溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“程序員應怎么理解高并發中的協程”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“程序員應怎么理解高并發中的協程”吧!
話不多說,今天的主題就是作為程序員,你應該如何徹底理解協程。
普通的函數
我們先來看一個普通的函數,這個函數非常簡單:
def func(): print("a") print("b") print("c")這是一個簡單的普通函數,當我們調用這個函數時會發生什么?
調用func
func開始執行,直到return
func執行完成,返回函數A
是不是很簡單,函數func執行直到返回,并打印出:
a b c
So easy,有沒有,有沒有!
很好!
注意這段代碼是用python寫的,但本篇關于協程的討論適用于任何一門語言,因為協程并不是一種語言的特性。而我們只不過恰好使用了python來用作示例,因其足夠簡單。
那么協程是什么呢?
從普通函數到協程
接下來,我們就要從普通函數過渡到協程了。
和普通函數只有一個返回點不同,協程可以有多個返回點。
這是什么意思呢?
void func() { print("a") 暫停并返回 print("b") 暫停并返回 print("c") }普通函數下,只有當執行完print("c")這句話后函數才會返回,但是在協程下當執行完print("a")后func就會因“暫停并返回”這段代碼返回到調用函數。
有的同學可能會一臉懵逼,這有什么神奇的嗎?我寫一個return也能返回,就像這樣:
void func() { print("a") return print("b") 暫停并返回 print("c") }直接寫一個return語句確實也能返回,但這樣寫的話return后面的代碼都不會被執行到了。
協程之所以神奇就神奇在當我們從協程返回后還能繼續調用該協程,并且是從該協程的上一個返回點后繼續執行。
這足夠神奇吧,就好比孫悟空說一聲“定”,函數就被暫停了:
void func() { print("a") 定 print("b") 定 print("c") }這時我們就可以返回到調用函數,當調用函數什么時候想起該協程后可以再次調用該協程,該協程會從上一個返回點繼續執行。
Amazing,有沒有,集中注意力,千萬不要翻車。
只不過孫大圣使用的口訣“定”字,在編程語言中一般叫做yield(其它語言中可能會有不同的實現,但本質都是一樣的)。
需要注意的是,當普通函數返回后,進程的地址空間中不會再保存該函數運行時的任何信息,而協程返回后,函數的運行時信息是需要保存下來的,那么函數的運行時狀態到底在內存中是什么樣子呢,關于這個問題你可以參考這里。
接下來,我們就用實際的代碼看一看協程。
Show Me The Code
下面我們使用一個真實的例子來講解,語言采用python,不熟悉的同學不用擔心,這里不會有理解上的門檻。
在python語言中,這個“定”字同樣使用關鍵詞yield,這樣我們的func函數就變成了:
void func() { print("a") yield print("b") yield print("c") }注意,這時我們的func就不再是簡簡單單的函數了,而是升級成為了協程,那么我們該怎么使用呢,很簡單:
def A(): co = func() # 得到該協程 next(co) # 調用協程 print("in function A") # do something next(co) # 再次調用該協程我們看到雖然func函數沒有return語句,也就是說雖然沒有返回任何值,但是我們依然可以寫co = func()這樣的代碼,意思是說co就是我們拿到的協程了。
接下來我們調用該協程,使用next(co),運行函數A看看執行到第3行的結果是什么:
a
顯然,和我們的預期一樣,協程func在print("a")后因執行yield而暫停并返回函數A。
接下來是第4行,這個毫無疑問,A函數在做一些自己的事情,因此會打印:
a in function A
接下來是重點的一行,當執行第5行再次調用協程時該打印什么呢?
