溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何理解微服務架構下的高可用和高性能設計”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何理解微服務架構下的高可用和高性能設計”吧!
對于業務系統的高可用性,實際上包括了高可靠,高性能和高擴展三個方面的內容。而且三方面相互之間還存在相互的依賴和影響關系。
對于三者的關系,我們可以用下圖進行描述。
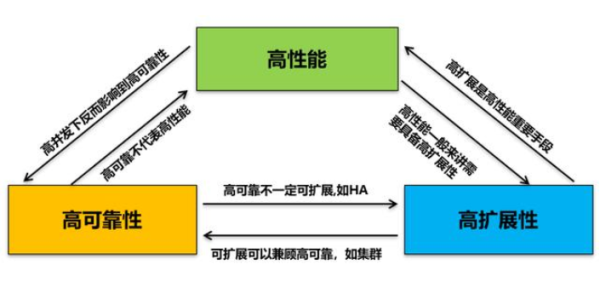
上圖可以看到高可靠,高性能和高擴展性三者之間的關系。
對于高可靠性來來說,傳統的HA架構,冗余設計都可以滿足高可靠性要求,但是并不代表系統具備了高性能和可擴展性能力。反過來說,當系統具備了高擴展性的時候,一般我們在設計擴展性的時候都會考慮到同時兼顧冗余和高可靠,比如我們常說的集群技術。
對于高性能和高擴展性兩點來說,高擴展性是高性能的必要條件,但是并不是充分條件。一個業務系統的高性能不是簡單的具備擴展能力就可以,而是需要業務系統本身軟件架構設計,代碼編寫各方面都滿足高性能設計要求。
對于高可靠和高性能,兩者反而表現出來一種相互制約的關系,即在高性能支撐的狀態下,往往是對系統的高可靠性形成嚴峻挑戰,也正是這個原因我們會看到類似限流熔斷,SLA服務降級等各種措施來控制異常狀態下的大并發訪問和調用。
在我前面談微服務架構的時候就談到,在微服務架構下傳統的單體應用要進行拆分,這個拆分不僅僅是應用層組件的拆分,還包括了數據庫本身的拆分。
如果一個傳統的單體應用規劃為10個微服務,則可能會垂直拆分為10個獨立的數據庫。這實際上減小了每一個數據庫本身面對的性能負荷,同時提升了數據庫整體的處理能力。
同時在拆分后雖然引入了各種跨庫查詢,分布式事務等問題,但是實際很多跨庫操作,復制的數據處理計算都不在數據庫里面完成,數據庫更多的是提供單純的CRUD類操作接口,這本身也是提升數據庫性能的一個關鍵。
如果采用Mysql數據庫。
要滿足高可靠性,你可以采用Dual-Master雙主架構,即兩個主節點雙活,但是僅一個節點提供數據庫接口能力,另外一個節點實時同步數據庫日志,作為備節點。當主節點出現故障的時候,備節點自動轉變為主節點服務。
簡單的雙主架構兩節點間安裝代理,通過Binlog日志復制,上層通過類似Haproxy+Keepalive實現通過的VIP浮動IP提供和心跳監測。
可以看到雙主架構更多的是為高可靠服務。
如果要滿足高性能,常采用的是讀寫分離集群。即1個主節點承擔讀寫操作,多個從節點承擔讀操作。從節點仍然是通過Binlog日志進行主節點信息同步。當有數據訪問請求進入的時候,前端Proxy可以自動分析是CUD類請求,還是R讀請求,以進行請求的路由轉發。
當我們進行訂單新增操作的時候,當新增成功的時候需要快速的刷新當前訂單列表界面,第二次的刷新本身是讀操作,但是和前面的寫綁定很緊,實際上不太適合從Slave節點讀取數據的。這個時候可以在進行Sql調用的時候明確指定是否仍然從主節點獲取數據。
當然,大部分時候可能需要兩者結合,既提供足夠的高可靠性,又提供足夠的高性能。因此Mysql集群在搭建的時候既需要進行雙主設置,又需要進行多個從節點設置。
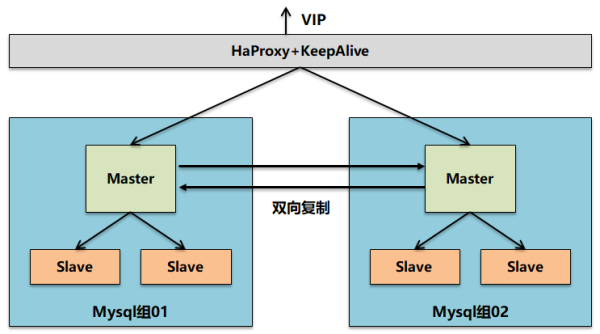
在上圖這種邏輯部署架構下,基本就可以同時滿足高可靠和高性能兩個方面的需求。但是從上面架構部署可以看到,備節點的主和從都處于一種熱備無法實際提供能力狀態。
是否可以將所有Slave掛到一個Master上?
