舊數據的處理邏輯。
擴展性問題:Prometheus 適合大量小目標,而不是一個大目標,如果你把所有數據都放在了 Exposer 中,那么 Prometheus 的單個 Job 拉取就會成為 CPU 瓶頸。這個和 Pushgateway 有些類似,沒有特別必要的場景,都不是官方建議的方式。
4. 缺少了服務發現和拉取控制,Prom 只知道一個 Exposer,不知道具體是哪些 Target,不知道他們的 UP 時間,無法使用 Scrape_* 等指標做查詢,也無法用 scrape_limit 做限制。
如果你的架構和 Prometheus 的設計理念相悖,可能要重新設計一下方案了,否則擴展性和可靠性反而會降低。
prometheus-operator 的場景
如果你是在 Kubernetes 集群內部署 Prometheus,那大概率會用到 prometheus-operator,他對 Prometheus 的配置做了 CRD 封裝,讓用戶更方便的擴展 Prometheus 實例,同時 prometheus-operator 還提供了豐富的 Grafana 模板,包括上面提到的 Master 組件監控的 Grafana 視圖,Operator 啟動之后就可以直接使用,免去了配置面板的煩惱。
Operator 的優點很多,就不一一列舉了,只提一下 Operator 的局限:
因為是 Operator,所以依賴 Kubernetes 集群,如果你需要二進制部署你的 Prometheus,如集群外部署,就很難用上 prometheus-operator 了,如多集群場景。當然你也可以在 Kubernetes 集群中部署 Operator 去監控其他的 Kubernetes 集群,但這里面坑不少,需要修改一些配置。
Operator 屏蔽了太多細節,這個對用戶是好事,但對于理解 Prometheus 架構就有些 gap 了,比如碰到一些用戶一鍵安裝了 Operator,但 Grafana 圖表異常后完全不知道如何排查,record rule 和服務發現還不了解的情況下就直接配置,建議在使用 Operator 之前,最好熟悉 Prometheus 的基礎用法。
Operator 方便了 Prometheus 的擴展和配置,對于 alertmanager 和 exporter 可以很方便的做到多實例高可用,但是沒有解決 Prometheus 的高可用問題,因為無法處理數據不一致,Operator 目前的定位也還不是這個方向,和 Thanos、Cortex 等方案的定位是不同的,下面會詳細解釋。
高可用方案
Prometheus 高可用有幾種方案:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
基本 HA:即兩套 Prometheus 采集完全一樣的數據,外邊掛負載均衡。
HA + 遠程存儲:除了基礎的多副本 Prometheus,還通過 Remote Write 寫入到遠程存儲,解決存儲持久化問題。
聯邦集群:即 Federation,按照功能進行分區,不同的 Shard 采集不同的數據,由 Global 節點來統一存放,解決監控數據規模的問題。
使用 Thanos 或者 Victoriametrics,來解決全局查詢、多副本數據 Join 問題。
就算使用官方建議的多副本 + 聯邦,仍然會遇到一些問題:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
官方建議數據做 Shard,然后通過Federation來實現高可用,
但是邊緣節點和Global節點依然是單點,需要自行決定是否每一層都要使用雙節點重復采集進行保活。 也就是仍然會有單機瓶頸。
另外部分敏感報警盡量不要通過 Global 節點觸發,畢竟從 Shard 節點到 Global 節點傳輸鏈路的穩定性會影響數據到達的效率,進而導致報警實效降低。
例如服務 Updown 狀態,API 請求異常這類報警我們都放在 Shard 節點進行報警。
本質原因是,Prometheus 的本地存儲沒有數據同步能力,要在保證可用性的前提下,再保持數據一致性是比較困難的,基礎的 HA Proxy 滿足不了要求,比如:
集群的后端有 A 和 B 兩個實例,A 和 B 之間沒有數據同步。A 宕機一段時間,丟失了一部分數據,如果負載均衡正常輪詢,請求打到 A 上時,數據就會異常。
如果 A 和 B 的啟動時間不同,時鐘不同,那么采集同樣的數據時間戳也不同,就不是多副本同樣數據的概念了。
就算用了遠程存儲,A 和 B 不能推送到同一個 TSDB,如果每人推送自己的 TSDB,數據查詢走哪邊就是問題了。
因此解決方案是在存儲、查詢兩個角度上保證數據的一致:
存儲角度:如果使用 Remote Write 遠程存儲, A 和 B 后面可以都加一個 Adapter,Adapter 做選主邏輯,只有一份數據能推送到 TSDB,這樣可以保證一個異常,另一個也能推送成功,數據不丟,同時遠程存儲只有一份,是共享數據。方案可以參考這篇文章[15]。
查詢角度:上邊的方案實現很復雜且有一定風險,因此現在的大多數方案在查詢層面做文章,比如 Thanos 或者 Victoriametrics,仍然是兩份數據,但是查詢時做數據去重和 Join。只是 Thanos 是通過 Sidecar 把數據放在對象存儲,Victoriametrics 是把數據 Remote Write 到自己的 Server 實例,但查詢層 Thanos-Query 和 Victor 的 Promxy 的邏輯基本一致。
我們采用了 Thanos 來支持多地域監控數據,具體方案可以看這篇文章[16]。
容器日志與事件
本文主要是 Prometheus 監控內容,這里只簡單介紹下 Kubernetes 中的日志、事件處理方案,以及和 Prometheus 的搭配。
日志處理:
日志采集與推送:一般是 Fluentd/Fluent-Bit/Filebeat 等采集推送到 ES、對象存儲、Kafka,日志就該交給專業的 EFK 來做,分為容器標準輸出、容器內日志。
日志解析轉 metric:可以提取一些日志轉為 Prometheus 格式的指標,如解析特定字符串出現次數,解析 Nginx 日志得到 QPS 、請求延遲等。常用方案是 mtail 或者 grok。
日志采集方案:
Sidecar 方式:和業務容器共享日志目錄,由 sidecar 完成日志推送,一般用于多租戶場景。
DaemonSet 方式:機器上運行采集進程,統一推送出去。
需要注意的點:對于容器標準輸出,默認日志路徑是 /var/lib/docker/containers/xxx, kubelet 會將改日志軟鏈到/var/log/pods,同時還有一份 /var/log/containers 是對 /var/log/pods 的軟鏈。不過不同的 Kubernetes 版本,日志的目錄格式有所變化,采集時根據版本做區分:
1.15 及以下:/var/log/pods/{pod_uid}/
1.15 以上:var/log/pods/{pod_name+namespace+rs+uuid}/
事件:在這里特指 Kubernetes Events,Events 在排查集群問題時也很關鍵,不過默認情況下只保留 1h,因此需要對 Events 做持久化。一般 Events 處理方式有兩種:
使用 kube-eventer 之類的組件采集 Events 并推送到 ES
使用 event_exporter 之類的組件將 Events 轉化為 Prometheus Metric,同類型的還有谷歌云的 stackdriver 下的 event-exporter。
“有哪些高可用Prometheus架構實踐中的坑”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





