溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么用Scrapy爬蟲框架爬取食品論壇數據并存入數據庫”,在日常操作中,相信很多人在怎么用Scrapy爬蟲框架爬取食品論壇數據并存入數據庫問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么用Scrapy爬蟲框架爬取食品論壇數據并存入數據庫”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
網絡爬蟲(又稱為網頁蜘蛛,網絡機器人),是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。另外一些不常使用的名字還有螞蟻、自動索引、模擬程序或者蠕蟲。------百度百科
說人話就是,爬蟲是用來海量規則化獲取數據,然后進行處理和運用,在大數據、金融、機器學習等等方面都是必須的支撐條件之一。
目前在一線城市中,爬蟲的崗位薪資待遇都是比較客觀的,之后提升到中、高級爬蟲工程師,數據分析師、大數據開發崗位等,都是很好的過渡。
本此介紹的項目其實不用想的太過復雜,最終要實現的目標也就是將帖子的每條評論爬取到數據庫中,并且做到可以更新數據,防止重復爬取,反爬等措施。
這部分主要是介紹本文需要用到的工具,涉及的庫,網頁等信息等
軟件:PyCharm
需要的庫:Scrapy, selenium, pymongo, user_agent,datetime
目標網站:
http://bbs.foodmate.net
插件:chromedriver(版本要對)
1、確定爬取網站的結構
簡而言之:確定網站的加載方式,怎樣才能正確的一級一級的進入到帖子中抓取數據,使用什么格式保存數據等。
其次,觀察網站的層級結構,也就是說,怎么根據板塊,一點點進入到帖子頁面中,這對本次爬蟲任務非常重要,也是主要編寫代碼的部分。
2、如何選擇合適的方式爬取數據?
目前我知道的爬蟲方法大概有如下(不全,但是比較常用):
1)request框架:運用這個http庫可以很靈活的爬取需要的數據,簡單但是過程稍微繁瑣,并且可以配合抓包工具對數據進行獲取。但是需要確定headers頭以及相應的請求參數,否則無法獲取數據;很多app爬取、圖片視頻爬取隨爬隨停,比較輕量靈活,并且高并發與分布式部署也非常靈活,對于功能可以更好實現。
2)scrapy框架:scrapy框架可以說是爬蟲最常用,最好用的爬蟲框架了,優點很多:scrapy 是異步的;采取可讀性更強的 xpath 代替正則;強大的統計和 log 系統;同時在不同的 url 上爬行;支持 shell 方式,方便獨立調試;支持寫 middleware方便寫一些統一的過濾器;可以通過管道的方式存入數據庫等等。這也是本次文章所要介紹的框架(結合selenium庫)。
1、第一步:確定網站類型
首先解釋一下是什么意思,看什么網站,首先要看網站的加載方式,是靜態加載,還是動態加載(js加載),還是別的方式;根據不一樣的加載方式需要不同的辦法應對。然后我們觀察今天爬取的網站,發現這是一個有年代感的論壇,首先猜測是靜態加載的網站;我們開啟組織 js 加載的插件,如下圖所示。
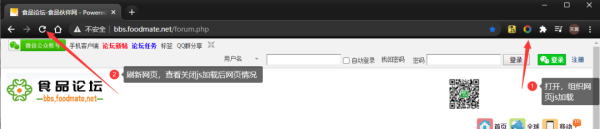
刷新之后發現確實是靜態網站(如果可以正常加載基本都是靜態加載的)。
2、第二步:確定層級關系
其次,我們今天要爬取的網站是食品論壇網站,是靜態加載的網站,在之前分析的時候已經了解了,然后是層級結構:

大概是上面的流程,總共有三級遞進訪問,之后到達帖子頁面,如下圖所示。

部分代碼展示:
一級界面:
def parse(self, response): self.logger.info("已進入網頁!") self.logger.info("正在獲取版塊列表!") column_path_list = response.css('#ct > div.mn > div:nth-child(2) > div')[:-1] for column_path in column_path_list: col_paths = column_path.css('div > table > tbody > tr > td > div > a').xpath('@href').extract() for path in col_paths: block_url = response.urljoin(path) yield scrapy.Request( url=block_url, callback=self.get_next_path, )二級界面:
