溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“帶你了解HTTP黑科技”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“帶你了解HTTP黑科技”吧!
HTTP 內容協商
什么是內容協商
在 HTTP 中,內容協商是一種用于在同一 URL 上提供資源的不同表示形式的機制。內容協商機制是指客戶端和服務器端就響應的資源內容進行交涉,然后提供給客戶端最為適合的資源。內容協商會以響應資源的語言、字符集、編碼方式等作為判斷的標準。
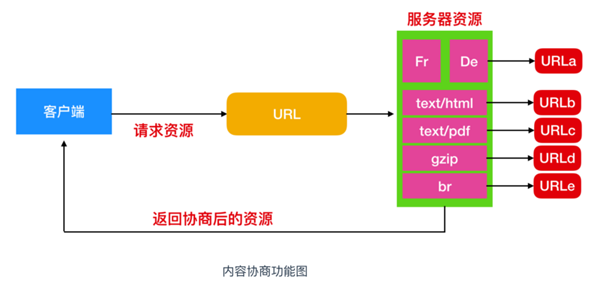
內容協商的種類
內容協商主要有以下3種類型:
服務器驅動協商(Server-driven Negotiation)
這種協商方式是由服務器端進行內容協商。服務器端會根據請求首部字段進行自動處理
客戶端驅動協商(Agent-driven Negotiation)
這種協商方式是由客戶端來進行內容協商。
透明協商(Transparent Negotiation)
是服務器驅動和客戶端驅動的結合體,是由服務器端和客戶端各自進行內容協商的一種方法。
內容協商的分類有很多種,主要的幾種類型是 Accept、Accept-Charset、Accept-Encoding、Accept-Language、Content-Language。
一般來說,客戶端用 Accept 頭告訴服務器希望接收什么樣的數據,而服務器用 Content 頭告訴客戶端實際發送了什么樣的數據。
為什么需要內容協商
我們為什么需要內容協商呢?在回答這個問題前我們先來看一下 TCP 和 HTTP 的不同。
在 TCP / IP 協議棧里,傳輸數據基本上都是 header+body 的格式。但 TCP、UDP 因為是傳輸層的協議,它們不會關心 body 數據是什么,只要把數據發送到對方就算是完成了任務。
而 HTTP 協議則不同,它是應用層的協議,數據到達之后需要告訴應用程序這是什么數據。當然不告訴應用這是哪種類型的數據,應用也可以通過不斷嘗試來判斷,但這種方式無疑十分低效,而且有很大幾率會檢查不出來文件類型。
所以鑒于此,瀏覽器和服務器需要就數據的傳輸達成一致,瀏覽器需要告訴服務器自己希望能夠接收什么樣的數據,需要什么樣的壓縮格式,什么語言,哪種字符集等;而服務器需要告訴客戶端自己能夠提供的服務是什么。
所以我們就引出了內容協商的幾種概念,下面依次來進行探討
內容協商標頭
Accept
接受請求 HTTP 標頭會通告客戶端自己能夠接受的 MIME 類型
那么什么是 MIME 類型呢?在回答這個問題前你應該先了解一下什么是 MIME
MIME: MIME (Multipurpose Internet Mail Extensions) 是描述消息內容類型的因特網標準。MIME 消息能包含文本、圖像、音頻、視頻以及其他應用程序專用的數據。
也就是說,MIME 類型其實就是一系列消息內容類型的集合。那么 MIME 類型都有哪些呢?
文本文件: text/html、text/plain、text/css、application/xhtml+xml、application/xml
圖片文件: image/jpeg、image/gif、image/png
視頻文件: video/mpeg、video/quicktime
應用程序二進制文件: application/octet-stream、application/zip
比如,如果瀏覽器不支持 PNG 圖片的顯示,那 Accept 就不指定image/png,而指定可處理的 image/gif 和 image/jpeg 等圖片類型。
一般 MIME 類型也會和 q 這個屬性一起使用,q 是什么?q 表示的是權重,來看一個例子
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
這是什么意思呢?若想要給顯示的媒體類型增加優先級,則使用 q= 來額外表示權重值,沒有顯示權重的時候默認值是1.0 ,我給你列個表格你就明白了
| q | MIME |
|---|---|
| 1.0 | text/html |
| 1.0 | application/xhtml+xml |
| 0.9 | application/xml |
| 0.8 | / |
也就是說,這是一個放置順序,權重高的在前,低的在后,application/xml;q=0.9 是不可分割的整體。
Accept-Charset
Accept-charset 屬性規定服務器處理表單數據所接受的字符編碼;Accept-charset 屬性允許你指定一系列字符集,服務器必須支持這些字符集,從而得以正確解釋表單中的數據。
Accept-Charset 沒有對應的標頭,服務器會把這個值放在 Content-Type中用 charset=xxx來表示,
例如,瀏覽器請求 GBK 或 UTF-8 的字符集,然后服務器返回的是 UTF-8 編碼,就是下面這樣
Accept-Charset: gbk, utf-8 Content-Type: text/html; charset=utf-8
Accept-Language
首部字段 Accept-Language 用來告知服務器用戶代理能夠處理的自然語言集(指中文或英文等),以及自然語言集的相對優先級。可一次指定多種自然語言集。和 Accept 首部字段一樣,按權重值 q= 來表示相對優先級。
Accept-Language: en-US,en;q=0.5
Accept-Encoding
表示 HTTP 標頭會標明客戶端希望服務端返回的內容編碼,這通常是一種壓縮算法。Accept-Encoding 也是屬于內容協商 的一部分,使用并通過客戶端選擇 Content-Encoding 內容進行返回。
即使客戶端和服務器都能夠支持相同的壓縮算法,服務器也可能選擇不壓縮并返回,這種情況可能是由于這兩種情況造成的:
要發送的數據已經被壓縮了一次,第二次壓縮并不會導致發送的數據更小
服務器過載,無法承受壓縮帶來的性能開銷,通常,如果服務器使用 CPU 超過 80% ,Microsoft 則建議不要使用壓縮
下面是 Accept-Encoding 的使用方式
Accept-Encoding: gzip Accept-Encoding: compress Accept-Encoding: deflate Accept-Encoding: br Accept-Encoding: identity Accept-Encoding: * Accept-Encoding: deflate, gzip;q=1.0, *;q=0.5
上面的幾種表述方式就已經把 Accept-Encoding 的屬性列全了
gzip: 由文件壓縮程序 gzip 生成的編碼格式,使用 Lempel-Ziv編碼(LZ77)和32位CRC的壓縮格式,感興趣的同學可以讀一下 (https://en.wikipedia.org/wiki...)
compress: 使用Lempel-Ziv-Welch(LZW)算法的壓縮格式,有興趣的同學可以讀 (https://en.wikipedia.org/wiki...)
deflate: 使用 zlib 結構和 deflate 壓縮算法的壓縮格式,參考 (https://en.wikipedia.org/wiki...) 和 (https://en.wikipedia.org/wiki...)
br: 使用 Brotli 算法的壓縮格式,參考 (https://en.wikipedia.org/wiki...)
