溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“實用的數據科學Python庫有什么功能”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1. 獲取數據
獲取數據是解決數據科學問題的關鍵一步。你需要提出一個問題并最終解決它。這取決于你是如何以及從何處獲取數據的。獲取數據較好的方法就是從Kaggle上下載或從網絡上抓取。
當然,你也可以采用適當的方法和工具從網絡上抓取數據。
網絡數據抓取最重要、最常用的庫包括:
1.Beautiful Soup
2.Requests
3.Pandas
Beautiful Soup是一個可從HTML和XML文件中提取數據的Python庫。推薦讀者閱讀Beautiful Soup庫官方文檔。
如果已經安裝Python,只需輸入以下命令,即可安裝Beautiful Soup。文中所涉及的庫全部給出了安裝方法。但是我更推薦讀者使用Google Colab,便于練習代碼。在Google Colab中,無需手動安裝,只需要輸入“importlibrary_name”,Colab就會自動安裝。
pip install beautifulsoup4
導入Beautiful Soup庫:
from bs4 import BeautifulSoupSoup = BeautifulSoup(page_name.text, ‘html.parser’)
Python的Requests庫采用更加簡單易用的方式發送HTTP請求。Requests庫中有很多種方法,其中最常用的是request.get()。在URL轉發成功或失敗的情況下,request.get()都能夠返回URL轉發狀態。
安裝Requets:
pip install requests
導入Requests庫:
import requestspaga_name = requests.get('url_name')
Pandas是一種方便易用的高性能數據結構,同時也是Python編程語言分析工具。Pandas提供了一種能夠清晰、簡潔地存儲數據的數據框架。
安裝Pandas:
pip install pandas
導入Pandas庫:
import pandas as pd
2. 清理數據
清理數據有許多重要的步驟,往往包括清除重復行、清除異常值、查找缺失值和空值,以及將對象值轉換成空值并繪制成圖表等。
數據清理常用的庫包括:
1.Pandas
2.NumPy
Pandas可以說是數據科學中的“萬金油”——到處都可用。關于Pandas的介紹詳見上文,此處不再贅述。
NumPy即Numeric Python,是一個支持科學計算的Python庫。眾所周知,Python本身并不支持矩陣數據結構,而Python中的NumPy庫則支持創建和運行矩陣計算。
運行以下命令下載NumPy(確保已經安裝了Python):
python -m pip install --user numpy scipy matplotlib ipython jupyter pandas sympy nose
導入NumPy庫:
import numpy as np
3. 探索數據
探索性數據分析(Exploratory Data Analysis, EDA)是用于增強信息索引理解的工具,通過有規律地刪減和用圖表繪制索引基本特征實現。使用EDA能夠幫助用戶更加深入、清晰地探索數據,展現重要信息采集的發布或情況。
運行EDA常用的庫包括:
1.Pandas
2.Seaborn
3.Matplotlib.pyplot
Pandas:詳見上文。
Seaborn是一個Python數據可視化庫,為繪制數據圖表提供了一個高級接口。安裝新版本的Seaborn:
pip install seaborn
推薦讀者閱讀Seaborn官方文檔:https://seaborn.pydata.org/examples/index.html?source=post_page-----a58e90f1b4ba----------------------#example-gallery
使用Seaborn,可以輕松繪制條形圖、散點圖、熱力圖等圖表。導入Seaborn:
import seaborn as sns
Matplotlib是一個Python 2D圖形繪圖庫,能夠在多種環境中繪制圖表,可替代Seaborn。事實上,Seaborn是基于Matplotlib開發的。
安裝Matplotlib:
python -m pip install -U matplotlib
推薦閱讀Matplotlib官方文檔:https://matplotlib.org/users/index.html?source=post_page-----a58e90f1b4ba----------------------
導入Matplotlib.pyplot庫:
import matplotlib.pyplot as plt
4. 構建模型
構建模型是數據科學中的關鍵一步。由于這一步要求根據要解決的問題和所獲取的數據來構建機器學習模型,所以和其他步驟相比難度更大。在這一步中,問題陳述是至關重要的一點,因為它會影響對問題的定義和提出的解決方法。網絡上大部分公開的數據集都是基于某一個問題收集的,因此解決問題的能力就尤為重要。而且,由于沒有某個特定的算法最適合自己,你需要在多種算法中進行選擇,考慮數據適合用回歸、分類、聚類還是降維算法。
選擇算法經常是一件讓人頭疼的事。讀者可以使用SciKit learn算法選擇路徑圖來記錄追蹤哪個算法的性能最優。下圖展示了一張SciKit learn的路徑圖:
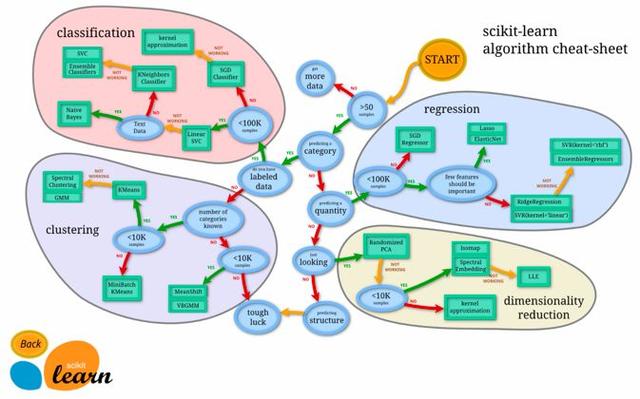
不難猜出,建模時最常用的庫是:
1.SciKit learn
SciKit learn是Python中一個便于使用的構建機器學習模型的庫。它是基于NumPy、SciPy和Matplotlib開發的。SciKit learn庫官方文檔如下:https://scikit-learn.org/stable/?source=post_page-----a58e90f1b4ba----------------------
導入scikit learn:
import sklearn
安裝scikit learn:
pip install -U scikit-learn
5. 呈現數據
這是數據科學的最后一步,也是很多人不想做的一步——畢竟沒有人想要公開發表他們的數據發現。呈現數據也是有法可循的,并且這個方法極為重要,因為無論如何,成果最終還是要向人們展示的。而且由于人們并不關心所使用的的算法,他們只關心結果,所以展示還要做到簡潔明了。
同時,安裝如下指令給notebook配備展示選項:
pip install RISE
“實用的數據科學Python庫有什么功能”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





