溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關便捷搭建Zookeeper服務器的方法,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
什么是 ZooKeeper
ZooKeeper 是 Apache 的一個頂級項目,為分布式應用提供高效、高可用的分布式協調服務,提供了諸如數據發布/訂閱、負載均衡、命名服務、分布式協調/通知和分布式鎖等分布式基礎服務。由于 ZooKeeper 便捷的使用方式、卓越的性能和良好的穩定性,被廣泛地應用于諸如 Hadoop、HBase、Kafka 和 Dubbo 等大型分布式系統中。
Zookeeper有三種運行模式:單機模式、偽集群模式和集群模式。
單機模式:這種模式一般適用于開發測試環境,一方面我們沒有那么多機器資源,另外就是平時的開發調試并不需要極好的穩定性。
集群模式:一個 ZooKeeper 集群通常由一組機器組成,一般 3 臺以上就可以組成一個可用的 ZooKeeper 集群了。組成 ZooKeeper 集群的每臺機器都會在內存中維護當前的服務器狀態,并且每臺機器之間都會互相保持通信。
偽集群模式:這是一種特殊的集群模式,即集群的所有服務器都部署在一臺機器上。當你手頭上有一臺比較好的機器,如果作為單機模式進行部署,就會浪費資源,這種情況下,ZooKeeper 允許你在一臺機器上通過啟動不同的端口來啟動多個 ZooKeeper 服務實例,以此來以集群的特性來對外服務。
ZooKeeper 的相關知識
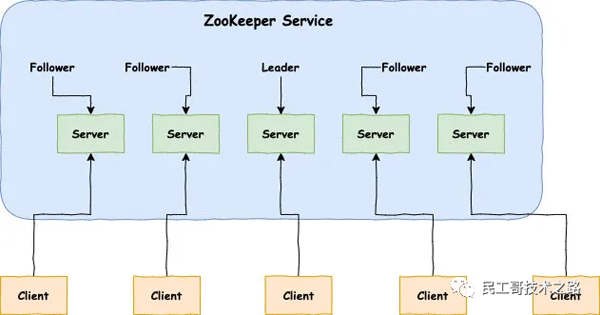
Zookeeper中的角色:
領導者(leader):負責進行投票的發起和決議,更新系統狀態。
跟隨者(follower):用于接收客戶端請求并給客戶端返回結果,在選主過程中進行投票。
觀察者(observer):可以接受客戶端連接,將寫請求轉發給 leader,但是observer 不參加投票的過程,只是為了擴展系統,提高讀取的速度。圖片
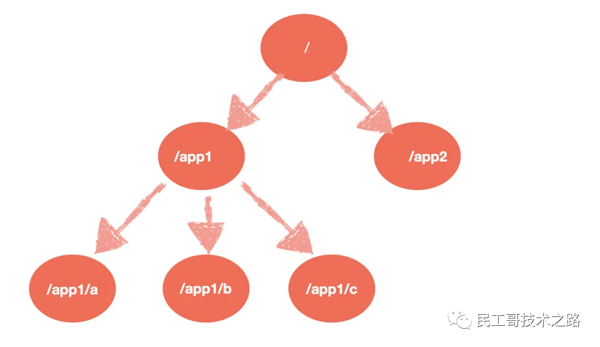
Zookeeper 的數據模型
層次化的目錄結構,命名符合常規文件系統規范,類似于 Linux。
每個節點在 Zookeeper 中叫做 Znode,并且其有一個唯一的路徑標識。
節點 Znode 可以包含數據和子節點,但是 EPHEMERAL 類型的節點不能有子節點。
Znode 中的數據可以有多個版本,比如某一個路徑下存有多個數據版本,那么查詢這個路徑下的數據就需要帶上版本。
客戶端應用可以在節點上設置監視器。
節點不支持部分讀寫,而是一次性完整讀寫。圖片
ZooKeeper 的節點特性
ZooKeeper節點是生命周期的,這取決于節點的類型。在 ZooKeeper 中,節點根據持續時間可以分為持久節點(PERSISTENT)、臨時節點(EPHEMERAL),根據是否有序可以分為順序節點(SEQUENTIAL)、和無序節點(默認是無序的)。
持久節點一旦被創建,除非主動移除,不然一直會保存在 Zookeeper 中(不會因為創建該節點的客戶端的會話失效而消失)。
Zookeeper 的應用場景
ZooKeeper 是一個高可用的分布式數據管理與系統協調框架。基于對 Paxos 算法的實現,使該框架保證了分布式環境中數據的強一致性,也正是基于這樣的特性,使得 ZooKeeper 解決很多分布式問題。
值得注意的是,ZooKeeper 并非天生就是為這些應用場景設計的,都是后來眾多開發者根據其框架的特性,利用其提供的一系列 API 接口(或者稱為原語集),摸索出來的典型使用方法。
數據發布與訂閱(配置中心)
發布與訂閱模型,即所謂的配置中心,顧名思義就是發布者將數據發布到 ZooKeeper 節點上,供訂閱者動態獲取數據,實現配置信息的集中式管理和動態更新。例如全局的配置信息,服務式服務框架的服務地址列表等就非常適合使用。
應用中用到的一些配置信息放到 ZooKeeper 上進行集中管理。這類場景通常是這樣:應用在啟動的時候會主動來獲取一次配置,同時在節點上注冊一個 Watcher。這樣一來,以后每次配置有更新的時候,都會實時通知到訂閱的客戶端,從來達到獲取最新配置信息的目的。
分布式搜索服務中,索引的元信息和服務器集群機器的節點狀態存放在 ZooKeeper 的一些指定節點,供各個客戶端訂閱使用。
分布式日志收集系統
這個系統的核心工作是收集分布在不同機器的日志。收集器通常是按照應用來分配收集任務單元,因此需要在 ZooKeeper 上創建一個以應用名作為 path 的節點 P,并將這個應用的所有機器 IP,以子節點的形式注冊到節點 P 上。這樣一來就能夠實現機器變動的時候,能夠實時通知到收集器調整任務分配。
