溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何使用Python和創建簡單語音識別引擎,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
語音識別是機器或程序識別口語中的單詞和短語并將其轉換為機器可讀格式的能力。通常,這些算法的簡單實現有一個有限的詞匯表,它可能只識別單詞/短語。但是,更復雜的算法(例如Cloud Speech-to-Text和Amazon Transcribe)具有廣泛的詞匯量,并包含方言、噪音和俚語。
簡介
語音只是由我們的聲帶引起的空氣周圍振動而產生的一系列聲波。這些聲波由麥克風記錄,然后轉換為電信號。然后使用高級信號處理技術處理信號,分離音節和單詞。得益于深度學習方面令人難以置信的新進展,計算機也可以從經驗中學習理解語音。
語音識別通過聲學和語言建模使用算法來工作。聲學建模表示語音和音頻信號的語言單元之間的關系;語言建模將聲音與單詞序列進行匹配,以幫助區分聽起來相似的單詞。通常,基于循環層的深度學習模型用于識別語音中的時間模式,以提高系統內的準確性。也可以使用其他方法,例如隱馬爾可夫模型(第一個語音識別算法是使用這種方法)。在本文中,我將僅討論聲學模型。
信號處理
有多種方法可以將音頻波轉換為算法可以處理的元素,其中一種方法(在本教程中將使用的一種方法)是在等距的點上記錄聲波的高度:
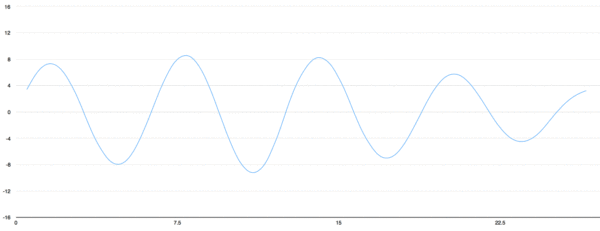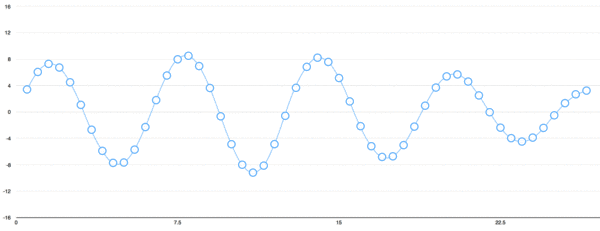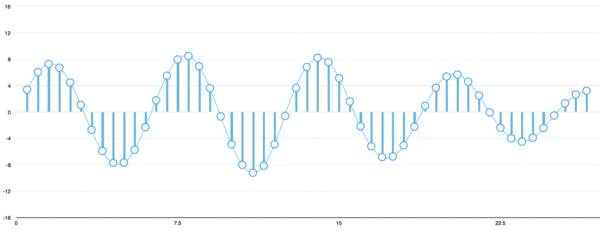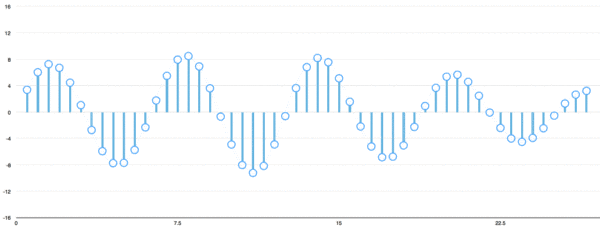
我們每秒讀取數千次,并記錄一個代表當時聲波高度的數字。這是一個未壓縮的.wav音頻文件。“ CD質量”音頻以44.1 kHz(每秒44,100個讀數)采樣。但是對于語音識別而言,16khz(每秒16,000個樣本)的采樣率足以覆蓋人類語音的頻率范圍。
用這種方法,音頻是通過一個數字向量來表示的,其中每個數字以1/16000秒的間隔表示聲波的振幅。這個過程類似于圖像預處理,如下例所示:
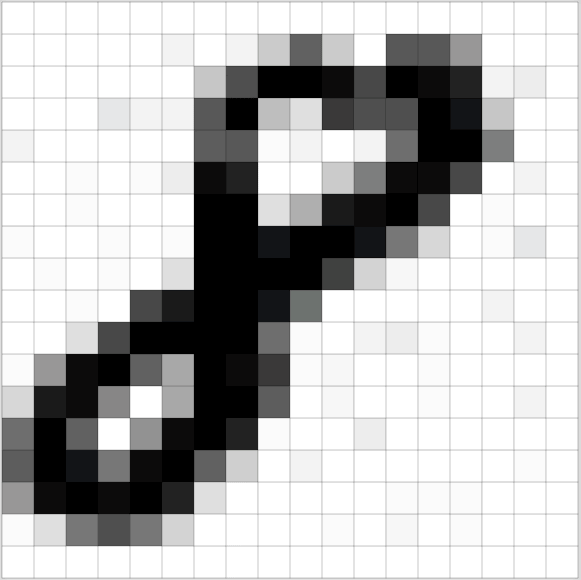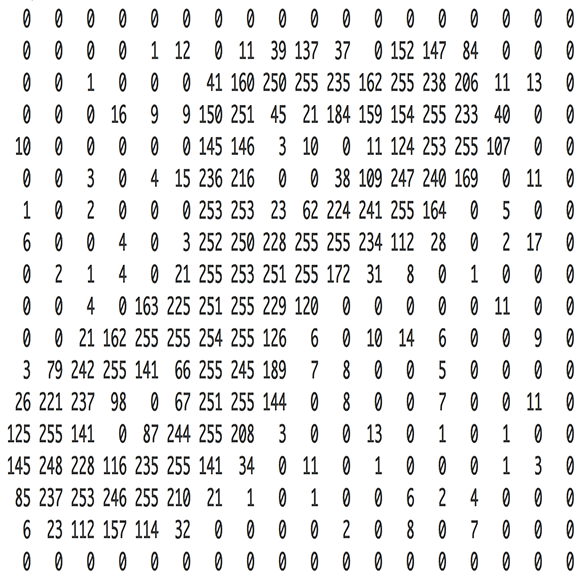
多虧尼奎斯特定理(1933年— 弗拉基米爾·科特爾尼科夫(Vladimir Kotelnikov)),我們知道,只要采樣速度至少是我們要記錄的最高頻率的兩倍,我們就可以使用數學方法從間隔采樣中完美重建原始聲波。
Python庫
為了完成這個任務,我使用Anaconda環境(Python 3.7)和以下Python庫:
ipython (v 7.10.2)
keras (v 2.2.4)
librosa (v 0.7.2)
scipy (v 1.1.0)
sklearn (v 0.20.1)
sounddevice (v 0.3.14)
tensorflow (v 1.13.1)
tensorflow-gpu (v 1.13.1)
numpy (v 1.17.2)
from tensorflow.compat.v1 import ConfigProto from tensorflow.compat.v1 import Session import os import librosa import IPython.display as ipd import matplotlib.pyplot as plt import numpy as np from scipy.io import wavfile import warnings config = ConfigProto() config.gpu_options.allow_growth = True sess = Session(config=config) warnings.filterwarnings("ignore")1.數據集