如果這樣設計,那么當主Master出現故障的時候,就需要對多個Slave節點進行自動化漂移。這一方面是整體實現比較復雜,另外就是可靠性也不如上面這種架構。
首先來看前面架構本身的一些潛在問題點:
第一就是CUD操作仍然是單節點提供能力。對于讀操作占大部分場景的,基本可以通過雙主+讀寫分離集群實現很好的性能擴展。但是如果CUD操作頻繁仍然可能出現性能問題。
其次,數據庫性能問題一般分為兩個層面,其一就是大并發請求下的性能,這個可以通過集群負載均衡去解決,其二是單個請求訪問大數據庫表模糊查詢性能,這個是服務通過負載去解決的。
也就是說上面的設計,在大并發的CUD操作,對大數據表的關聯查詢或模糊查詢操作仍然可能出現明顯的性能問題。
如何來解決這個問題?
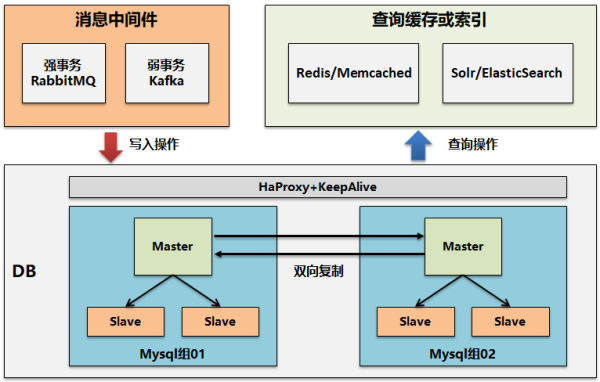
簡單來說就是寫入通過消息中間件來將同步轉異步,進行前端削峰。而對于查詢則進行內容緩存或創建二級索引,提升查詢效率。
對于查詢本身又包括了偏結構化數據查詢和處理,類似采用Redis庫或Memcached進行緩存;而對于非結構化數據,類似消息報文,日志等采用Solr或ElasticSearch構建二級索引并實現全文檢索能力。
當面臨大量的數據寫入操作類操作的時候,單個Master節點往往性能很難支撐住,這個時候采用類似RabbitMQ,RocketMQ,Kafka等消息中間件來進行異步銷峰處理就是必要的。這個異步實際上涉及到兩個層面的異步。
其一是對于發短信,記錄日志,啟流程等接口服務異步。其二是對長耗時寫入操作異步,先反饋用戶請求收到,處理完再通知用戶拿結果。
而對于查詢操作,前面談到的并發查詢可以進行集群負載。
但是對于大數據量表,比如上億記錄的大表模糊查詢,這塊就必須進行二級索引。對這種大的數據表的查詢即使沒有并發查詢,如果不進行二級索引,查詢效率和響應速度仍然很慢。
對半結構化信息啟用分布式存儲
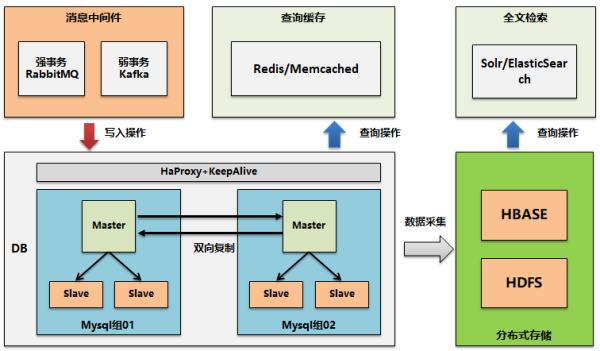
對于類似日志,接口服務調用日志等半結構化信息,本身數據量很大,如果全部存儲在結構化數據庫中,那么對存儲空間需求很大,而且很難擴展。特別是前面的Mysql集群方案本身還是采用本地磁盤進行存儲的情況下。
因此需要對歷史日志進行清除,同時將歷史日志遷移到分布式存儲庫,比如Hdfs或Hbase庫,然后基于分布式存儲再構建二級緩存能力。
構建DaaS數據層進行水平擴展
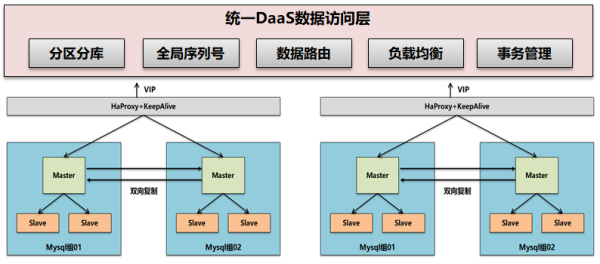
前面談到在拆分了微服務后已經進行了垂直擴展,比如一個資產管理系統可以拆分為資產新增,資產調撥,資產折舊,資產盤點等10個微服務模塊。
但是在拆分后仍然發現資產數據量極大,比如在集團集中化這種大型項目可以看到,一個省的資產數據表就接近上億條記錄。這種時候將所有省數據全部集中化在一個數據庫管理不現實。因此需要進一步按省份或組織域進行水平拆分。