不執行壓縮或不會變化的默認編碼格式
* : 匹配標頭中未列出的任何內容編碼,如果沒有列出 Accept-Encoding ,這就是默認值,并不意味著支
持任何算法,只是表示沒有偏好
;q= 采用權重 q 值來表示相對優先級,這點與首部字段 Accept 相同。
Content-Type
Content-Type 實體標頭用于指示資源的 MIME 類型。作為響應,Content-Type 標頭告訴客戶端返回的內容的內容類型實際上是什么。Content-type 有兩種值 : MIME 類型和字符集編碼,例如
Content-Type: text/html; charset=UTF-8
在某些情況下,瀏覽器將執行 MIME 嗅探,并且不一定遵循此標頭的值;為防止此行為,可以將標頭 X-Content-Type-Options 設置為 nosniff。
Content-Encoding
Content-Encoding 實體標頭用于壓縮媒體類型,它讓客戶端知道如何進行解碼操作,從而使客戶端獲得 Content-Type 標頭引用的 MIME 類型。表示如下
Content-Encoding: gzip Content-Encoding: compress Content-Encoding: deflate Content-Encoding: identity Content-Encoding: br Content-Encoding: gzip, identity Content-Encoding: deflate, gzip
Content-Language
Content-Language 實體標頭用于描述面向受眾的語言,以便使用戶根據用戶自己的首選語言進行區分。例如
Content-Language: de-DE Content-Language: en-US Content-Language: de-DE, en-CA
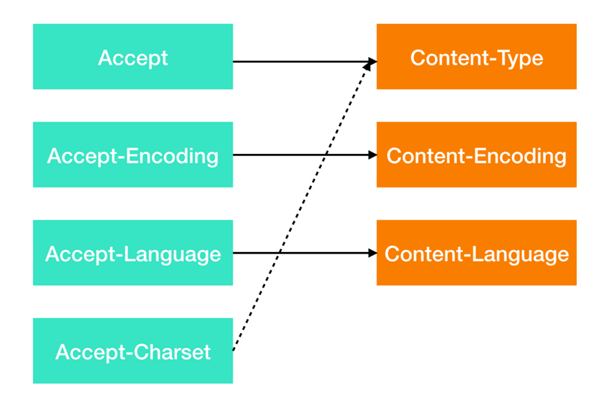
下面根據內容協商對應的請求/響應標頭,我列了一張圖供你參考,注意其中 Accept-Charset 沒有對應的 Content-Charset ,而是通過 Content-Type 來表示。
HTTP 認證
HTTP 提供了用于訪問控制和身份認證的功能,下面就對 HTTP 的權限和認證功能進行介紹
通用 HTTP 認證框架
RFC 7235 定義了 HTTP 身份認證框架,服務器可以根據其文檔的定義來檢查客戶端請求。客戶端也可以根據其文檔定義來提供身份驗證信息。
請求/響應的工作流程如下:服務器以401(未授權) 的狀態響應客戶端告訴客戶端服務器需要認證信息,客戶端提供至少一個 www-Authenticate 的響應標頭進行授權信息的認證。想要通過服務器進行身份認證的客戶端可以在請求標頭字段中添加認證標頭進行身份認證,一般的認證過程如下

首先客戶端發起一個 HTTP 請求,不帶有任何認證標頭,服務器對此 HTTP 請求作出響應,發現此 HTTP 信息未帶有認證憑據,服務器通過 www-Authenticate標頭返回 401 告訴客戶端此請求未通過認證。然后客戶端進行用戶認證,認證完畢后重新發起 HTTP 請求,這次 HTTP 請求帶有用戶認證憑據(注意,整個身份認證的過程必須通過 HTTPS 連接保證安全),到達服務器后服務器會檢查認證信息,如果不符合服務器認證信息,會返回 403 Forbidden 表示用戶認證失敗,如果滿足認證信息,則返回 200 OK。
我們知道,客戶端和服務器之間的 HTTP 連接可以被代理緩存重新發送,所以認證信息也適用于代理服務器。
代理認證
由于資源認證和代理認證可以共存,因此需要不同的頭和狀態碼,在代理的情況下,會返回狀態碼 407(需要代理認證), Proxy-Authenticate 響應頭包含至少一個適用于代理的情況,Proxy-Authorization請求頭用于將證書提供給代理服務器。下面分別來認識一下這兩個標頭
Proxy-Authenticate
HTTP Proxy-Authenticate 響應標頭定義了身份驗證方法,應使用該身份驗證方法來訪問代理服務器后面的資源。它將請求認證到代理服務器,從而允許它進一步發送請求。例如
Proxy-Authenticate: Basic Proxy-Authenticate: Basic realm="Access to the internal site"
Proxy-Authorization
這個 HTTP 請求標頭和上面的 Proxy-Authenticate 拼接很相似,但是概念不同,這個標頭用于向代理服務器提供憑據,例如
Proxy-Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
下面是代理服務器的請求/響應認證過程

這個過程和通用的過程類似,我們就不再詳細展開描述了。
禁止訪問
如果代理服務器收到的有效憑據不足以獲取對給定資源的訪問權限,則服務器應使用403 Forbidden狀態代碼進行響應。與 401 Unauthorized 和 407 Proxy Authorization Required 不同,該用戶無法進行身份驗證。
WWW-Authenticate 和 Proxy-Authenticate 頭
WWW-Authenticate 和 Proxy-Authenticate 響應頭定義了獲得對資源訪問權限的身份驗證方法。他們需要指定使用哪種身份驗證方案,以便希望授權的客戶端知道如何提供憑據。它們的一般表示形式如下
WWW-Authenticate: <type> realm=<realm> Proxy-Authenticate: <type> realm=<realm>
我想你從上面看到這里一定會好奇 <type> 和 realm是什么東西,現在就來解釋下。
<type> 是認證協議,Basic 是下面協議中最普遍使用的
RFC 7617 中定義了Basic HTT P身份驗證方案,該方案將憑據作為用戶ID /密碼對傳輸,并使用 base64 進行編碼。(感興趣的同學可以看看 https://tools.ietf.org/html/r...
其他的認證協議主要有
| 認證協議 | 參考來源 |
|---|---|
| Basic | 查閱 RFC 7617,base64編碼的憑據 |
| Bearer | 查閱 RFC 6750,承載令牌來訪問受 OAuth 2.0保護的資源 |
| Digest | 查閱 RFC 7616,Firefox僅支持md5哈希,請參見錯誤bug 472823以獲得SHA加密支持 |
| HOBA | 查閱 RFC 7486 |
| Mutual | 查閱 RFC 8120 |
| AWS4-HMAC-SHA256 | 查閱 AWS docs |
AWS4-HMAC-SHA256 查閱 AWS docs
realm 用于描述保護區或指示保護范圍,這可能是諸如 Access to the staging site(訪問登陸站點) 或者類似的,這樣用戶就可以知道他們要訪問哪個區域。
Authorization 和 Proxy-Authorization 標頭
Authorization 和 Proxy-Authorization 請求標頭包含用于通過代理服務器對用戶代理進行身份驗證的憑據。在此,再次需要類型,其后是憑據,取決于使用哪種身份驗證方案,可以對憑據進行編碼或加密。一般表示如下
Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l Proxy-Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
HTTP 緩存
通過把請求/響應緩存起來有助于提升系統的性能,Web 緩存減少了延遲和網絡傳輸量,因此減少資源獲取鎖需要的時間。由于鏈路漫長,網絡時延不可控,瀏覽器使用 HTTP 獲取資源的成本較高。所以,非常有必要把數據緩存起來,下次再請求的時候盡可能地復用。當 Web 緩存在其存儲中具有請求的資源時,它將攔截該請求并直接返回資源,而不是到達源服務器重新下載并獲取。這樣做可以實現兩個小目標
減輕服務器負載
提升系統性能
下面我們就一起來探討一下 HTTP 緩存都有哪些
不同類型的緩存
HTTP 緩存有幾種不同的類型,這些可以分為兩個主要類別:私有緩存 和 共享緩存。
共享緩存:共享緩存是一種緩存,它可以存儲多個用戶重復使用的請求/響應。
私有緩存:私有緩存也稱為專用緩存,它只適用于單個用戶。
不緩存過期資源:所有的請求都會直接到達服務器,由服務器來下載資源并返回。
