溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹一個字符串中的字符有多少個,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
依照Java的文檔, Java中的字符內部是以UTF-16編碼方式表示的,最小值是 \\u0000 (0),最大值是\\uffff(65535), 也就是一個字符以2個字節來表示,難道Java最多只能表示 65535個字符?
char: The char data type is a single 16-bit Unicode character. It has a minimum value of '\\u0000' (or 0) and a maximum value of '\\uffff' (or 65,535 inclusive).
from The Java™ Tutorials
首先,讓我們先看個例子:
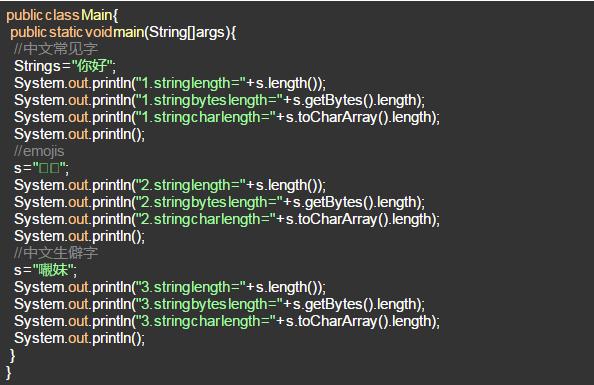
運行這個程序,你覺得輸出結果是什么?
輸出結果:

我們知道, String.getBytes()如果不指定編碼格式,Java會使用操作系統的編碼格式得到字節數組,在我的MacOS中,默認使用UTF-8作為字符編碼(locale命令可以查看操作系統的編碼),所以在我的機器運行,String.getBytes()會返回UTF-8編碼的字節數組。
String.length返回Unicode code units的長度。
String.toCharArray返回字符數組。
我們設置的字符串都是兩個unicode字符,輸出結果:
普通的中文字:字符串的長度是2,每個中文字按UTF-8編碼是三個字節,字符數組的長度看起來也沒問題
emojis字符:我們設置了兩個emojis字符,男女頭像。結果字符串的長度是4, UTF-8編碼8個字節,字符數組的長度是4
生僻的中文字:我們設置了兩個中文字,其中一個是生僻的中文字。結果字符串的長度是3, UTF-8編碼7個字節,字符數組的長度是3
看起來字符串的字符數和我們預期的有點不一樣,我們的字符串只有兩個unicode字符, 可是輸出結果有時候是2,有時候是3, 有時候是4,為什么呢?
這還得從Java的歷史說起。
Java最初設計的Charactor用兩個字節來表示unicode字符,這沒有問題, 因為最初unicode中的字符還比較少, Java 1.1之前采用Unicode version 1.1.5, JDK 1.1中支持Unicode 2.0, JDK 1.1.7支持Unicode 2.1, Java SE 1.4 支持 Unicode 3.0, Java SE 5.0開始支持Unicode 4.0。
直到Unicode 3.0, Java用兩個字節來表示unicode字符還沒有問題,因為Unicode 3.0最多49,259個字符, 兩個字節可以表示65,535個字符,還足夠容的下所有的uicode3.0字符。
但是Unicode 4.0(事實上自Unicode 3.1), 字符集進行很大的擴充,已經達到了96,447個字符,Unicode 11.0已經包含137,374個字符。
在Unicode中,為每一個字符對應一個編碼點(一個整數),用 U+緊跟著十六進制數表示。所有字符按照使用上的頻繁度劃分為 17 個平面(編號為 0-16),即基本的多語言平面和增補平面。基本的多語言平面(英文為 Basic Multilingual Plane,簡稱 BMP)又稱平面 0,收集了使用最廣泛的字符。
這樣一來,Java的Charactor的兩個字節的設計,已經不足以容納所有的Unicode 4的字符, 所以可能需要4個字節才能表示擴展字符,所以現在的Charactor代表的已經不再是一個字符 (代碼點 code point), 而是一個代碼單元(code unit)。
Code Point:代碼點,一個字符的數字表示。一個字符集一般可以用一張或多張由多個行和多個列所構成的二維表來表示。二維表中行與列交叉的點稱之為代碼點,每個碼點分配一個唯一的編號數字,稱之為碼點值或碼點編號,除開某些特殊區域(比如代理區、專用區)的非字符代碼點和保留代碼點,每個代碼點唯一對應于一個字符。從U+0000 到 U+10FFFF。
Code Unit:代碼單元,是指一個已編碼的文本中具有最短的比特組合的單元。對于 UTF-8 來說,代碼單元是 8 比特長;對于 UTF-16 來說,代碼單元是 16 比特長。換一種說法就是 UTF-8 的是以一個字節為最小單位的,UTF-16 是以兩個字節為最小單位的。
Java的字符在內部以UTF-16編碼方式來表示,String.length返回的是Code Unit的長度,而不再是Unicode中字符的長度。對于傳統的BMP平面的代碼點,String.length和我們傳統理解的字符的數量是一致的,對于擴展的字符,String.length可能是我們理解的字符長度的兩倍。
有可能你會問, 對于一個UTF-16編碼的擴展字符,它以4個字節來表示,那么前兩個字節會不會和BMP平面沖突,導致程序不知道它是擴展字符還是BMP平面的字符?
其實是不會的, 幸運的是, 在BMP平面中, U+D800到U+DFFF之間的碼位是永久保留不映射到Unicode字符,UTF-16就利用保留下來的0xD800-0xDFFF區塊的碼位來對輔助平面的字符的碼位進行編碼。
UTF-16編碼中,輔助平面中的碼位從U+10000到U+10FFFF,共計FFFFF個,需要20位來表示。第一個整數(兩個字節,稱為前導代理)要容納上述20位的前10位,第二個整數(稱為后尾代理)容納上述20位的后10位。前導代理的值的范圍是0xD800到0xDBFF,后尾代理的0xDC00~0xDFFF。
可以看到前導代理和后尾代理的范圍都落在了BMP平面中不用來映射的碼位,所以不會產生沖突,而且前導代理和后尾代理也沒有重合。這樣我們得到兩個字節的,就可以直接判斷它是否是BMP平面的字符,還是擴展字符中的前導代理還是后尾代碼。
國外的有些用戶用emojis字符做自己的昵稱,導致有些系統不能正確的顯示出來,這是因為這些系統粗暴的使用Charactor來表示,在顯示的時候截斷的時候有時候可能不是在正確的代碼點上進行截斷。
我們在進行字符串截取的時候,比如String.substring有可能會踩到一些坑,尤其經常使用的emojis字符。
自 Java 1.5 java.lang.String就提供了Code Point方法, 用來獲取完整的Unicode字符和Unicode字符數量:
publicintcodePointAt(intindex) publicintcodePointBefore(intindex) publicintcodePointCount(intbeginIndex,intendIndex)
注意這些方法中的index使用的是code unit值。
關于一個字符串中的字符有多少個就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