在水平拆分后,在上層構建DaaS層提供統一對外訪問能力。
對于應用集群擴展實際比數據庫層要簡單,應用中間件層可以很方便的結合集群管理節點或者獨立的負載均衡硬件或軟件進行集群能力擴展。對于應用集群擴展,本身就是提升整個性能的關鍵方式。在集群的擴展過程中還是有些問題需要進一步討論。
集群做到完全的無狀態化
如果集群做到完全的無狀態化,那么集群就可以做到和負載均衡設備或軟件結合來實現負載均衡擴展能力。比如硬件常用的F5或radware等,軟件如HAProxy,Nginx等。
Session會話信息如何處理?對于Session本身是有狀態的,因此對于Session信息可以考慮存儲到數據庫或Redis緩存庫中。
集群節點在啟動的時候往往需要讀取一些全局變量或配置文件信息,這些信息如果簡單的存在在本地磁盤往往難以集中化管理。因此當前主流思路是啟用全局的配置中心來統一管理配置。
如果應用功能實現中存在文件的上傳和存儲,那么這些文件存儲在磁盤本地本身也是有狀態的,因此對于這些文件本身也需要通過文件服務能力或分布式對象存儲服務能力來實現。
微服務架構下各個微服務間本身存在接口交互和協同,對于接口調用的具體地址信息也需要通過服務注冊中心獲取,獲取后可以緩存在本地,但是必須有變更后實時更新機制。
四層負載和七層負載
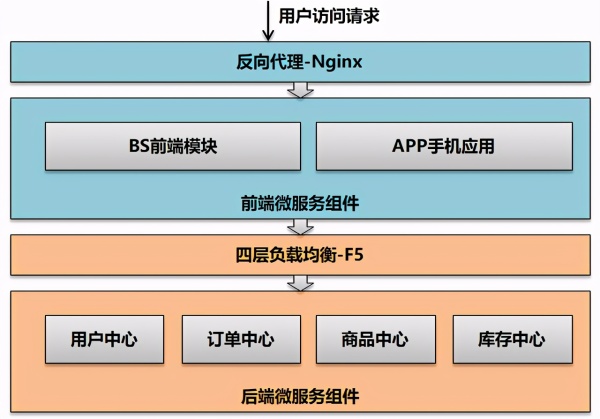
首先看下最簡單的四層負載和七層負載的一個說明:
四層負載:即在OSI第4層工作,就是TCP層,可以根據IP+端口進行負載均衡。此種Load Balance不理解應用協議(如HTTP/FTP/MySQL等等)。
七層負載:工作在OSI的最高層,應用層,可以基于Http協議和URL內容進行負載均衡。此時負載均衡能理解應用協議。
當前可以看到對于F5,Array等硬件負載均衡設備本身也是支持7層負載均衡的,同時在四層負載均衡的時候我們還可以設置是否進行會話保持等高級特性。要明白四層負載均衡本質是轉發,而七層負載本質是內容交換和代理。
也就是說在不需要進行狀態保留和基于內容的路由的時候,我們完全可以啟用四層負載均衡來獲取更好的性能。
在微服務架構前后端分離開發后。
后端微服務組件可以完全提供Rest API接口服務能力,那么本身就無狀態。而對于前端微服務組件直接面對最終用戶訪問,需要保持Session狀態。在這種情況下就可以進行兩層負載均衡設計,即前端采用七層負載,而后端采用四層負載均衡。
前端緩存
前端緩存主要是分為HTTP緩存和瀏覽器緩存。其中HTTP緩存是在HTTP請求傳輸時用到的緩存,主要在服務器代碼上設置;而瀏覽器緩存則主要由前端開發在前端js上進行設置。緩存可以說是性能優化中簡單高效的一種優化方式了。一個優秀的緩存策略可以縮短網頁請求資源的距離,減少延遲,并且由于緩存文件可以重復利用,還可以減少帶寬,降低網絡負荷。
具體可以參考:
https://www.jianshu.com/p/256d0873c398
