溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Java如何用poi完成Excel導出數據脫敏”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Java如何用poi完成Excel導出數據脫敏”吧!
脫敏的百度百科的定義:是指對某些敏感信息通過脫敏規則進行數據的變形,實現敏感隱私數據的可靠保護。在涉及客戶安全數據或者一些商業性敏感數據的情況下,在不違反系統規則條件下,對真實數據進行改造并提供測試使用,如身份證號、手機號、卡號、客戶號等個人信息都需要進行數據脫敏。
這塊如果嚴格按照定義,實現身份證等數據的變形,筆者還沒實現,因為這個設計脫敏規則對應,需要用戶指定規則,我們內部的脫敏系統還是有些邏輯在的,這里就不細說了,這次主要實現的是加*號【后期再加自定義吧,畢竟常見的都是星號】,方便導出數據的時候隱藏非必須字段。
維護數據
實現的功能主要分為三種:
1. 隱去收尾,適合固定長度,比如:手機號,身份證
2. 隱去部分,不固定長度,比如:姓名,地址
3. 隱去特定部分,特別表示保留,比如:郵箱
簡單地實現的效果為
13112345678 --> 131****1234
張三 -->張*
羅納爾迪尼奧 --> 羅納***奧
wuyun@163.com -> w****@16com.com
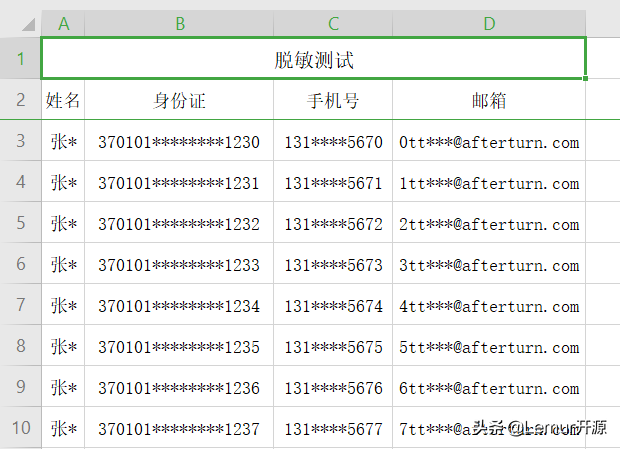
脫敏效果
注解還是通過@Excel 的屬性來實現的 ,在@Excel 這個地方加入了desensitizationRule屬性,可以在desensitizationRule屬性配置對應的格式遍可以得到對應的結果
/** * 數據脫敏規則 * 規則1: 采用保留頭和尾的方式,中間數據加星號 * 如: 身份證 6_4 則保留 370101********1234 * 手機號 3_4 則保留 131****1234 * 規則2: 采用確定隱藏字段的進行隱藏,優先保留頭 * 如: 姓名 1,3 表示最大隱藏3位,最小一位 * 李 --> * * 李三 --> 李* * 張全蛋 --> 張*蛋 * 李張全蛋 --> 李**蛋 * 尼古拉斯.李張全蛋 -> 尼古拉***張全蛋 * 規則3: 特殊符號后保留 * 如: 郵箱 1~@ 表示只保留第一位和@之后的字段 * afterturn@wupaas.com -> a********@wupaas.com * 復雜版本請使用接口 * {@link cn.afterturn.easypoi.handler.inter.IExcelDataHandler} */ public String desensitizationRule() default "";可以根據注釋看到,3個簡單規則的使用方法,還是比較清晰的,主要是:
用下劃線分隔的保留頭尾的第一種格式
該格式首和尾都可以是0,表示不保留
用逗號分隔的隱藏部分數據的第二種格式
保留規則以對稱為主
用~號來區分的,保留特殊字符后的格式的
如果存在多個特殊字符,只保留最后一位的數據
具體實現代碼如下:
/** * 特定字符分隔,添加星號 * @param start * @param mark * @param value * @return */ private static String markSpilt(int start, String mark, String value) { if (value == null) { return null; } int end = value.lastIndexOf(mark); if (end <= start) { return value; } return StringUtils.left(value, start).concat(StringUtils.leftPad(StringUtils.right(value, value.length() - end), value.length() - start, "*")); } /** * 部分數據截取,優先對稱截取 * @param start * @param end * @param value * @return */ private static String subMaxString(int start, int end, String value) { if (value == null) { return null; } if (start > end) { throw new IllegalArgumentException("start must less end"); } int len = value.length(); if (len <= start) { return StringUtils.leftPad("", len, "*"); } else if (len > start && len <= end) { if (len == 1) { return value; } if (len == 2) { return StringUtils.left(value, 1).concat("*"); } return StringUtils.left(value, 1).concat(StringUtils.leftPad(StringUtils.right(value, 1), StringUtils.length(value) - 1, "*")); } else { start = (int) Math.ceil((len - end + 0.0D) / 2); end = len - start - end; end = end == 0 ? 