我們主要探討瀏覽器緩存和代理緩存,但真實情況不只有這兩種緩存,還有網關緩存,CDN,反向代理緩存和負載平衡器,把它們部署在 Web 服務器上,可以提高網站和 Web 應用程序的可靠性,性能和可伸縮性。
不緩存過期資源
不緩存過期資源即瀏覽器和代理不會緩存過期資源,客戶端發起的請求會直接到達服務器,可以使用 no-cache 標頭代表不緩存過期資源。
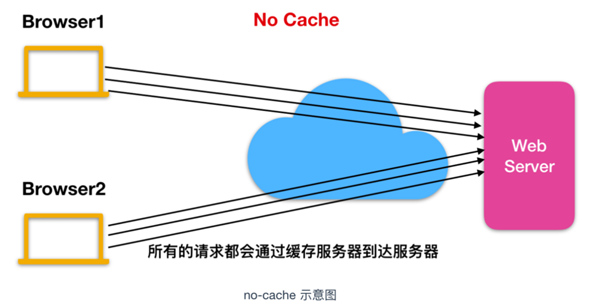
no-cache 屬于 Cache-Control 通用標頭,其一般的表示方法如下
Cache-Control: no-cache
也可以使用 max-age = 0 來實現不緩存的效果。
Cache-Control: max-age=0
私有緩存
私有緩存只用來緩存單個用戶,你可能在瀏覽器設置中看到了 緩存,瀏覽器緩存包含服務器通過 HTTP 下載下來的所有文檔。這個高速緩存用于使訪問的文檔可以進行前進/后退,保存操作而無需重新發送請求到源服務器。
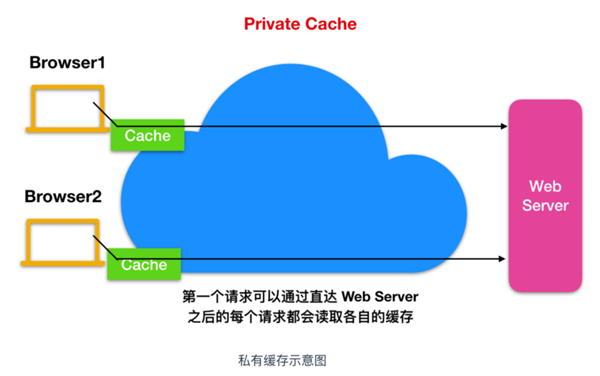
可以使用 private 來實現私有緩存,這與 public 的用法相反,緩存服務器只對特定的客戶端進行緩存,其他客戶端發送過來的請求,緩存服務器則不會返回緩存。它的一般表示方法如下
Cache-Control: private
共享緩存
共享緩存是一種用于存儲要由多個用戶重用的響應緩存。共享緩存一般使用 public 來表示,public 屬性只出現在客戶端響應中,表示響應可以被任何緩存所緩存。一般表示方法如下
Cache-Control: public
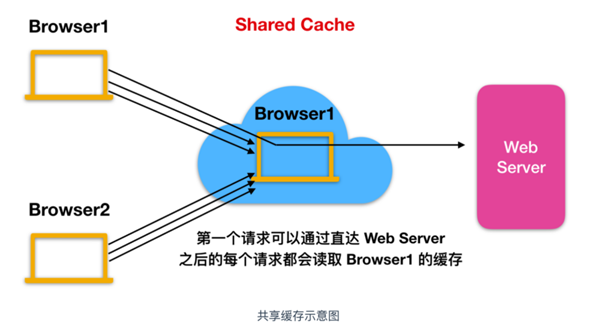
緩存控制
HTTP/1.1 中的 Cache-Control 常規標頭字段用于執行緩存控制,使用此標頭可通過其提供的各種指令來定義緩存策略。下面我們依次介紹一下這些屬性
不緩存
no-store 才是真正意義上的不緩存,每次服務器接受到客戶端的請求后,都會返回最新的資源給客戶端。
Cache-Control: no-store
緩存但需要驗證
同上面的 不緩存過期資源
私有和共享緩存
同上
緩存過期
緩存中一個很重要的指令就是max-age,這是資源被視為新鮮的最長時間 ,與 Expires 相反,此指令是相對于請求時間的。對于應用程序中不會更改的文件,通常可以添加主動緩存。下面是 mag-age 的表示
Cache-Control: max-age=31536000
緩存驗證
must-revalidate 表示緩存必須在使用之前驗證過時資源的狀態,并且不應使用過期的資源。
Cache-Control: must-revalidate
下面是一個緩存驗證圖

什么是新鮮的數據
一旦資源存儲在緩存中,理論上就可以永遠被緩存使用。但是不管是瀏覽器緩存還是代理緩存,其存儲空間是有限的,所以緩存會定期進行清除,這個過程叫做 緩存回收(cache eviction) (自譯)。另一方面,服務器上的緩存也會定期進行更新,HTTP 作為應用層的協議,它是一種客戶-服務器模式,HTTP 是無狀態的協議,因此當資源發生更改時,服務器無法通知緩存和客戶端。因此服務器必須通過某種方式告知客戶端緩存已經被更新。服務器會提供過期時間這個概念,告知客戶端在此到期時間之前,資源是新鮮的,也就是未更改過的。在此到期時間的范圍之外,資源已過時。過期算法(Eviction algorithms) 通常會將新資源優先于陳舊資源使用。
這里需要注意一下,過期的資源并不會被回收或忽略,當高速緩存接收到過期資源時,它會使用 If-None-Match 轉發此請求,以檢查它是否仍然有效。如果有效,服務器會返回 304 Not Modified響應頭并且沒有任何響應體,從而節省了一些帶寬。
下面是使用共享緩存代理的過程
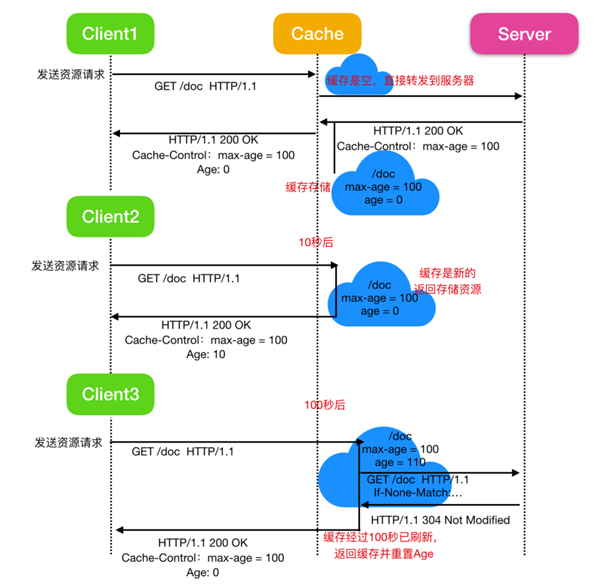
這個圖應該比較好理解,只說一下 Age 的作用,Age 是 HTTP 響應標頭告訴客戶端源服務器在多久之前創建了響應,它的單位為秒,Age 標頭通常接近于0,如果是0則可能是從源服務器獲取的,如果不是表示可能是由代理服務器創建,那么 Age 的值表示的是緩存后的響應再次發起認證到認證完成的時間值。
緩存的有效性是由多個標頭來共同決定的,而并非某一個標頭來決定。如果指定了 Cache-control:max-age=N ,那么緩存會保存 N 秒。如果這個通用標頭不存在的話,則會檢查是否存在 Expires 標頭。如果 Exprires 標頭存在,那么它的值減去 Date 標頭的值就可以確定其有效性。最后,如果max-age 和 expires 都不存在,就去尋找 Last-Modified 標頭,如果存在此標頭,則高速緩存的有效性等于 Date 標頭的值減去 Last-modified 標頭的值除以10。
緩存驗證
當到達緩存資源的有效期時,將對其進行驗證或再次獲取。僅當服務器提供了強驗證器或弱驗證器時,才可以進行驗證。
當用戶按下重新加載按鈕時,將觸發重新驗證。如果緩存的響應包含 Cache-control:must-revalidate標頭,則在正常瀏覽下也會觸發該事件。另一個因素是 高級 -> 緩存首選項 面板中的緩存驗證首選項。有一個選項可在每次加載文檔時強制進行驗證。
Etag
我們上面提到了強驗證器和弱驗證器,實現驗證器功能的標頭正式 Etag 的作用,這意味著 HTTP 用戶代理(例如瀏覽器)不知道該字符串表示什么,并且無法預測其值。如果 Etag 標頭是資源響應的一部分,則客戶端可以在未來請求的標頭中發出 If-None-Match,以驗證緩存的資源。
Last-Modified 響應標頭可以用作弱驗證器,因為它只有1秒可以分辨的時間。如果響應中存在 Last-Modified 標頭,則客戶端可以發出 If-Modified-Since 請求標頭來驗證緩存資源。(關于 Etag 更多我們會在條件請求介紹)
避免碰撞
通過使用 Etag 和 If-Match 標頭,你可以檢測避免碰撞。
例如,在編輯 MDN 時,將對當前 Wiki 內容進行哈希處理并將其放入響應中的 Etag 中
Etag: "33a64df551425fcc55e4d42a148795d9f25f89d4"
當將更改保存到 Wiki 頁面(發布數據)時,POST 請求將包含 If-Match 標頭,其中包含 Etag 值以檢查有效性。
If-Match: "33a64df551425fcc55e4d42a148795d9f25f89d4"
如果哈希值不匹配,則表示文檔已在中間進行了編輯,并返回 412 Precondition Failed 錯誤。
緩存未占用資源
Etag 標頭的另一個典型用法是緩存未更改的資源,如果用戶再次訪問給定的 URL(已設置Etag),并且該 URL過時,則客戶端將在 If-None-Match 標頭字段中發送其 Etag 的值
If-None-Match: "33a64df551425fcc55e4d42a148795d9f25f89d4"
服務器將客戶端的 Etag(通過 If-None-Match 發送)與 Etag 進行比較,以獲取其當前資源版本,如果兩個值都匹配(即資源未更改),則服務器會發回 304 Not Modified 狀態,沒有主體,它告訴客戶端響應的緩存仍然可以使用。
HTTP CROS 跨域
CROS 的全稱是 Cross-Origin Resource Sharing(CROS),中文譯為 跨域資源共享,它是一種機制。是一種什么機制呢?它是一種讓運行在一個域(origin)上的 Web 應用被準許訪問來自不同源服務器上指定資源的機制。在搞懂這個機制前,你需要線了解什么是 域(origin)
Origin
Web 概念中域(Origin) 的內容由scheme(protocol) - 協議,host(domain) - 主機和用于訪問它的 URL port - 端口定義。僅僅當 scheme 、host、port 都匹配時,兩個對象才有相同的來源。這種協議相同,域名相同,端口相同的安全策略也被稱為 同源策略(Same Origin Policy)。某些操作僅限于具有相同來源的內容,可以使用 CORS 取消此限制。
跨域的特點
下面是跨域問題的例子,看看你是否清楚什么是跨域了
(1) http://example.com/app1/index.html (2) http://example.com/app2/index.html
上面這兩個 URL 是否具有跨域問題呢?