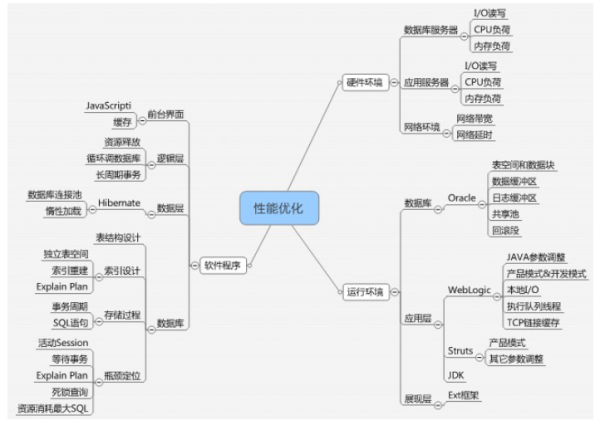
對于業務系統性能診斷,如果從靜態角度我們可以考慮從以下三個方面進行分類
鴻蒙官方戰略合作共建——HarmonyOS技術社區
操作系統和存儲層面
中間件層面(包括了數據庫,應用服務器中間件)
軟件層面(包括了數據庫SQL和存儲過程,邏輯層,前端展現層等)
那么一個業務系統應用功能出現問題了,我們當然也可以從動態層面來看實際一個應用請求從調用開始究竟經過了哪些代碼和硬件基礎設施,通過分段方法來定位和查詢問題。
比如我們常見的就是一個查詢功能如果出現問題了,首先就是找到這個查詢功能對應的SQL語句在后臺查詢是否很慢,如果這個SQL本身就慢,那么就要優化優化SQL語句。如果SQL本身快但是查詢慢,那就要看下是否是前端性能問題或者集群問題等。
軟件代碼的問題往往是最不能忽視的一個性能問題點
對于業務系統性能問題,我們經常想到的就是要擴展數據庫的硬件性能,比如擴展CPU和內存,擴展集群,但是實際上可以看到很多應用的性能問題并不是硬件性能導致的,而是由于軟件代碼性能引起的。對于軟件代碼常見的性能問題我在以往的博客文章里面也談過到,比較典型的包括了。
鴻蒙官方戰略合作共建——HarmonyOS技術社區
循環中初始化大的結構對象,數據庫連接等
資源不釋放導致的內存泄露等
沒有基于場景需求來適度通過緩存等方式提升性能
長周期事務處理耗費資源
處理某一個業務場景或問題的時候,沒有選擇最優的數據結構或算法
以上都是常見的一些軟件代碼性能問題點,而這些往往需要通過我們進行Code Review或代碼評審的方式才能夠發現出來。因此如果要做全面的性能優化,對于軟件代碼的性能問題排查是必須的。
其次就是可以通過APM性能監控工具來發現性能問題。
傳統模式下,當出現CPU或內存滿負荷的時候,如果要查找到具體是哪個應用,哪個進程或者具體哪個業務功能,哪個sql語句導致的往往并不是容易的事情。在實際的性能問題優化中往往也需要做大量的日志分析和問題定位,最終才可能找到問題點。
而通過APM可以很好的解決這個問題。
比如在我們最近的項目實施中,結合APM和服務鏈監控,我們可以快速的發現究竟是哪個服務調用出現了性能問題,或者快速的定位出哪個SQL語句有驗證的性能問題。這個都可以幫助我們快速的進行性能問題分析和診斷。
資源上承載的是應用,應用本身又包括了數據庫和應用中間件容器,同時也包括了前端;在應用之上則是對應到具體的業務功能。因此APM一個核心就是要將資源-》應用-》功能之間進行整合分析和銜接。通過APM來發現應用運行中的性能問題并解決。
感謝各位的閱讀,以上就是“如何理解微服務架構下的高可用和高性能設計”的內容了,經過本文的學習后,相信大家對如何理解微服務架構下的高可用和高性能設計這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