我們在實驗中使用TensorFlow提供的語音指令數據集。它包括由成千上萬不同的人發出的由30個短單詞組成的65000個一秒鐘長的話語。我們將建立一個語音識別系統,它可以理解簡單的語音命令。您可以從此處下載數據集(https://www.kaggle.com/c/tensorflow-speech-recognition-challenge)。
2.預處理音頻波
在使用的數據集中,一些記錄的持續時間少于1秒,并且采樣率太高。因此,讓我們閱讀聲波并使用下面的預處理步驟來解決這個問題。這是我們要執行的兩個步驟:
重采樣
刪除少于1秒的短命令
讓我們在下面的Python代碼片段中定義這些預處理步驟:
train_audio_path = './train/audio/' all_wave = [] all_label = [] for label in labels: print(label) waves = [f for f in os.listdir(train_audio_path + '/'+ label) if f.endswith('.wav')] for wav in waves: samples, sample_rate = librosa.load(train_audio_path + '/' + label + '/' + wav, sr = 16000) samples = librosa.resample(samples, sample_rate, 8000) if(len(samples)== 8000) : all_wave.append(samples) all_label.append(label)由上可知,信號的采樣率為16000 hz。我們把它重采樣到8000赫茲,因為大多數語音相關的頻率都在8000赫茲。
第二步是處理我們的標簽,這里我們將輸出標簽轉換為整數編碼,將整數編碼標簽轉換為one-hot 向量,因為這是一個多目標問題:
from sklearn.preprocessing import LabelEncoder from keras.utils import np_utils label_enconder = LabelEncoder() y = label_enconder.fit_transform(all_label) classes = list(label_enconder.classes_) y = np_utils.to_categorical(y, num_classes=len(labels))
預處理步驟的最后一步是將2D數組reshape為3D,因為conv1d的輸入必須是3D數組:
all_wave = np.array(all_wave).reshape(-1,8000,1)
3.創建訓練和驗證集
為了執行我們的深度學習模型,我們將需要生成兩個集合(訓練和驗證)。對于此實驗,我使用80%的數據訓練模型,并在其余20%的數據上進行驗證:
from sklearn.model_selection import train_test_split x_train, x_valid, y_train, y_valid = train_test_split(np.array(all_wave),np.array(y),stratify=y,test_size = 0.2,random_state=777,shuffle=True)
4.機器學習模型架構
我使用Conv1d和GRU層來建模用于語音識別的網絡。Conv1d是一個僅在一維上進行卷積的卷積神經網絡,而GRU的目標是解決標準循環神經網絡的梯度消失問題。GRU也可以看作是LSTM的一個變體,因為兩者的設計相似,在某些情況下,可以產生同樣優秀的結果。
該模型基于deepspeech h3和Wav2letter++ algoritms這兩種著名的語音識別方法。下面的代碼演示了使用Keras提出的模型:
