溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python中怎么編寫Unix管道,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
一個日志處理任務
應用場景如下:
◆ 某個目錄及子目錄下有一些 web 服務器的日志文件,日志文件名以 access-log 開頭
◆ 日志格式如下
81.107.39.38 - ... "GET /ply/ply.html HTTP/1.1" 200 97238 81.107.39.38 - ... "GET /ply HTTP/1.1" 304 - |
其中***一列數字為發送的字節數,若為 ‘-’ 則表示沒有發送數據
◆目標是算出總共發送了多少字節的數據,實際上也就是要把日志記錄的沒一行的***一列數值加起來
我不直接展示如何用 Unix 管道的風格來處理這個問題,而是先給出一些“不那么好”的代碼,指出它們的問題,***再展示管道風格的代碼,并介紹如何使用 generator 來避免效率上的問題。
問題并不復雜,幾個 for 循環就能搞定:
sum = 0 for path, dirlist, filelist in os.walk(top): for name in fnmatch.filter(filelist, "access-log*"): # 對子目錄中的每個日志文件進行處理 with open(name) as f: for line in f: if line[-1] == '-': continue else: sum += int(line.rsplit(None, 1)[1]) |
利用 os.walk 這個問題解決起來很方便,由此也可以看出 python 的 for 語句做遍歷是多么的方便,不需要額外控制循環次數的變量,省去了設置初始值、更新、判斷循環結束條件等工作,相比 C/C++/Java 這樣的語言真是太方便了。看起來一切都很美好。
然而,設想以后有了新的統計任務,比如:
1.統計某個特定頁面的訪問次數
2.處理另外的一些日志文件,日志文件名字以 error-log 開頭
完成這些任務直接拿上面的代碼過來改改就可以了,文件名的 pattern 改一下,處理每個文件的代碼改一下。其實每次任務的處理中,找到特定名字為特定 pattern 的文件的代碼是一樣的,直接修改之前的代碼其實就引入了重復。
如果重復的代碼量很大,我們很自然的會注意到。然而 python 的 for 循環實在太方便了,像這里找文件的代碼一共就兩行,哪怕重寫一遍也不會覺得太麻煩。for 循環的方便使得我們會忽略這樣簡單代碼的重復。然而,再怎么方便好用,for 循環無法重用,只有把它放到函數中才能進行重用。
(先考慮下是你會如何避免這里的代碼的重復。下面馬上出現的代碼并不好,是“誤導性”的代碼,我會在之后再給出“更好”的代碼。)
因此,我們把上面代碼中不變的部分提取成一個通用的函數,可變的部分以參數的形式傳入,得到下面的代碼:
def generic_process(topdir, filepat, processfunc):
for path, dirlist, filelist in os.walk(top):
for name in fnmatch.filter(filelist, filepat):
with open(name) f:
processfunc(f)
sum = 0
# 很遺憾,python 對 closure 中的變量不能進行賦值操作,
# 因此這里只能使用全局變量
def add_count(f):
global sum
for line in f:
if line[-1] == '-':
continue
else:
sum += int(line.rsplit(None, 1)[1])
generic_process('logdir', 'access-log*', add_count) |
看起來不變和可變的部分分開了,然而 generic_process 的設計并不好。它除了尋找文件以外還調用了日志文件處理函數,因此在其他任務中很可能就無法使用。另外 add_count 的參數必須是 file like object,因此測試時不能簡單的直接使用字符串。
管道風格的程序
下面考慮用 Unix 的工具和管道我們會如何完成這個任務:
find logdir -name "access-log*" | \
xargs cat | \
grep '[^-]$' | \
awk '{ total += $NF } END { print total }' |
find 根據文件名 pattern 找到文件,cat 把所有文件內容合并輸出到 stdout,grep 從 stdin 讀入,過濾掉行末為 ‘-’ 的行,awk 提取每行***一列,將數值相加,***打印出結果。(省掉 cat 是可以的,但這樣一來 grep 就需要直接讀文件而不是只從標準輸入讀。)
我們可以在 python 代碼中模擬這些工具,Unix 的工具通過文本來傳遞結果,在 python 中可以使用 list。
def find(topdir, filepat, processfunc):
files = []
for path, dirlist, filelist in os.walk(top):
for name in fnmatch.filter(filelist, filepat):
files.append(name)
return files
def cat(files):
lines = []
for file in files:
with open(file) as f:
for line in f:
lines.append(line)
return lines
def grep(pattern, lines):
result = []
import re
pat = re.compile(pattern)
for line in lines:
if pat.search(line):
result.append(line)
resurn result
lines = grep('[^-]$', cat(find('logdir', 'access-log*')))
col = (line.rsplit(None, 1)[1] for line in lines)
print sum(int(c) for c in col) |
有了 find, cat, grep 這三個函數,只需要連續調用就可以像 Unix 的管道一樣將這些函數組合起來。數據在管道中的變化如下圖(簡潔起見,過濾器直接標在箭頭上 ):
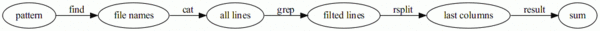
看起來現在的代碼行數比最初直接用 for 循環的代碼要多,但現在的代碼就像 Unix 的那些小工具一樣,每一個都更加可能被用到。我們可以把更多常用的 Unix 工具用 Python 來模擬,從而在 Python 代碼中以 Unix 管道的風格來編寫代碼。
關于Python中怎么編寫Unix管道就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