系統中有些信息需要動態獲取,并且還會存在人工手動去修改這個信息的發問。通常是暴露出接口,例如 JMX 接口,來獲取一些運行時的信息。引入 ZooKeeper 之后,就不用自己實現一套方案了,只要將這些信息存放到指定的 ZooKeeper 節點上即可。
注意:在上面提到的應用場景中,有個默認前提——數據量很小,但是數據更新可能會比較快的場景。
負載均衡
這里說的負載均衡是指軟負載均衡。在分布式環境中,為了保證高可用性,通常同一個應用或同一個服務的提供方都會部署多份,達到對等服務。而消費者就須要在這些對等的服務器中選擇一個來執行相關的業務邏輯,其中比較典型的是消息中間件中的生產者,消費者負載均衡。
命名服務(Naming Service)
命名服務也是分布式系統中比較常見的一類場景。在分布式系統中,通過使用命名服務,客戶端應用能夠根據指定名字來獲取資源或服務的地址,提供者等信息。被命名的實體通常可以是集群中的機器,提供的服務地址,遠程對象等等——這些我們都可以統稱它們為名字(Name)。其中較為常見的就是一些分布式服務框架中的服務地址列表。通過調用 ZooKeeper 提供的創建節點的 API,能夠很容易創建一個全局唯一的path,這個 path 就可以作為一個名字。
阿里巴巴集團開源的分布式服務框架 Dubbo 中使用 ZooKeeper 來作為其命名服務,維護全局的服務地址列表。在 Dubbo 的實現中:
服務提供者在啟動的時候,向 ZooKeeper 上的指定節點 /dubbo/${serviceName}/providers 目錄下寫入自己的 URL 地址,這個操作就完成了服務的發布。
服務消費者啟動的時候,訂閱/dubbo/serviceName/providers目錄下的提供者URL地址,并向/dubbo/{serviceName} /consumers 目錄下寫入自己的 URL 地址。
注意:所有向 ZooKeeper 上注冊的地址都是臨時節點,這樣就能夠保證服務提供者和消費者能夠自動感應資源的變化。
另外,Dubbo 還有針對服務粒度的監控。方法是訂閱 /dubbo/${serviceName} 目錄下所有提供者和消費者的信息。
分布式通知/協調
ZooKeeper 中特有 Watcher 注冊與異步通知機制,能夠很好的實現分布式環境下不同系統之間的通知與協調,實現對數據變更的實時處理。使用方法通常是不同系統都對 ZooKeeper 上同一個 Znode 進行注冊,監聽 Znode 的變化(包括 Znode 本身內容及子節點的),其中一個系統 Update 了 Znode,那么另一個系統能夠收到通知,并作出相應處理。
另一種心跳檢測機制:檢測系統和被檢測系統之間并不直接關聯起來,而是通過 ZooKeeper 上某個節點關聯,大大減少系統耦合。
另一種系統調度模式:某系統有控制臺和推送系統兩部分組成,控制臺的職責是控制推送系統進行相應的推送工作。管理人員在控制臺作的一些操作,實際上是修改了 ZooKeeper 上某些節點的狀態,而 ZooKeeper 就把這些變化通知給它們注冊 Watcher 的客戶端,即推送系統。于是,作出相應的推送任務。
另一種工作匯報模式:一些類似于任務分發系統。子任務啟動后,到 ZooKeeper 來注冊一個臨時節點,并且定時將自己的進度進行匯報(將進度寫回這個臨時節點)。這樣任務管理者就能夠實時知道任務進度。
分布式鎖
分布式鎖主要得益于 ZooKeeper 為我們保證了數據的強一致性。鎖服務可以分為兩類:一類是保持獨占,另一類是控制時序。
所謂保持獨占,就是所有試圖來獲取這個鎖的客戶端,最終只有一個可以成功獲得這把鎖。通常的做法是把 ZooKeeper 上的一個 Znode 看作是一把鎖,通過 create znode的方式來實現。所有客戶端都去創建 /distribute_lock 節點,最終成功創建的那個客戶端也即擁有了這把鎖。
控制時序,就是所有視圖來獲取這個鎖的客戶端,最終都是會被安排執行,只是有個全局時序了。做法和上面基本類似,只是這里 /distribute_lock 已經預先存在,客戶端在它下面創建臨時有序節點(這個可以通過節點的屬性控制:CreateMode.EPHEMERAL_SEQUENTIAL 來指定)。ZooKeeper的父節點(/distribute_lock)維持一份 sequence,保證子節點創建的時序性,從而也形成了每個客戶端的全局時序。
由于同一節點下子節點名稱不能相同,所以只要在某個節點下創建 Znode,創建成功即表明加鎖成功。注冊監聽器監聽此 Znode,只要刪除此 Znode 就通知其他客戶端來加鎖。
創建臨時順序節點:在某個節點下創建節點,來一個請求則創建一個節點,由于是順序的,所以序號最小的獲得鎖,當釋放鎖時,通知下一序號獲得鎖。
分布式隊列