def get_next_path(self, response): self.logger.info("已進入版塊!") self.logger.info("正在獲取文章列表!") if response.url == 'http://www.foodmate.net/know/': pass else: try: nums = response.css('#fd_page_bottom > div > label > span::text').extract_first().split(' ')[-2] except: nums = 1 for num in range(1, int(nums) + 1): tbody_list = response.css('#threadlisttableid > tbody') for tbody in tbody_list: if 'normalthread' in str(tbody): item = LunTanItem() item['article_url'] = response.urljoin( tbody.css('* > tr > th > a.s.xst').xpath('@href').extract_first()) item['type'] = response.css( '#ct > div > div.bm.bml.pbn > div.bm_h.cl > h2 > a::text').extract_first() item['title'] = tbody.css('* > tr > th > a.s.xst::text').extract_first() item['spider_type'] = "論壇" item['source'] = "食品論壇" if item['article_url'] != 'http://bbs.foodmate.net/': yield scrapy.Request( url=item['article_url'], callback=self.get_data, meta={'item': item, 'content_info': []} ) try: callback_url = response.css('#fd_page_bottom > div > a.nxt').xpath('@href').extract_first() callback_url = response.urljoin(callback_url) yield scrapy.Request( url=callback_url, callback=self.get_next_path, ) except IndexError: pass三級界面:
def get_data(self, response): self.logger.info("正在爬取論壇數據!") item = response.meta['item'] content_list = [] divs = response.xpath('//*[@id="postlist"]/div') user_name = response.css('div > div.pi > div:nth-child(1) > a::text').extract() publish_time = response.css('div.authi > em::text').extract() floor = divs.css('* strong> a> em::text').extract() s_id = divs.xpath('@id').extract() for i in range(len(divs) - 1): content = '' try: strong = response.css('#postmessage_' + s_id[i].split('_')[-1] + '').xpath('string(.)').extract() for s in strong: content += s.split(';')[-1].lstrip('\r\n') datas = dict(content=content, # 內容 reply_id=0, # 回復的樓層,默認0 user_name=user_name[i], # ?戶名 publish_time=publish_time[i].split('于 ')[-1], # %Y-%m-%d %H:%M:%S' id='#' + floor[i], # 樓層 ) content_list.append(datas) except IndexError: pass item['content_info'] = response.meta['content_info'] item['scrawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S') item['content_info'] += content_list data_url = response.css('#ct > div.pgbtn > a').xpath('@href').extract_first() if data_url != None: data_url = response.urljoin(data_url) yield scrapy.Request( url=data_url, callback=self.get_data, meta={'item': item, 'content_info': item['content_info']} ) else: item['scrawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S') self.logger.info("正在存儲!") print('儲存成功') yield item3、第三步:確定爬取方法
由于是靜態網頁,首先決定采用的是scrapy框架直接獲取數據,并且通過前期測試發現方法確實可行,不過當時年少輕狂,小看了網站的保護措施,由于耐心有限,沒有加上定時器限制爬取速度,導致我被網站加了限制,并且網站由靜態加載網頁變為:動態加載網頁驗證算法之后再進入到該網頁,直接訪問會被后臺拒絕。