如果func是普通函數,那么會執行func的第一行代碼,也就是打印a。
但func不是普通函數,而是協程,我們之前說過,協程會在上一個返回點繼續運行,因此這里應該執行的是func函數第一個yield之后的代碼,也就是print("b")。
a in function A b
看到了吧,協程是一個很神奇的函數,它會自己記住之前的執行狀態,當再次調用時會從上一次的返回點繼續執行。
圖形化解釋
為了讓你更加徹底的理解協程,我們使用圖形化的方式再看一遍,首先是普通的函數調用:
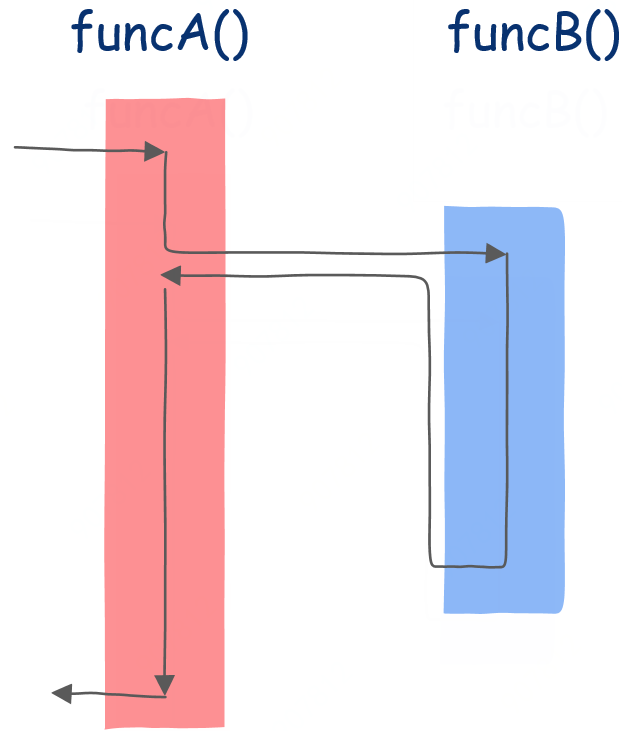
在該圖中,方框內表示該函數的指令序列,如果該函數不調用任何其它函數,那么應該從上到下依次執行,但函數中可以調用其它函數,因此其執行并不是簡單的從上到下,箭頭線表示執行流的方向。
從圖中我們可以看到,我們首先來到funcA函數,執行一段時間后發現調用了另一個函數funcB,這時控制轉移到該函數,執行完成后回到main函數的調用點繼續執行。
這是普通的函數調用。
接下來是協程。
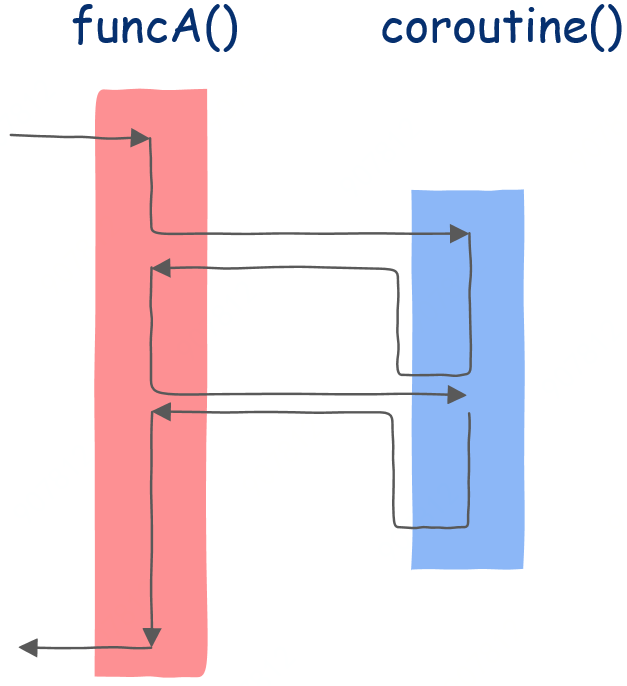
在這里,我們依然首先在funcA函數中執行,運行一段時間后調用協程,協程開始執行,直到第一個掛起點,此后就像普通函數一樣返回funcA函數,funcA函數執行一些代碼后再次調用該協程,注意,協程這時就和普通函數不一樣了,協程并不是從第一條指令開始執行而是從上一次的掛起點開始執行,執行一段時間后遇到第二個掛起點,這時協程再次像普通函數一樣返回funcA函數,funcA函數執行一段時間后整個程序結束。
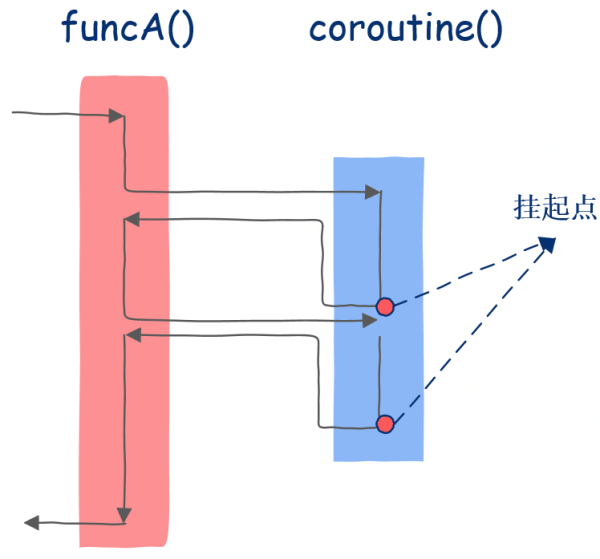
函數只是協程的一種特例
怎么樣,神奇不神奇,和普通函數不同的是,協程能知道自己上一次執行到了哪里。
現在你應該明白了吧,協程會在函數被暫停運行時保存函數的運行狀態,并可以從保存的狀態中恢復并繼續運行。
很熟悉的味道有沒有,這不就是操作系統對線程的調度嘛,線程也可以被暫停,操作系統保存線程運行狀態然后去調度其它線程,此后該線程再次被分配CPU時還可以繼續運行,就像沒有被暫停過一樣。