上面兩個 URL 是不具有跨域問題的,因為這兩個 URL 具有相同的協議(scheme)和主機(host)
那么下面這兩個是否具有跨域問題呢?
http://Example.com:80 http://example.com
這兩個 URL 也不具有跨域問題,為什么不具有,端口不一樣啊。其實它們兩個端口是一樣的。
或許你會認為這兩個 URL 是不一樣的,放心,關于一樣不一樣的論據我給你拋出來了
協議和域名部分是不區分大小寫的,但是路徑部分則根據服務器平臺而定。Windows 和 Mac OS X 系統是不區分大小寫的,而采用UNIX和Linux系的服務器系統是區分大小寫的,
也就是說上面的 Example.com 和 example.com 其實是一個網址,并且由于兩個地址具有相同的 scheme 和 host ,默認情況下服務器通過端口80傳遞 HTTP 內容,所以上面這兩個地址也是相同的。
下面這兩個 URL 地址是否具有跨域問題?
http://example.com/app1 https://example.com/app2
這兩個 URL 的 scheme 不同,所以這兩個 URL 具有跨域問題
再看下面這三個 URL 是否具有跨域問題
http://example.com http://www.example.com http://myapp.example.com
這三個 URL 也是具有跨域問題的,因為它們隸屬于不通服務器的主機 host。
下面這兩個 URL 是否具有跨域問題
http://example.com http://example.com:8080
這兩個 URL 也是具有跨域問題,因為這兩個 URL 的默認端口不一樣。
同源策略
處于安全的因素,瀏覽器限制了從腳本發起跨域的 HTTP 請求。 XMLHttpRequest 和其他 Fetch 接口 會遵循 同源策略(same-origin policy)。也就是說使用這些 API 的應用程序想要請求相同的資源,那么他們應該具有相同的來源,除非來自其他來源的響應包括正確的 CORS 標頭也可以。
同源策略是一種很重要的安全策略,它限制了從一個來源加載的文檔或腳本如何與另一個來源的資源進行交互。 它有助于隔離潛在的惡意文檔,減少可能的攻擊媒介。
我們上面提到,如果兩個 URL 具有相同的協議、主機和端口號(如果指定)的話,那么兩個 URL 具有相同的來源。下面有一些實例,你判斷一下是不是具有相同的來源
目標來源 http://store.company.com/dir/page.html
| URL | Outcome | Reason |
|---|---|---|
| http://store.company.com/dir2... | 相同來源 | 只有path不同 |
| http://store.company.com/dir/... | 相同來源 | 只有path不同 |
| https://store.company.com/pag... | 不同來源 | 協議不通 |
| http://store.company.com:81/dir/page.html | 不同來源 | 默認端口不同 |
| http://news.company.com/dir/p... | 不同來源 | 主機不同 |
現在我帶你認識了兩遍不同的源,現在你應該知道如何區分兩個 URL 是否屬于同一來源了吧!
好,你現在知道了什么是跨域問題,現在我要問你,哪些請求會產生跨域請求呢?這是我們下面要討論的問題
跨域請求
跨域請求可能會從下面這幾種請求中發出:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
調用 XMLHttpRequest 或者 Fetch api。
XMLHttpRequest 是什么?(我是后端程序員,前端不太懂,簡單解釋下,如果解釋的不好,還請前端大佬們不要胖揍我)
所有的現代瀏覽器都有一個內置的 XMLHttpReqeust 對象,這個對象可以用于從服務器請求數據。
XMLHttpReqeust 對于開發人員來說很重要,XMLHttpReqeust 對象可以用來做下面這些事情
更新網頁無需重新刷新頁面
頁面加載后從服務器請求數據
頁面加載后從服務端獲取數據
在后臺將數據發送到服務器
使用 XMLHttpRequest(XHR) 對象與服務器進行交互,你可以從 URL 檢索數據從而不必刷新整個頁面,這使網頁可以更新頁面的一部分,而不會中斷用戶的操作。XMLHttpRequest 在 AJAX 異步編程中使用很廣泛。
再來說一下 Fetch API 是什么,Fetch 提供了請求和響應對象(以及其他網絡請求)的通用定義。它還提供了相關概念的定義,例如 CORS 和 HTTP Origin 頭語義,并在其他地方取代了它們各自的定義。
鴻蒙官方戰略合作共建——HarmonyOS技術社區
Web 字體(用于 CSS 中@ font-face中的跨域字體使用),以便服務器可以部署 TrueType 字體,這些字體只能由允許跨站點加載和使用的網站使用。
WebGL 紋理
使用 drawImage() 繪制到畫布上的圖像/視頻幀
圖片的 CSS 形狀
跨域功能概述
跨域資源共享標準通過添加新的 HTTP 標頭來工作,這些標頭允許服務器描述允許哪些來源從 Web 瀏覽器讀取信息。另外,對于可能導致服務器數據產生副作用的 HTTP 請求方法(尤其是 GET 或者具有某些 MIME 類型 POST 方法以外 HTTP 方法),該規范要求瀏覽器預檢請求,使用 HTTP OPTIONS 請求方法從服務器請求受支持的方法,然后在服務器批準后發送實際請求。服務器還可以通知客戶端是否應與請求一起發送憑據(例如 Cookies 和 HTTP 身份驗證)。
注意:CORS 故障會導致錯誤,但是出于安全原因,該錯誤的詳細信息不適用于 JavaScript。 所有代碼都知道發生了錯誤。 確定具體出問題的唯一方法是查看瀏覽器的控制臺以獲取詳細信息。
訪問控制
下面我會和大家探討三種方案,這些方案都演示了跨域資源共享的工作方式。所有這些示例都使用XMLHttpRequest,它可以在任何支持的瀏覽器中發出跨站點請求。
簡單請求
一些請求不會觸發 CORS預檢 (關于預檢我們后面再介紹)。簡單請求是滿足一下所有條件的請求
允許以下的方法:GET、HEAD和 POST
除了由用戶代理自動設置的標頭(例如 Connection、User-Agent 或者在 Fetch 規范中定義為禁止標頭名稱的其他標頭)外,唯一允許手動設置的標頭是那些 Fetch 規范將其定義為 CORS安全列出的請求標頭 ,它們是:
Accept
Accept-Language
Content-Language
Content-Type(下面會介紹)
DPR
Downlink
Save-Data
Viewport-Width
Width
Content-Type 標頭的唯一允許的值是
application/x-www-form-urlencoded
multipart/form-data
text/plain
沒有在請求中使用的任何 XMLHttpRequestUpload 對象上注冊事件偵聽器;這些可以使用XMLHttpRequest.upload 屬性進行訪問。
請求中未使用 ReadableStream對象。
例如,假定 web 內容 https://foo.example 想要獲取 https://bar.other 域的資源,那么 JavaScript 中的代碼可能會像下面這樣寫
const xhr = new XMLHttpRequest(); const url = 'https://bar.other/resources/public-data/'; xhr.open('GET', url); xhr.onreadystatechange = someHandler; xhr.send();這使用 CORS 標頭來處理特權,從而在客戶端和服務器之間執行某種轉換。

讓我們看看在這種情況下瀏覽器將發送到服務器的內容,并讓我們看看服務器如何響應:
GET /resources/public-data/ HTTP/1.1 Host: bar.other User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Connection: keep-alive Origin: https://foo.example
注意請求的標頭 Origin ,它表明調用來自于 https://foo.example。讓我們看看服務器是如何響應的
HTTP/1.1 200 OK Date: Mon, 01 Dec 2008 00:23:53 GMT Server: Apache/2 Access-Control-Allow-Origin: * Keep-Alive: timeout=2, max=100 Connection: Keep-Alive Transfer-Encoding: chunked Content-Type: application/xml […XML Data…]
服務端發送 Access-Control-Allow-Origin 作為響應。使用 Origin 標頭和 Access-Control-Allow-Origin 展示了最簡單的訪問控制協議。在這個事例中,服務端使用 Access-Control-Allow-Origin 作為響應,也就說明該資源可以被任何域訪問。
如果位于https://bar.other的資源所有者希望將對資源的訪問限制為僅來自https://foo.example的請求,他們應該發送如下響應
Access-Control-Allow-Origin: https://foo.example
現在除了 https://foo.example 之外的任何域都無法以跨域方式訪問到 https://bar.other 的資源。
預檢請求
和上面探討的簡單請求不同,預檢請求首先通過 OPTIONS 方法向另一個域上的資源發送 HTTP 請求,用來確定實際請求是否可以安全的發送。跨站點這樣被預檢,因為它們可能會影響用戶數據。
下面是一個預檢事例
const xhr = new XMLHttpRequest(); xhr.open('POST', 'https://bar.other/resources/post-here/'); xhr.setRequestHeader('X-PINGOTHER', 'pingpong'); xhr.setRequestHeader('Content-Type', 'application/xml'); xhr.onreadystatechange = handler; xhr.send('<person><name>Arun</name></person>');上面的事例創建了一個 XML 請求體用來和 POST 請求一起發送。此外,設置了非標準請求頭 X-PINGOTHER ,這個標頭不是 HTTP/1.1 的一部分,但通常對 Web 程序很有用。由于請求的 Content-Type 使用 application/xml,并且設置了自定義標頭,因此該請求被預檢。如下圖所示

如下所述,實際的 POST 請求不包含 Access-Control-Request- * 標頭;只有 OPTIONS 請求才需要它們。
下面我們來看一下完整的客戶端/服務器交互,首先是預檢請求/響應
OPTIONS /resources/post-here/ HTTP/1.1 Host: bar.other User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Connection: keep-alive Origin: http://foo.example Access-Control-Request-Method: POST Access-Control-Request-Headers: X-PINGOTHER, Content-Type