from keras.layers import Bidirectional, BatchNormalization, CuDNNGRU, TimeDistributed from keras.layers import Dense, Dropout, Flatten, Conv1D, Input, MaxPooling1D from keras.models import Model from keras.callbacks import EarlyStopping, ModelCheckpoint from keras import backend as K K.clear_session() inputs = Input(shape=(8000,1)) x = BatchNormalization(axis=-1, momentum=0.99, epsilon=1e-3, center=True, scale=True)(inputs) #First Conv1D layer x = Conv1D(8,13, padding='valid', activation='relu', strides=1)(x) x = MaxPooling1D(3)(x) x = Dropout(0.3)(x) #Second Conv1D layer x = Conv1D(16, 11, padding='valid', activation='relu', strides=1)(x) x = MaxPooling1D(3)(x) x = Dropout(0.3)(x) #Third Conv1D layer x = Conv1D(32, 9, padding='valid', activation='relu', strides=1)(x) x = MaxPooling1D(3)(x) x = Dropout(0.3)(x) x = BatchNormalization(axis=-1, momentum=0.99, epsilon=1e-3, center=True, scale=True)(x) x = Bidirectional(CuDNNGRU(128, return_sequences=True), merge_mode='sum')(x) x = Bidirectional(CuDNNGRU(128, return_sequences=True), merge_mode='sum')(x) x = Bidirectional(CuDNNGRU(128, return_sequences=False), merge_mode='sum')(x) x = BatchNormalization(axis=-1, momentum=0.99, epsilon=1e-3, center=True, scale=True)(x) #Flatten layer # x = Flatten()(x) #Dense Layer 1 x = Dense(256, activation='relu')(x) outputs = Dense(len(labels), activation="softmax")(x) model = Model(inputs, outputs) model.summary()
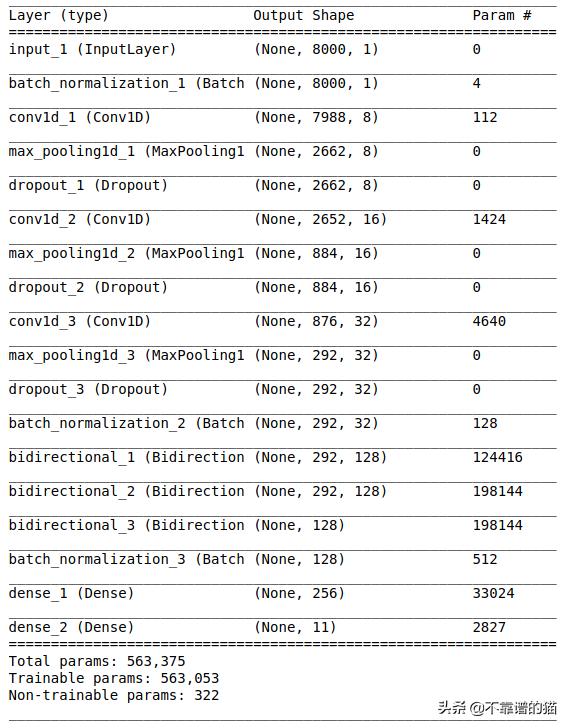
注意:如果僅使用CPU來訓練此模型,請用GRU替換CuDNNGRU層。
下一步是將損失函數定義為分類交叉熵,因為它是一個多類分類問題:
model.compile(loss='categorical_crossentropy',optimizer='nadam',metrics=['accuracy'])
Early stopping和模型檢查點是回調,以在適當的時間停止訓練神經網絡并在每個epoch后保存最佳模型:
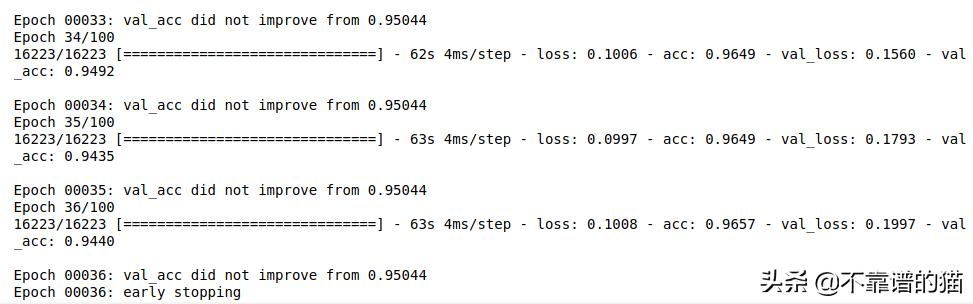