只不過線程的調度是操作系統實現的,這些對程序員都不可見,而協程是在用戶態實現的,對程序員可見。
這就是為什么有的人說可以把協程理解為用戶態線程的原因。
此處應該有掌聲。
也就是說現在程序員可以扮演操作系統的角色了,你可以自己控制協程在什么時候運行,什么時候暫停,也就是說協程的調度權在你自己手上。
在協程這件事兒上,調度你說了算。
當你在協程中寫下yield的時候就是想要暫停該協程,當使用next()時就是要再次運行該協程。
現在你應該理解為什么說函數只是協程的一種特例了吧,函數其實只是沒有掛起點的協程而已。
協程的歷史
有的同學可能認為協程是一種比較新的技術,然而其實協程這種概念早在1958年就已經提出來了,要知道這時線程的概念都還沒有提出來。
到了1972年,終于有編程語言實現了這個概念,這兩門編程語言就是Simula 67 以及Scheme。

但協程這個概念始終沒有流行起來,甚至在1993年還有人考古一樣專門寫論文挖出協程這種古老的技術。
因為這一時期還沒有線程,如果你想在操作系統寫出并發程序那么你將不得不使用類似協程這樣的技術,后來線程開始出現,操作系統終于開始原生支持程序的并發執行,就這樣,協程逐漸淡出了程序員的視線。
直到近些年,隨著互聯網的發展,尤其是移動互聯網時代的到來,服務端對高并發的要求越來越高,協程再一次重回技術主流,各大編程語言都已經支持或計劃開始支持協程。
那么協程到底是如何實現的呢?
協程是如何實現的
讓我們從問題的本質出發來思考這個問題。
協程的本質是什么呢?
其實就是可以被暫停以及可以被恢復運行的函數。
那么可以被暫停以及可以被恢復意味著什么呢?
看過籃球比賽的同學想必都知道(沒看過的也能知道),籃球比賽也是可以被隨時暫停的,暫停時大家需要記住球在哪一方,各自的站位是什么,等到比賽繼續的時候大家回到各自的位置,裁判哨子一響比賽繼續,就像比賽沒有被暫停過一樣。
看到問題的關鍵了嗎,比賽之所以可以被暫停也可以繼續是因為比賽狀態被記錄下來了(站位、球在哪一方),這里的狀態就是計算機科學中常說的上下文,context。
回到協程。
協程之所以可以被暫停也可以繼續,那么一定要記錄下被暫停時的狀態,也就是上下文,當繼續運行的時候要恢復其上下文(狀態),那么接下來很自然的一個問題就是,函數運行時的狀態是什么?