HTTP/1.1 204 No Content Date: Mon, 01 Dec 2008 01:15:39 GMT Server: Apache/2 Access-Control-Allow-Origin: https://foo.example Access-Control-Allow-Methods: POST, GET, OPTIONS Access-Control-Allow-Headers: X-PINGOTHER, Content-Type Access-Control-Max-Age: 86400 Vary: Accept-Encoding, Origin Keep-Alive: timeout=2, max=100 Connection: Keep-Alive
上面的1 -11 行代表預檢請求,預檢請求使用 OPYIIONS 方法,瀏覽器根據上面的 JavaScript 代碼段所使用的請求參數確定是否需要發送此請求,以便服務器可以響應是否可以使用實際請求參數發送請求。OPTIONS 是一種 HTTP / 1.1方法,用于確定來自服務器的更多信息,并且是一種安全的方法,這意味著它不能用于更改資源。請注意,與 OPTIONS 請求一起,還發送了另外兩個請求標頭(分別是第9行和第10行)
Access-Control-Request-Method: POST Access-Control-Request-Headers: X-PINGOTHER, Content-Type
Access-Control-Request-Method 標頭作為預檢請求的一部分通知服務器,當發送實際請求時,將使用POST 請求方法發送該請求。
Access-Control-Request-Headers 標頭通知服務器,當發送請求時,它將與X-PINGOTHER 和 Content-Type 自定義標頭一起發送。服務器可以確定這種情況下是否接受請求。
下面的 1 - 11行是服務器發回的響應,表示POST 請求和 X-PINGOTHER 是可以接受的,我們著重看一下下面這幾行
Access-Control-Allow-Origin: http://foo.example Access-Control-Allow-Methods: POST, GET, OPTIONS Access-Control-Allow-Headers: X-PINGOTHER, Content-Type Access-Control-Max-Age: 86400
服務器完成響應表明源 http://foo.example 是可以接受的 URL,能夠允許 POST、GET、OPTIONS 進行請求,允許自定義標頭 X-PINGOTHER, Content-Type。最后,Access-Control-Max-Age 以秒為單位給出一個值,這個值表示對預檢請求的響應可以緩存多長時間,在此期間內無需發送其他預檢請求。
完成預檢請求后,將發送實際請求:
POST /resources/post-here/ HTTP/1.1 Host: bar.other User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Connection: keep-alive X-PINGOTHER: pingpong Content-Type: text/xml; charset=UTF-8 Referer: https://foo.example/examples/preflightInvocation.html Content-Length: 55 Origin: https://foo.example Pragma: no-cache Cache-Control: no-cache <person><name>Arun</name></person>
HTTP/1.1 200 OK Date: Mon, 01 Dec 2008 01:15:40 GMT Server: Apache/2 Access-Control-Allow-Origin: https://foo.example Vary: Accept-Encoding, Origin Content-Encoding: gzip Content-Length: 235 Keep-Alive: timeout=2, max=99 Connection: Keep-Alive Content-Type: text/plain [Some GZIP'd payload]
正式響應中很多標頭我們在之前的文章已經探討過了,本篇不再做詳細的介紹,讀者可以參考
你還在為 HTTP 的這些概念頭疼嗎? 查閱
帶憑證的請求
XMLHttpRequest 或 Fetch 和 CORS 最有趣的功能就是能夠發出知道 HTTP Cookie 和 HTTP 身份驗證的 憑證 請求。默認情況下,在跨站點 XMLHttpRequest 或 Fetch 調用中,瀏覽器將不發送憑據。調用 XMLHttpRequest對象或 Request 構造函數時必須設置一個特定的標志。
在下面這個例子中,最初從 http://foo.example 加載的內容對設置了 Cookies 的 http://bar.other 上的資源進行了簡單的 GET 請求, foo.example 上可能的代碼如下
const invocation = new XMLHttpRequest(); const url = 'http://bar.other/resources/credentialed-content/'; function callOtherDomain() { if (invocation) { invocation.open('GET', url, true); invocation.withCredentials = true; invocation.onreadystatechange = handler; invocation.send(); } }第7行顯示 XMLHttpRequest 上的標志,必須設置該標志才能使用 Cookie 進行調用。默認情況下,調用是不在使用 Cookie 的情況下進行的。由于這是一個簡單的 GET 請求,因此不會進行預檢,但是瀏覽器將拒絕任何沒有 Access-Control-Allow-Credentials 的響應:標頭為true,指的是響應不會返回 web 頁面的內容。
上面的請求用下圖可以表示

這是客戶端和服務器之間的示例交換:
GET /resources/access-control-with-credentials/ HTTP/1.1 Host: bar.other User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Connection: keep-alive Referer: http://foo.example/examples/credential.html Origin: http://foo.example Cookie: pageAccess=2
HTTP/1.1 200 OK Date: Mon, 01 Dec 2008 01:34:52 GMT Server: Apache/2 Access-Control-Allow-Origin: https://foo.example Access-Control-Allow-Credentials: true Cache-Control: no-cache Pragma: no-cache Set-Cookie: pageAccess=3; expires=Wed, 31-Dec-2008 01:34:53 GMT Vary: Accept-Encoding, Origin Content-Encoding: gzip Content-Length: 106 Keep-Alive: timeout=2, max=100 Connection: Keep-Alive Content-Type: text/plain [text/plain payload]
上面第10行包含指向http://bar.other 上的內容 Cookie,但是如果 bar.other 沒有以 Access-Control-Allow-Credentials:true 響應(下面第五行),響應將被忽略,并且不能使用網站返回的內容。
請求憑證和通配符
當回應憑證請求時,服務器必須在 Access-Control-Allow-Credentials 中指定一個來源,而不能直接寫* 通配符
因為上面示例代碼中的請求標頭包含 Cookie 標頭,如果 Access-Control-Allow-Credentials 中是指定的通配符 * 的話,請求會失敗。
注意上面示例中的 Set-Cookie 響應標頭還設置了另外一個值,如果發生故障,將引發異常(取決于所使用的API)。
HTTP 響應標頭
下面會列出一些服務器跨域共享規范定義的 HTTP 標頭,上面簡單概述了一下,現在一起來認識一下,主要會介紹下面這些
Access-Control-Allow-Origin
Access-Control-Allow-Credentials
Access-Control-Allow-Headers
Access-Control-Allow-Methods
Access-Control-Expose-Headers
Access-Control-Max-Age
Access-Control-Request-Headers
Access-Control-Request-Method
Origin
Access-Control-Allow-Origin
Access-Control-Allow-Origin 是 HTTP 響應標頭,指示響應是否能夠和給定的源共享資源。Access-Control-Allow-Origin 指定單個資源會告訴瀏覽器允許指定來源訪問資源。對于沒有憑據的請求 *通配符,告訴瀏覽器允許任何源訪問資源。
例如,如果要允許源 https://mozilla.org 的代碼訪問資源,可以使用如下的指定方式
Access-Control-Allow-Origin: https://mozilla.org Vary: Origin
如果服務器指定單個來源而不是*通配符,則服務器還應在 Vary 響應標頭中包含該來源。
Access-Control-Allow-Credentials
Access-Control-Allow-Credentials 是 HTTP 的響應標頭,這個標頭告訴瀏覽器,當包含憑證請求(Request.credentials)時是否將響應公開給前端 JavaScript 代碼。
這時候你會問到 Request.credentials 是什么玩意?不要著急,來給你看一下,首先來看 Request 是什么玩意,
實際上,Request 是 Fetch API 的一類接口代表著資源請求。一般創建 Request 對象有兩種方式
使用 Request() 構造函數創建一個 Request 對象
還可以通過 FetchEvent.request api 操作來創建
再來說下 Request.credentials 是什么意思,Request 接口的憑據只讀屬性指示在跨域請求的情況下,用戶代理是否應從其他域發送 cookie。(其他 Request 對象的方法詳見 https://developer.mozilla.org...)
當發送的是憑證模式的請求包含 (Request.credentials)時,如果 Access-Control-Allow-Credentials 值為 true,瀏覽器將僅向前端 JavaScript 代碼公開響應。
Access-Control-Allow-Credentials: true
憑證一般包括 cookie、認證頭和 TLS 客戶端證書
當用作對預檢請求響應的一部分時,這表明是否可以使用憑據發出實際請求。注意簡單的 GET 請求不會進行預檢。
可以參考一個實際的例子 https://www.jianshu.com/p/ea4...