隊列方面,簡單來說有兩種:一種是常規的先進先出隊列,另一種是等隊列的隊員聚齊以后才按照順序執行。對于第一種的隊列和上面講的分布式鎖服務中控制時序的場景基本原理一致,這里就不贅述了。
第二種隊列其實是在 FIFO 隊列的基礎上作了一個增強。通常可以在 /queue 這個 Znode 下預先建立一個 /queue/num 節點,并且賦值為 n(或者直接給 /queue 賦值 n)表示隊列大小。之后每次有隊列成員加入后,就判斷下是否已經到達隊列大小,決定是否可以開始執行了。
這種用法的典型場景是:分布式環境中,一個大任務 Task A,需要在很多子任務完成(或條件就緒)情況下才能進行。這個時候,凡是其中一個子任務完成(就緒),那么就去 /taskList 下建立自己的臨時時序節點(CreateMode.EPHEMERAL_SEQUENTIAL)。當 /taskList 發現自己下面的子節點滿足指定個數,就可以進行下一步按序進行處理了。
使用 dokcer-compose 搭建集群
上面我們介紹了關于 ZooKeeper 有這么多的應用場景,那么接下來就先學習如何搭建 ZooKeeper 集群然后再進行實戰上面的應用場景。
文件的目錄結構如下:
├── docker-compose.yml
編寫 docker-compose.yml 文件
docker-compose.yml 文件內容如下:
version: '3.4' services: zoo1: image: zookeeper restart: always hostname: zoo1 ports: - 2181:2181 environment: ZOO_MY_ID: 1 ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181 zoo2: image: zookeeper restart: always hostname: zoo2 ports: - 2182:2181 environment: ZOO_MY_ID: 2 ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=zoo3:2888:3888;2181 zoo3: image: zookeeper restart: always hostname: zoo3 ports: - 2183:2181 environment: ZOO_MY_ID: 3 ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=0.0.0.0:2888:3888;2181
在這個配置文件中,Docker 運行了 3 個 Zookeeper 鏡像,通過 ports 字段分別將本地的 2181, 2182, 2183 端口綁定到對應容器的 2181 端口上。
ZOO_MY_ID 和 ZOO_SERVERS 是搭建 Zookeeper 集群需要的兩個環境變量。ZOO_MY_ID 標識服務的 id,為 1-255 之間的整數,必須在集群中唯一。ZOO_SERVERS 是集群中的主機列表。
在 docker-compose.yml 所在目錄下執行 docker-compose up,可以看到啟動的日志。
連接 ZooKeeper
將集群啟動起來以后我們可以連接 ZooKeeper 對其進行節點的相關操作。
首先需要下載 ZooKeeper。
將其解壓。
進入其 conf/ 目錄,將 zoo_sample .cfg 改成 zoo.cfg。
配置文件說明
# The number of milliseconds of each tick # tickTime:CS通信心跳數 # Zookeeper 服務器之間或客戶端與服務器之間維持心跳的時間間隔,也就是每個 tickTime 時間就會發送一個心跳。tickTime以毫秒為單位。 tickTime=2000 # The number of ticks that the initial # synchronization phase can take # initLimit:LF初始通信時限 # 集群中的follower服務器(F)與leader服務器(L)之間初始連接時能容忍的最多心跳數(tickTime的數量)。 initLimit=5 # The number of ticks that can pass between # sending a request and getting an acknowledgement # syncLimit:LF同步通信時限 # 集群中的follower服務器與leader服務器之間請求和應答之間能容忍的最多心跳數(tickTime的數量)。 syncLimit=2 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. # dataDir:數據文件目錄 # Zookeeper保存數據的目錄,默認情況下,Zookeeper將寫數據的日志文件也保存在這個目錄里。 