這個關鍵的問題的答案就在《函數運行起來后在內存中是什么樣子的》這篇文章中,函數運行時所有的狀態信息都位于函數運行時棧中。
函數運行時棧就是我們需要保存的狀態,也就是所謂的上下文,如圖所示:
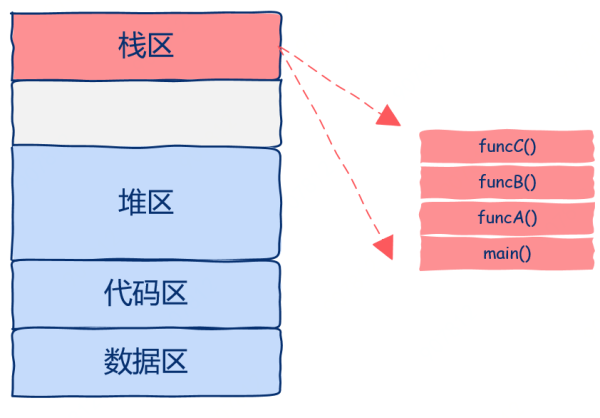
從圖中我們可以看出,該進程中只有一個線程,棧區中有四個棧幀,main函數調用A函數,A函數調用B函數,B函數調用C函數,當C函數在運行時整個進程的狀態就如圖所示。
現在我們已經知道了函數的運行時狀態就保存在棧區的棧幀中,接下來重點來了哦。
既然函數的運行時狀態保存在棧區的棧幀中,那么如果我們想暫停協程的運行就必須保存整個棧幀的數據,那么我們該將整個棧幀中的數據保存在哪里呢?
想一想這個問題,整個進程的內存區中哪一塊是專門用來長時間(進程生命周期)存儲數據的?是不是大腦又一片空白了?
先別空白!
很顯然,這就是堆區啊,heap,我們可以將棧幀保存在堆區中,那么我們該怎么在堆區中保存數據呢?希望你還沒有暈,在堆區中開辟空間就是我們常用的C語言中的malloc或者C++中的new。
我們需要做的就是在堆區中申請一段空間,讓后把協程的整個棧區保存下,當需要恢復協程的運行時再從堆區中copy出來恢復函數運行時狀態。
再仔細想一想,為什么我們要這么麻煩的來回copy數據呢?
實際上,我們需要做的是直接把協程的運行需要的棧幀空間直接開辟在堆區中,這樣都不用來回copy數據了,如圖所示。
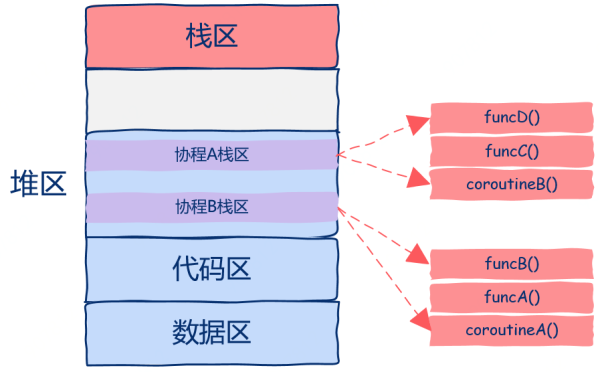
從圖中我們可以看到,該程序中開啟了兩個協程,這兩個協程的棧區都是在堆上分配的,這樣我們就可以隨時中斷或者恢復協程的執行了。
有的同學可能會問,那么進程地址空間最上層的棧區現在的作用是什么呢?
這一區域依然是用來保存函數棧幀的,只不過這些函數并不是運行在協程而是普通線程中的。
現在你應該看到了吧,在上圖中實際上有3個執行流:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
一個普通線程
兩個協程
雖然有3個執行流但我們創建了幾個線程呢?
一個線程。
現在你應該明白為什么要使用協程了吧,使用協程理論上我們可以開啟無數并發執行流,只要堆區空間足夠,同時還沒有創建線程的開銷,所有協程的調度、切換都發生在用戶態,這就是為什么協程也被稱作用戶態線程的原因所在。
掌聲在哪里?
因此即使你創建了N多協程,但在操作系統看來依然只有一個線程,也就是說協程對操作系統來說是不可見的。
這也許是為什么協程這個概念比線程提出的要早的原因,可能是寫普通應用的程序員比寫操作系統的程序員最先遇到需要多個并行流的需求,那時可能都還沒有操作系統的概念,或者操作系統沒有并行這種需求,所以非操作系統程序員只能自己動手實現執行流,也就是協程。
現在你應該對協程有一個清晰的認知了吧。
到此,相信大家對“程序員應怎么理解高并發中的協程”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