early_stop = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10, min_delta=0.0001) checkpoint = ModelCheckpoint('speech3text_model.hdf5', monitor='val_acc', verbose=1, save_best_only=True, mode='max')讓我們在32的batch size上訓練機器學習模型,并評估保留集上的性能:
hist = model.fit( x=x_train, y=y_train, epochs=100, callbacks=[early_stop, checkpoint], batch_size=32, validation_data=(x_valid,y_valid) )
該命令的輸出為:
5.可視化
我將依靠可視化來了解機器學習模型在一段時間內的性能:
from matplotlib import pyplot pyplot.plot(hist.history['loss'], label='train') pyplot.plot(hist.history['val_loss'], label='test') pyplot.legend() pyplot.show()
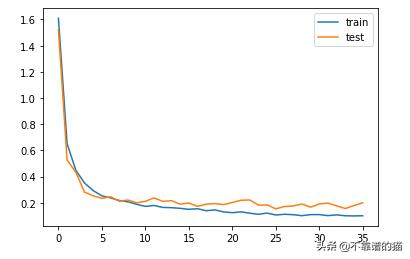
6.預測
在這一步中,我們將加載最佳的權重,并定義識別音頻和將其轉換為文本的函數:
from keras.models import load_model model = load_model('speech3text_model.hdf5') def s2t_predict(audio, shape_num=8000): prob=model.predict(audio.reshape(1,shape_num,1)) index=np.argmax(prob[0]) return classes[index]對驗證數據進行預測:
import random index=random.randint(0,len(x_valid)-1) samples=x_valid[index].ravel() print("Audio:",classes[np.argmax(y_valid[index])]) ipd.Audio(samples, rate=8000)這是一個提示用戶錄制語音命令的腳本。可以錄制自己的語音命令,并在機器學習模型上測試:
import sounddevice as sd import soundfile as sf samplerate = 16000 duration = 1 # seconds filename = 'yes.wav' print("start") mydata = sd.rec(int(samplerate * duration), samplerate=samplerate, channels=1, blocking=True) print("end") sd.wait() sf.write(filename, mydata, samplerate)最后,我們創建一個腳本來讀取保存的語音命令并將其轉換為文本:
#reading the voice commands test, test_rate = librosa.load('./test/left.wav', sr = 16000) test_sample = librosa.resample(test, test_rate, 4351) print(test_sample.shape) ipd.Audio(test_sample,rate=8000) #converting voice commands to text s2t_predict(test_sample)最后
語音識別技術已經成為我們日常生活的一部分,但目前仍局限于相對簡單的命令。隨著技術的進步,研究人員將能夠創造出更多能夠理解會話語音的智能系統。
關于如何使用Python和創建簡單語音識別引擎問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