但是這種問題怎么會難道我這小聰明,經過我短暫地思考(1天),我將方案改為scrapy框架 + selenium庫的方法,通過調用chromedriver,模擬訪問網站,等網站加載完了再爬取不就完了,后續證明這個方法確實可行,并且效率也不錯。
實現部分代碼如下:
def process_request(self, request, spider): chrome_options = Options() chrome_options.add_argument('--headless') # 使用無頭谷歌瀏覽器模式 chrome_options.add_argument('--disable-gpu') chrome_options.add_argument('--no-sandbox') # 指定谷歌瀏覽器路徑 self.driver = webdriver.Chrome(chrome_options=chrome_options, executable_path='E:/pycharm/workspace/爬蟲/scrapy/chromedriver') if request.url != 'http://bbs.foodmate.net/': self.driver.get(request.url) html = self.driver.page_source time.sleep(1) self.driver.quit() return scrapy.http.HtmlResponse(url=request.url, body=html.encode('utf-8'), encoding='utf-8', request=request)4、第四步:確定爬取數據的儲存格式
這部分不用多說,根據自己需求,將需要爬取的數據格式設置在items.py中。在工程中引用該格式保存即可:
class LunTanItem(scrapy.Item): """ 論壇字段 """ title = Field() # str: 字符類型 | 論壇標題 content_info = Field() # str: list類型 | 類型list: [LunTanContentInfoItem1, LunTanContentInfoItem2] article_url = Field() # str: url | 文章鏈接 scrawl_time = Field() # str: 時間格式 參照如下格式 2019-08-01 10:20:00 | 數據爬取時間 source = Field() # str: 字符類型 | 論壇名稱 eg: 未名BBS, 水木社區, 天涯論壇 type = Field() # str: 字符類型 | 板塊類型 eg: '財經', '體育', '社會' spider_type = Field() # str: forum | 只能寫 'forum'
5、第五步:確定保存數據庫
本次項目選擇保存的數據庫為mongodb,由于是非關系型數據庫,優點顯而易見,對格式要求沒有那么高,可以靈活儲存多維數據,一般是爬蟲優選數據庫(不要和我說redis,會了我也用,主要是不會)
代碼:
import pymongo class FMPipeline(): def __init__(self): super(FMPipeline, self).__init__() # client = pymongo.MongoClient('139.217.92.75') client = pymongo.MongoClient('localhost') db = client.scrapy_FM self.collection = db.FM def process_item(self, item, spider): query = { 'article_url': item['article_url'] } self.collection.update_one(query, {"$set": dict(item)}, upsert=True) return item這時,有聰明的盆友就會問:如果運行兩次爬取到了一樣的數據怎么辦呢?(換句話說就是查重功能)
這個問題之前我也沒有考慮,后來在我詢問大佬的過程中知道了,在我們存數據的時候就已經做完這件事了,就是這句:
query = { 'article_url': item['article_url'] } self.collection.update_one(query, {"$set": dict(item)}, upsert=True)通過帖子的鏈接確定是否有數據爬取重復,如果重復可以理解為將其覆蓋,這樣也可以做到更新數據。
6、其他設置
像多線程、headers頭,管道傳輸順序等問題,都在settings.py文件中設置,具體可以參考小編的項目去看,這里不再贅述。
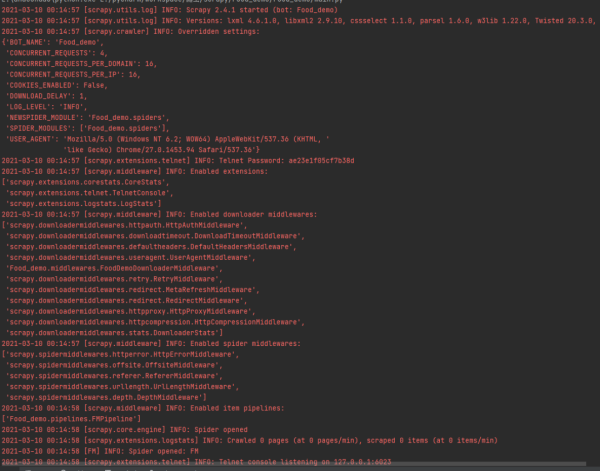
1、點擊運行,結果顯示在控制臺,如下圖所示。

2、中間會一直向隊列中堆很多帖子的爬取任務,然后多線程處理,我設置的是16線程,速度還是很可觀的。
3、數據庫數據展示:

content_info中存放著每個帖子的全部留言以及相關用戶的公開信息。
到此,關于“怎么用Scrapy爬蟲框架爬取食品論壇數據并存入數據庫”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