dataDir=/data/soft/zookeeper-3.4.12/data # dataLogDir:日志文件目錄 # Zookeeper保存日志文件的目錄。 dataLogDir=/data/soft/zookeeper-3.4.12/logs # the port at which the clients will connect # clientPort:客戶端連接端口 # 客戶端連接 Zookeeper 服務器的端口,Zookeeper 會監聽這個端口,接受客戶端的訪問請求。 clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 # 服務器名稱與地址:集群信息(服務器編號,服務器地址,LF通信端口,選舉端口) # 這個配置項的書寫格式比較特殊,規則如下: # server.N=YYY:A:B # 其中N表示服務器編號,YYY表示服務器的IP地址,A為LF通信端口,表示該服務器與集群中的leader交換的信息的端口。B為選舉端口,表示選舉新leader時服務器間相互通信的端口(當leader掛掉時,其余服務器會相互通信,選擇出新的leader)。一般來說,集群中每個服務器的A端口都是一樣,每個服務器的B端口也是一樣。但是當所采用的為偽集群時,IP地址都一樣,只能時A端口和B端口不一樣。
可以不修改 zoo.cfg,使用默認配置。接下來在解壓后的 bin/ 目錄中執行命令 ./zkCli.sh -server 127.0.0.1:2181 就能進行連接了。
Welcome to ZooKeeper! 2020-06-01 15:03:52,512 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1025] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) JLine support is enabled 2020-06-01 15:03:52,576 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@879] - Socket connection established to localhost/127.0.0.1:2181, initiating session 2020-06-01 15:03:52,599 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x100001140080000, negotiated timeout = 30000 WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: 127.0.0.1:2181(CONNECTED) 0]
接下來可以使用命令查看節點:
使用 ls 命令查看當前 ZooKeeper 中所包含的內容。命令:ls /
[zk: 127.0.0.1:2181(CONNECTED) 10] ls / [zookeeper]
創建了一個新的 znode 節點 zk 以及與它關聯的字符串。命令:create /zk myData
[zk: 127.0.0.1:2181(CONNECTED) 11] create /zk myData Created /zk [zk: 127.0.0.1:2181(CONNECTED) 12] ls / [zk, zookeeper] [zk: 127.0.0.1:2181(CONNECTED) 13]
獲取 znode 節點 zk。命令:get /zk
[zk: 127.0.0.1:2181(CONNECTED) 13] get /zk myData cZxid = 0x400000008 ctime = Mon Jun 01 15:07:50 CST 2020 mZxid = 0x400000008 mtime = Mon Jun 01 15:07:50 CST 2020 pZxid = 0x400000008 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 6 numChildren = 0
刪除 znode 節點 zk。命令:delete /zk
[zk: 127.0.0.1:2181(CONNECTED) 14] delete /zk [zk: 127.0.0.1:2181(CONNECTED) 15] ls / [zookeeper]
關于便捷搭建Zookeeper服務器的方法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