1 : end; return StringUtils.left(value, start).concat(StringUtils.leftPad(StringUtils.right(value, end), len - start, "*")); } } /** * 收尾截取數據 * @param start * @param end * @param value * @return */ private static String subStartEndString(int start, int end, String value) { if (value == null) { return null; } if (value.length() <= start + end) { return value; } return StringUtils.left(value, start).concat(StringUtils.leftPad(StringUtils.right(value, end), StringUtils.length(value) - start, "*")); }使用起來也比較簡單,通過簡單的注解配置,就可以實現
@Excel(name = "姓名", desensitizationRule = "1,6") private String name; @Excel(name = "身份證", desensitizationRule = "6_4") private String card; @Excel(name = "手機號", desensitizationRule = "3_4") private String phone; @Excel(name = "郵箱", desensitizationRule = "3~@") private String email; // ---------------下面是生成excel的代碼------- // 都是測試數據,就簡單生成了部分 List<DesensitizationEntity> list = new ArrayList<>(); for (int i = 0; i < 20; i++) { DesensitizationEntity entity = new DesensitizationEntity(); entity.setCard("37010119900101123" + i % 10); entity.setName("張三"); entity.setPhone("1311234567" + i % 10); entity.setEmail(i % 10 + "ttttt@afterturn.com"); list.add(entity); } Date start = new Date(); ExportParams params = new ExportParams("脫敏測試", "脫敏測試", ExcelType.XSSF); Workbook workbook = ExcelExportUtil.exportExcel(params, DesensitizationEntity.class, list); System.out.println(new Date().getTime() - start.getTime()); File savefile = new File("D:/home/excel/"); if (!savefile.exists()) { savefile.mkdirs(); } FileOutputStream fos = new FileOutputStream("D:/home/excel/ExcelDesensitizationTest.xlsx"); workbook.write(fos); fos.close();生成的效果如下,可以看到幾個場景都有所覆蓋,基本上常用的字段也就
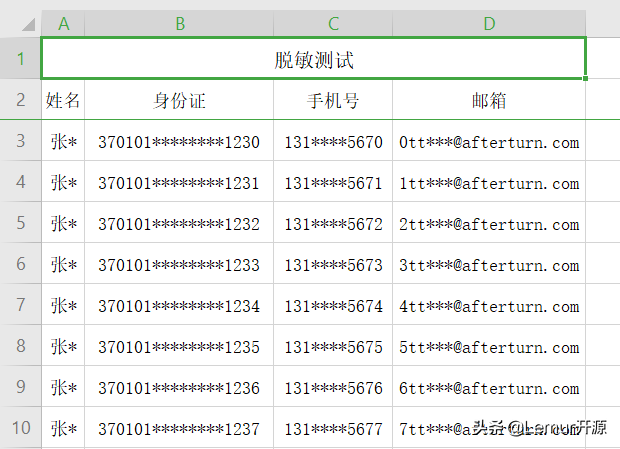
PS: 因為變種注解和注解可以通用,所以大家在使用變種注解的時候也可以使用這種方式來脫敏數據。
這里就不舉例子了,只需要new ExcelExportEntity的之后調用setDesensitizationRule(rule),把對應的規則設置就好,規則和上面保持一致。
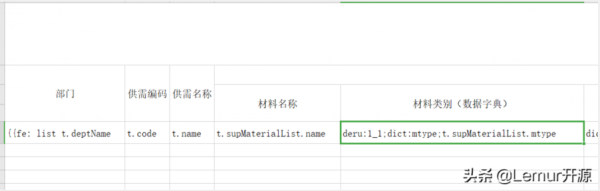
模板脫敏
目前從群里反應和問題數量看,模板已經是最常用的方式了,雖然我一致推薦注解,但明顯模板比注解簡單的,對代碼的侵入一些,我自己寫的特殊標簽,也日益豐富了。
脫敏的標簽取自:desensitizationRule 的兩個單詞的頭兩個字符 deru,用來表示這個數據需要脫敏。使用方法也比較簡單deru:1_3,即deru:后面跟具體的規則,規則使用方式和上面介紹的 保持一致,這里就不重復贅述了,下面給大家看下例子:
/** * 這個包含兩個規則 * 1. deru: 代表這個數據需要脫敏 * 2. dict: 代表這個需要調用字典接口轉移 **/ deru:1_1;dict:mtype;t.supMaterialList.mtype