Access-Control-Allow-Headers
Access-Control-Allow-Headers 是一個響應標頭,這個標頭用來響應預檢請求,它發出實際請求時可以使用哪些HTTP標頭。
示例
自定義標頭
這是 Access-Control-Allow-Headers 標頭的示例。它表明除了像 CROS 安全列出的請求標頭外,對服務器的 CROS 請求還支持名為 X-Custom-Header 的自定義標頭。
Access-Control-Allow-Headers: X-Custom-Header
多個標頭
這個例子展示了 Access-Control-Allow-Headers 如何使用多個標頭
Access-Control-Allow-Headers: X-Custom-Header, Upgrade-Insecure-Requests
繞過其他限制
盡管始終允許使用 CORS 安全列出的請求標頭,并且通常不需要在 Access-Control-Allow-Headers 中列出這些標頭,但是無論如何列出它們都將繞開適用的其他限制。
Access-Control-Allow-Headers: Accept
這里你可能會有疑問,哪些是 CORS 列出的安全標頭?(別嫌累,就是這么麻煩)
有下面這些 Accep、Accept-Language、Content-Language、Content-Type ,當且僅當包含這些標頭時,無需在 CORS 上下文中發送預檢請求。
Access-Control-Allow-Methods
Access-Control-Allow-Methods 也是響應標頭,它指定了哪些訪問資源的方法可以使用預檢請求。例如
Access-Control-Allow-Methods: POST, GET, OPTIONS Access-Control-Allow-Methods: *
Access-Control-Expose-Headers
Access-Control-Expose-Headers 響應標頭表明哪些標頭可以作為響應的一部分公開。默認情況下,僅公開6個CORS安全列出的響應標頭,分別是
Cache-Control
Content-Language
Content-Type
Expires
Last-Modified
Pragma
如果希望客戶端能夠訪問其他標頭,則必須使用 Access-Control-Expose-Headers 標頭列出它們。下面是示例
要公開非 CORS 安全列出的請求標頭,可以像如下這樣指定
Access-Control-Expose-Headers: Content-Length
要另外公開自定義標頭,例如 X-Kuma-Revision,可以指定多個標頭,并用逗號分隔
Access-Control-Expose-Headers: Content-Length, X-Kuma-Revision
在不是憑證請求中,你還可以使用通配符
Access-Control-Expose-Headers: *
但是,這不會通配 Authorization 標頭,因此如果需要公開它,則需要明確列出
Access-Control-Expose-Headers: *, Authorization
Access-Control-Max-Age
Access-Control-Max-Age 響應頭表示預檢請求的結果可以緩存多長時間,例如
Access-Control-Max-Age: 600
表示預檢請求可以緩存10分鐘
Access-Control-Request-Headers
瀏覽器在發出預檢請求時使用 Access-Control-Request-Headers 請求標頭,使服務器知道在發出實際請求時客戶端可能發送的 HTTP 標頭。
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
Access-Control-Request-Method
同樣的,Access-Control-Request-Method 響應標頭告訴服務器發出預檢請求時將使用那種 HTTP 方法。此標頭是必需的,因為預檢請求始終是 OPTIONS,并且使用的方法與實際請求不同。
Access-Control-Request-Method: POST
Origin
Origin 請求標頭表明匹配的來源,它不包含任何信息,僅僅包含服務器名稱,它與 CORS 請求以及 POST 請求一起發送,它類似于 Referer 標頭,但與此標頭不同,它沒有公開整個路徑。例如
Origin: https://developer.mozilla.org
HTTP 條件請求
HTTP 具有條件請求的概念,通過比較資源更新生成的值與驗證器的值進行比較,來確定資源是否進行過更新。這樣的請求對于驗證緩存的內容、條件請求、驗證資源的完整性來說非常重要。
原則
HTTP 條件請求是根據特定標頭的值執行不同的請求,這些標頭定義了一個前提條件,如果前提條件匹配或不匹配,則請求的結果將有所不同。
對于 安全 的方法,像是 GET、用于請求文檔的資源,僅當條件請求的條件滿足時發回文檔資源,所以,這種方式可以節約帶寬。
什么是安全的方法,對于 HTTP 來說,安全的方法是不會改變服務器狀態的方法,換句話說,如果方法只是只讀操作,那么它肯定是安全的方法,比如說 GET 請求,它肯定是安全的方法,因為它只是請求資源。幾種常見的方法肯定是安全的,它們是 GET、HEAD和 OPTIONS。所有安全的方法都是冪等的(這他媽冪等又是啥意思?)但不是所有冪等的方法都是安全的,例如 PUT 和 DELETE 都是冪等的,但不安全。
冪等性:如果相同的客戶端發起一次或者多次 HTTP 請求會得到相同的結果,則說明 HTTP 是冪等的。(我們這次不深究冪等性)
對于 非安全 的方法,像是 PUT,只有原始文檔與服務器上存儲的資源相同時,才可以使用條件請求來傳輸文檔。(PUT 方法通常用來傳輸文件,就像 FTP 協議的文件上傳一樣)
驗證
所有的條件請求都會嘗試檢查服務器上存儲的資源是否與某個特定版本的資源相匹配。為了滿足這種情況,條件請求需要指示資源的版本。由于無法和整個文件逐個字符進行比較,因此需要把整個文件描繪成一個值,然后把此值和服務器上的資源進行比較,這種方式稱為比較器,比較器有兩個條件
文檔的最后修改日期
一個不透明的字符串,用于唯一標識每個版本,稱為實體標簽或 Etag。
比較兩個資源是否時相同的版本有些復雜,根據上下文,有兩種相等性檢查
當期望的是字節對字節進行比較時,例如在恢復下載時,使用強 Etag 進行驗證
當用戶代理需要比較兩個資源是否具有相同的內容時,使用若 Etag 進行驗證
HTTP 協議默認使用 強驗證,它指定何時進行弱驗證
強驗證
強驗證保證的是字節 級別的驗證,嚴格的驗證非常嚴格,可能在服務器級別難以保證,但是它能夠保證任何時候都不會丟失數據,但這種驗證丟失性能。
要使用 Last-Modified 很難實現強驗證,通常,這是通過使用帶有資源的 MD5 哈希值的 Etag 來完成的。
弱驗證
弱驗證不同于強驗證,因為如果內容相等,它將認為文檔的兩個版本相同,例如,一個頁面與另一個頁面的不同之處僅在于頁腳的日期不同,因此該頁面被認為與其他頁面相同。而使用強驗證時則被認為這兩個版本是不同的。構建一個若驗證的 Etag 系統可能會非常復雜,因為這需要了解每個頁面元素的重要性,但是對于優化緩存性能非常有用。
下面介紹一下 Etag 如何實現強弱驗證。
Etag 響應頭是特定版本的標識,它能夠使緩存變得更高效并能夠節省帶寬,因為如果緩存內容未發生變更,Web 服務器則不需要重新發送完整的響應。除此之外,Etag 能夠防止資源同時更新互相覆蓋。
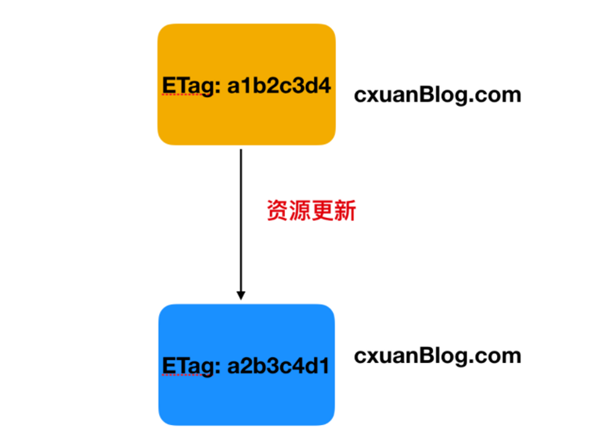
如果給定 URL 上的資源發生變更,必須生成一個新的 Etag 值,通過比較它們可以確定資源的兩個表示形式是否相同。
Etag 值有兩種,一種是強 Etag,一種是弱 Etag;
強 Etag 值,無論實體發生多么細微的變化都會改變其值,一般的表示如下
Etag: "33a64df551425fcc55e4d42a148795d9f25f89d4"
弱 Etag 值,弱 Etag 值只用于提示資源是否相同。只有資源發生了根本改變,產生差異時才會改變 Etag 值。這時,會在字段值最開始處附加 W/。
Etag: W/"0815"
下面就來具體探討一下條件請求的標頭和 Etag 的關系
條件請求
條件請求主要包含的標頭如下
If-Match
If-None-Match
If-Modified-Since
If-Unmodified-Since
If-Range
If-Match
對于 GET 和 POST 方法,服務器僅在與列出的 Etag(響應標頭) 之一匹配時才返回請求的資源。這里又多了一個新詞 Etag,我們稍后再說 Etag 的用法。對于像是 PUT 和其他非安全的方法,在這種情況下,它僅僅將上傳資源。
下面是兩種常見的案例
對于 GET 和 POST 方法,會結合使用 Range 標頭,它可以確保新發送請求的范圍與上一個請求的資源相同,如果不匹配的話,會返回 416 響應。
對于其他方法,特別是 PUT 方法,If-Match 可以防止丟失更新,服務器會比對 If-Match 的字段值和資源的 Etag 值,僅當兩者一致時,才會執行請求。反之,則返回狀態碼 412 Precondition Failed 的響應。例如
If-Match: "bfc13a64729c4290ef5b2c2730249c88ca92d82d" If-Match: *
If-None-Match
條件請求,它與 If-Match 的作用相反,僅當 If-None-Match 的字段值與 Etag 值不一致時,可處理該請求。對于GET 和 HEAD ,僅當服務器沒有與給定資源匹配的 Etag 時,服務器將返回 200 OK作為響應。對于其他方法,僅當最終現有資源的 Etag 與列出的任何值都不匹配時,才會處理請求。
當 GET 和 POST 發送的 If-None-Match與 Etag 匹配時,服務器會返回 304。
If-None-Match: "bfc13a64729c4290ef5b2c2730249c88ca92d82d" If-None-Match: W/"67ab43", "54ed21", "7892dd" If-None-Match: *
If-Modified-Since
If-Modified-Since 是 HTTP 條件請求的一部分,只有在給定日期之后,服務端修改了請求所需要的資源,才會返回 200 OK 的響應。如果在給定日期之后,服務端沒有修改內容,響應會返回 304 并且不帶任何響應體。If-Modified-Since 只能使用 GET 和 HEAD 請求。
If-Modified-Since 與 If-None-Match 結合使用時,它將被忽略,除非服務器不支持 If-None-Match。一般表示如下
If-Modified-Since: Wed, 21 Oct 2015 07:28:00 GMT
注意:這是格林威治標準時間。 HTTP 日期始終以格林尼治標準時間表示,而不是本地時間。
If-Range
If-Range 也是條件請求,如果滿足條件(If-Range 的值和 Etag 值或者更新的日期時間一致),則會發出范圍請求,否則將會返回全部資源。它的一般表示如下
If-Range: Wed, 21 Oct 2015 07:28:00 GMT If-Range: bfc13a64729c4290ef5b2c2730249c88ca92d82d
If-Unmodified-Since
If-Unmodified-Since HTTP 請求標頭也是一個條件請求,服務器只有在給定日期之后沒有對其進行修改時,服務器才返回請求資源。如果在指定日期時間后發生了更新,則以狀態碼 412 Precondition Failed 作為響應返回。
If-Unmodified-Since: Wed, 21 Oct 2015 07:28:00 GMT
條件請求示例
緩存更新
條件請求最常見的示例就是更新緩存,如果緩存是空或沒有緩存,則以200 OK的狀態發送回請求的資源。如下圖所示
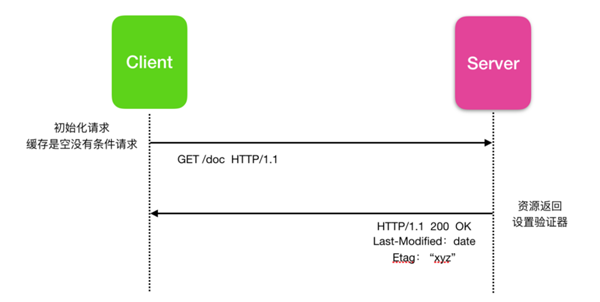
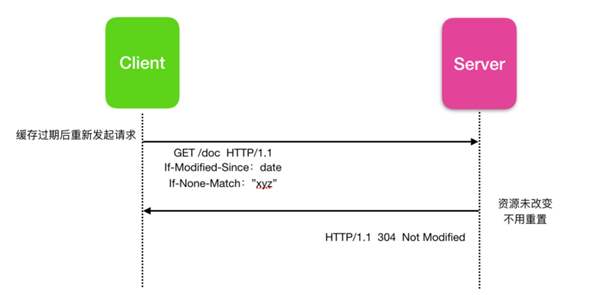
客戶端第一次發送請求沒有,緩存為空并且沒有條件請求,服務器在收到客戶端請求后,設置驗證器 Last-Modified 和 Etag 標簽,并把這兩個標簽隨著響應一起發送回客戶端。
下一次客戶端再發送相同的請求后,會直接從緩存中提取,只要緩存沒有過期,就不會有任何新的請求到達服務器重新下載資源。但是,一旦緩存過期,客戶端不會直接使用緩存的值,而是發出條件請求。 驗證器的值用作 If-Modified-Since 和 If-Match標頭的參數。
緩存過期后客戶端重新發起請求,服務器收到請求后發現如果資源沒有更改,服務器會發回 304 Not Modified響應,這使緩存再次刷新,并讓客戶端使用緩存的資源。 盡管有一個響應/請求往返消耗一些資源,但是這比再次通過有線傳輸整個資源更有效。
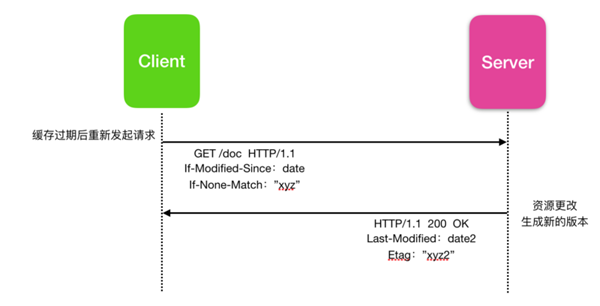
如果資源已經發生更改,則服務器僅使用新版本的資源返回 200 OK 響應,就像沒有條件請求,并且客戶端會重新使用新的資源,從這個角度來講,緩存是條件請求的前置條件。
斷點續傳
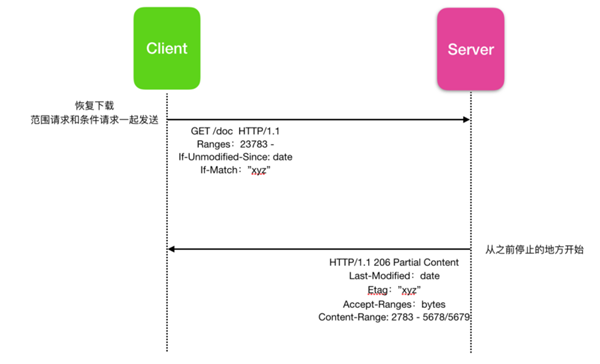
HTTP 可以支持文件的部分下載,通過保留已獲得的信息,此功能允許恢復先前的操作,從而節省帶寬和時間。

支持斷點續傳的服務器通過發送 Accept-Ranges 標頭廣播此消息,一旦發生這種情況,客戶端可以通過發送缺少范圍的 Ranges 標頭來恢復下載
這里你可能有疑問 Ranges 和 Content-Range是什么,來解釋一下
Range
Range HTTP 請求標頭指示服務器應返回文檔指定部分的資源,可以一次請求一個 Range 來返回多個部分,服務器會將這些資源返回各個文檔中。如果服務器成功返回,那么將返回 206 響應;如果 Range 范圍無效,服務器返回416 Range Not Satisfiable錯誤;服務器還可以忽略 Range 標頭,并且返回 200 作為響應。
Range: bytes=200-1000, 2000-6576, 19000-
還有一種表示是
Range: bytes=0-499, -500
它們分別表示請求前500個字節和最后500個字節,如果范圍重疊,則服務器可能會拒絕該請求。
Content-Range
HTTP 的 Content-Range 響應標頭是針對范圍請求而設定的,返回響應時使用首部字段 Content-Range,能夠告知客戶端響應實體的哪部分是符合客戶端請求的,字段以字節為單位。它的一般表示如下
Content-Range: bytes 200-1000/67589