脫敏在標簽處理級別中屬于最低級,所有標簽處理后,才會處理這個標簽,和他的書寫順序無關,比如上面的例子他寫著第一個,也是先處理了字典之后才處理標簽。
核心代碼如下:
/** * 根據模板解析函數獲取值 * @param funStr * @param map * @return */ private Object getValByHandler(String funStr,Map<String, Object> map, Cell cell) throws Exception { // step 2. 判斷是否含有解析函數 if (isHasSymbol(funStr, NUMBER_SYMBOL)) { funStr = funStr.replaceFirst(NUMBER_SYMBOL, ""); } boolean isStyleBySelf = false; if (isHasSymbol(funStr, STYLE_SELF)) { isStyleBySelf = true; funStr = funStr.replaceFirst(STYLE_SELF, ""); } boolean isDict = false; String dict = null; if (isHasSymbol(funStr, DICT_HANDLER)) { isDict = true; dict = funStr.substring(funStr.indexOf(DICT_HANDLER) + 5).split(";")[0]; funStr = funStr.replaceFirst(DICT_HANDLER, ""); funStr = funStr.replaceFirst(dict + ";", ""); } boolean isI18n = false; if (isHasSymbol(funStr, I18N_HANDLER)) { isI18n = true; funStr = funStr.replaceFirst(I18N_HANDLER, ""); } //這里判斷是否包含注解規則,如果有注解規則就把注解規則挑出來,然后刪除掉規則 boolean isDern = false; String dern = null; if (isHasSymbol(funStr, DESENSITIZATION_RULE)) { isDern = true; dern = funStr.substring(funStr.indexOf(DESENSITIZATION_RULE) + 5).split(";")[0]; funStr = funStr.replaceFirst(DESENSITIZATION_RULE, ""); funStr = funStr.replaceFirst(dern + ";", ""); } if (isHasSymbol(funStr, MERGE)) { String mergeStr = PoiPublicUtil.getElStr(funStr,MERGE); funStr = funStr.replace(mergeStr, ""); mergeStr = mergeStr.replaceFirst(MERGE, ""); try { int colSpan = (int)Double.parseDouble(PoiPublicUtil.getRealValue(mergeStr, map).toString()); PoiMergeCellUtil.addMergedRegion(cell.getSheet(), cell.getRowIndex(), cell.getRowIndex() , cell.getColumnIndex(), cell.getColumnIndex() + colSpan - 1); } catch (Exception e) { LOGGER.error(e.getMessage(),e); } } Object obj = funStr.indexOf(START_STR) == -1 ? eval(funStr, map) : PoiPublicUtil.getRealValue(funStr, map); if (isDict) { obj = dictHandler.toName(dict, null, funStr, obj); } if (isI18n) { obj = i18nHandler.getLocaleName(obj.toString()); } // 這里就是調用脫敏規則,和注解是一個工具類,所以規則一致 if (isDern) { obj = PoiDataDesensitizationUtil.desensitization(dern,obj); } return obj; }給大家看下模板跑出來的效果:
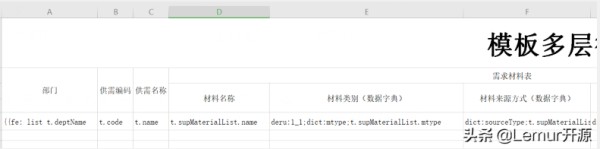
最后結果
感謝各位的閱讀,以上就是“Java如何用poi完成Excel導出數據脫敏”的內容了,經過本文的學習后,相信大家對Java如何用poi完成Excel導出數據脫敏這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