上段代碼表示從所有 67589 個字節中返回 200-1000 個字節的內容
那么上面的 Content-Range你也應該知道是什么意思了
斷點續傳的原理比較簡單,但是這種方式存在潛在的問題:如果在兩次下載資源的期間進行了資源更新,那么獲得的范圍將對應于資源的兩個不同版本,并且最終文檔將被破壞。
為了阻止這種情況的出現,就會使用條件請求。對于范圍來說,有兩種方法可以做到這一點。一種方法是使用 If-Modified-Since和If-Match,如果前提條件失敗,服務器將返回錯誤;然后客戶端從頭開始重新下載。

即使此方法有效,當文檔資源發生改變時,它也會添加額外的 響應/請求 交換。這會降低性能,并且 HTTP 具有特定的標頭來避免這種情況 If-Range。
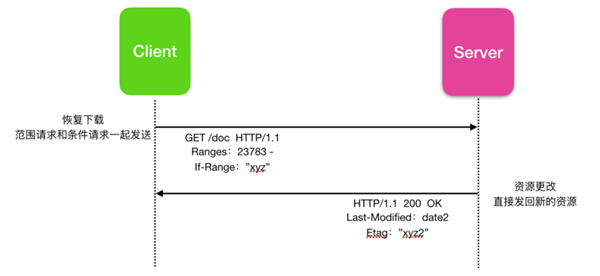
該解決方案效率更高,但靈活性稍差一些,因為在這種情況下只能使用一個 Etag。
通過樂觀鎖避免丟失更新
Web 應用程序中最普遍的操作是資源更新。這在任何文件系統或應用程序中都很常見,但是任何允許存儲遠程資源的應用程序都需要這種機制。
使用 put 方法,你可以實現這一點,客戶端首先讀取原始文件對其進行修改,然后把它們發送到服務器。
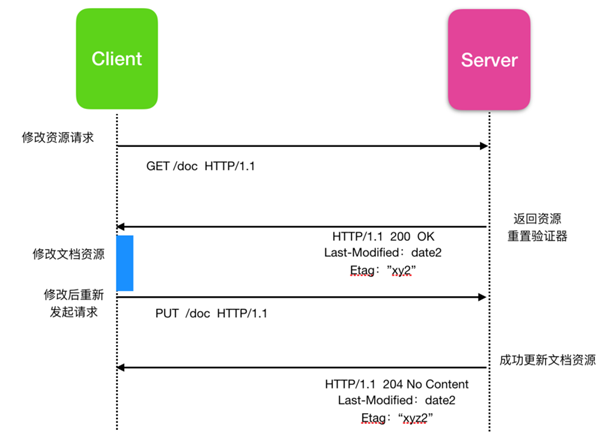
上面這種請求響應存在問題,一旦考慮到并發性,事情就會變得不準確。當客戶端在本地修改資源打算重新發送之前,第二個客戶端可以獲取相同的資源并對資源進行修改操作,這樣就會造成問題。當它們重新發送請求到服務器時,第一個客戶端所做的修改將被第二次客戶端的修改所覆蓋,因為第二次客戶端修改并不知道第一次客戶端正在修改。資源提交并更新的一方不會傳達給另外一方,所以要保留哪個客戶的更改,將隨著他們提交的速度而變化; 這取決于客戶端,服務器的性能,甚至取決于人工在客戶端編輯文檔的性能。 例如下面這個流程
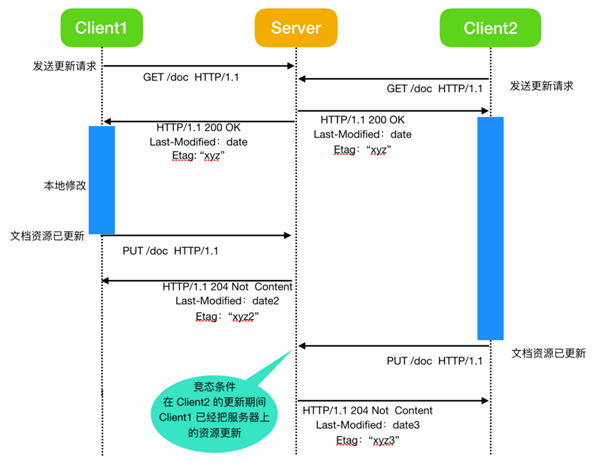
如果沒有兩個用戶同時操作服務器,也就不存在這個問題。但是,現實情況是不可能只有單個用戶出現的,所以為了規避或者避免這個問題,我們希望客戶端資源在更新時進行提示或者修改被拒絕時收到通知。
條件請求允許實現樂觀鎖算法。這個概念是允許所有的客戶端獲取資源的副本,然后讓他們在本地修改資源,并成功通過允許第一個客戶端提交更新來控制并發,基于此服務端的后面版本的更新都將被拒絕。
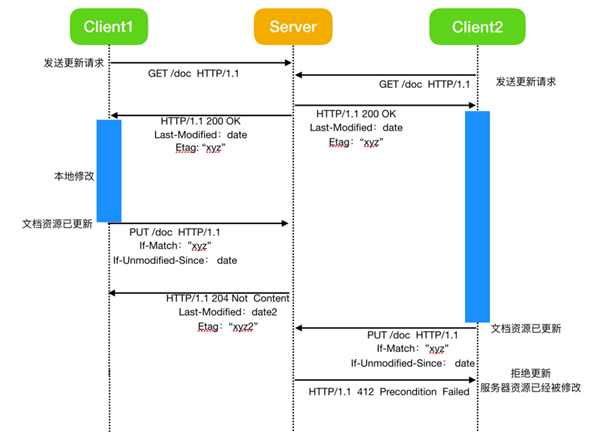
這是使用 If-Match 或 If-Unmodified-Since標頭實現的。如果 Etag 與原始文件不匹配,或者自獲取以來已對文件進行了修改,則更改為拒絕更新,并顯示412 Precondition Failed錯誤。
HTTP Cookies
HTTP 協議中的 Cookie 包括 Web Cookie 和瀏覽器 Cookie,它是服務器發送到 Web 瀏覽器的一小塊數據。服務器發送到瀏覽器的 Cookie,瀏覽器會進行存儲,并與下一個請求一起發送到服務器。通常,它用于判斷兩個請求是否來自于同一個瀏覽器,例如用戶保持登錄狀態。
HTTP Cookie 機制是 HTTP 協議無狀態的一種補充和改良
Cookie 主要用于下面三個目的
會話管理
登陸、購物車、游戲得分或者服務器應該記住的其他內容
個性化
用戶偏好、主題或者其他設置
追蹤
記錄和分析用戶行為
Cookie 曾經用于一般的客戶端存儲。雖然這是合法的,因為它們是在客戶端上存儲數據的唯一方法,但如今建議使用現代存儲 API。Cookie 隨每個請求一起發送,因此它們可能會降低性能(尤其是對于移動數據連接而言)。客戶端存儲的現代 API 是 Web 存儲 API(localStorage 和 sessionStorage)和 IndexedDB。
創建 Cookie
當接收到客戶端發出的 HTTP 請求時,服務器可以發送帶有響應的 Set-Cookie 標頭,Cookie 通常由瀏覽器存儲,然后將 Cookie 與 HTTP 標頭一同向服務器發出請求。可以指定到期日期或持續時間,之后將不再發送Cookie。此外,可以設置對特定域和路徑的限制,從而限制 cookie 的發送位置。
Set-Cookie 和 Cookie 標頭
Set-Cookie HTTP 響應標頭將 cookie 從服務器發送到用戶代理。下面是一個發送 Cookie 的例子
HTTP/2.0 200 OK Content-type: text/html Set-Cookie: yummy_cookie=choco Set-Cookie: tasty_cookie=strawberry [page content]
此標頭告訴客戶端存儲 Cookie
現在,隨著對服務器的每個新請求,瀏覽器將使用 Cookie 頭將所有以前存儲的 cookie 發送回服務器。
GET /sample_page.html HTTP/2.0 Host: www.example.org Cookie: yummy_cookie=choco; tasty_cookie=strawberry
Cookie 主要分為三類,它們是 會話Cookie、永久Cookie 和 Cookie的 Secure 和 HttpOnly 標記,下面依次來介紹一下
會話 Cookies
上面的示例創建的是會話 Cookie ,會話 Cookie 有個特征,客戶端關閉時 Cookie 會刪除,因為它沒有指定Expires 或 Max-Age 指令。 這兩個指令你看到這里應該比較熟悉了。
但是,Web 瀏覽器可能會使用會話還原,這會使大多數會話 Cookie 保持永久狀態,就像從未關閉過瀏覽器一樣
永久性 Cookies
永久性 Cookie 不會在客戶端關閉時過期,而是在特定日期(Expires)或特定時間長度(Max-Age)外過期。例如
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
Cookie的 Secure 和 HttpOnly 標記
安全的 Cookie 需要經過 HTTPS 協議通過加密的方式發送到服務器。即使是安全的,也不應該將敏感信息存儲在cookie 中,因為它們本質上是不安全的,并且此標志不能提供真正的保護。
HttpOnly 的作用
會話 cookie 中缺少 HttpOnly 屬性會導致攻擊者可以通過程序(JS腳本、Applet等)獲取到用戶的 cookie 信息,造成用戶cookie 信息泄露,增加攻擊者的跨站腳本攻擊威脅。
HttpOnly 是微軟對 cookie 做的擴展,該值指定 cookie 是否可通過客戶端腳本訪問。
如果在 Cookie 中沒有設置 HttpOnly 屬性為 true,可能導致 Cookie 被竊取。竊取的 Cookie 可以包含標識站點用戶的敏感信息,如 ASP.NET 會話 ID 或 Forms 身份驗證票證,攻擊者可以重播竊取的 Cookie,以便偽裝成用戶或獲取敏感信息,進行跨站腳本攻擊等。
Cookie 的作用域
Domain 和 Path 標識定義了 Cookie 的作用域:即 Cookie 應該發送給哪些 URL。
Domain 標識指定了哪些主機可以接受 Cookie。如果不指定,默認為當前主機(不包含子域名)。如果指定了Domain,則一般包含子域名。
感謝各位的閱讀,以上就是“帶你了解HTTP黑科技”的內容了,經過本文的學習后,相信大家對帶你了解HTTP黑科技這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





