溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
re 模塊為Python的內置模塊,Python程序中通過這個模塊來使用正則表達式。
re 模塊有兩種使用方式,示例中以match方法為例。
方式 1:
步驟:
1)直接使用 re.match 方法(傳入正則表達式和需要匹配的字符串)對文本進行匹配查找,match方法返回一個 Match 對象
2)使用 Match 對象提供的方法獲取匹配結果示例:
import re
m = re.match(r'\d+', '123abc456') # 返回一個 Match 對象
print(m.group()) # 輸出匹配結果:123方式 2:
步驟:
1)使用 re.compile 方法(傳入正則表達式)得到 Pattern 對象
2)通過 Pattern 對象提供的方法對字符串進行匹配查找,返回一個 Match 對象(包含了匹配結果)
3)使用 Match 對象提供的方法獲取匹配結果示例:
import re
pattern = re.compile(r'\d+') # 返回一個 Pattern 對象
m = pattern.match('123abc456') # 返回一個 Match 對象
print(m.group()) # 輸出匹配結果:123如上2種方式的區別在于,第二種方式通過 re.compile 方法獲取一個 Pattern 對象,使得一個正則表達式被多次用于匹配;而第一種方式,每一次的匹配都需要傳入正則表達式。
re.compile(pattern[, flag])示例中的 compile 方法用于編譯正則表達式,返回一個 Pattern 對象,可利用 Pattern 對象中的一系列方法對字符串進行匹配查找。Pattern 對象中的常用方法包括:match,search,findall,finditer,split,sub,subn。當然這些方法也可以使用 re模塊直接調用~
match 方法用于從字符串的頭部開始匹配,僅返回第一個匹配的結果~
pattern.match(string[, pos[, endpos]])
或
re.match(pattern, string[, flags])pattern.match(string[, pos[, endpos]]) 中的 pos,endpos指定字符串匹配的起始和終止位置,這兩個均為可選參數,若不指定,默認從字符串的開頭開始匹配~
?
re.match(pattern, string[, flags]) 中的pattern為傳入的正則表達式,flags指定匹配模式,如忽略大小寫,多行模式,同compile方法中的flag參數~
?
可以通過在正則表達式中使用小括號'()',來對匹配到的數據進行分組,然后通過group([n]),groups()獲取對應的分組數據。
import re
pattern = re.compile('([0-9]*)([a-z]*)([0-9]*)')
m = pattern.match('123abc456')
# 輸出匹配的完整字符串
print(m.group()) # 123abc456
# 同上,輸出匹配的完整字符串
print(m.group(0)) # 123abc456
# 從匹配的字符串中獲取第一個分組
print(m.group(1)) # 123
# 從匹配的字符串中獲取第二個分組
print(m.group(2)) # abc
# 從匹配的字符串中獲取第三個分組
print(m.group(3)) # 456
# 從匹配的字符串中獲取所有分組,返回為元組
print(m.groups()) # ('123', 'abc', '456')
# 獲取第二個分組 在字符串中的起始位置(分組第一個字符的索引),start方法的默認參數為0,即字符串的起始索引
print(m.start(2)) # 3
# 獲取第二個分組 在字符串中的起始位置(分組最后一個字符的索引+1),通start方法,end方法的默認參數也為0,即字符串結尾的索引+1
print(m.end(2)) # 6
# 第三個分組的起始和結束位置,即 (start(3), end(3))
print(m.span(3)) # (6, 9)
# 同 (start(), end())
print(m.span()) # (0, 9)上述中的 group(),groups(),start(),end(),span() 方法均為 Match類中的方法,這些方法主要用于從匹配的字符串中(或者說是從 Match對象中)獲取相關信息~
re 模塊中較為常用的方法除了 compile() 和 match() 方法,還有下面列出的這些~
不同于match方法的從頭開始匹配,search方法用于在字符串中的進行查找(從左向右進行查找),只要找到一個匹配結果,就返回 Match 對象,若沒有則返回None~
search(string[, pos[, endpos]])
# 可選參數 pos,endpos 用于指定查找的起始位置和結束位置,默認 pos 為0,endpos為字符串長度示例:re.search
import re
pattern = re.compile(r'[a-z]+')
m = pattern.match('123abc456cde')
print(m) # None
m = pattern.search('123abc456cde') # 或者 m = re.search(r'[a-z]+', '123abc456')
print(m.group()) # abc由于match是從頭開始匹配,所以這里匹配不到結果~
match方法 和search方法 僅會返回一個結果,findall方法會將字符串中的所有匹配結果以列表的形式返回,注意,返回的是列表,不是 Match 對象~
findall(string[, pos[, endpos]])
# 可選參數 pos,endpos 用于指定查找的起始位置和結束位置,默認 pos 為0,endpos為字符串長度示例:
import re
pattern = re.compile(r'[a-z]+')
res = pattern.findall('123abc456cde')
print(res)
# 執行結果:
['abc', 'cde']findall方法的優先級查詢,findall方法會優先把匹配結果組里的內容進行返回,來看如下示例:
import re
pattern = re.compile('\d([a-z]+)\d')
print(pattern.findall('123abc456'))
# 輸出結果:
['abc']?
其實我們想要的結果是 '3abc4',但是findall方法會優先返回分組中的內容,即 'abc'。若要想要匹配結果,取消權限即可,就是在小括號的起始位置加上 '?:'
import re
pattern = re.compile('\d(?:[a-z]+)\d')
print(pattern.findall('123abc456'))
# 輸出結果:
['3abc4']finditer 方法與 findall方法類似,會查找整個字符串并返回所有匹配的結果,返回的是一個迭代器,且每一個元素為 Match 對象~
import re
pattern = re.compile(r'\d+')
res = pattern.finditer('#123abc456cde')
for i in res:
print(i.group())
# 輸出結果:
123
456split方法用于將字符串進行切割,切割使用的分隔符就是字符串中被匹配到的子串,將被切割后的子串以列表的形式返回~
split(string[, maxsplit])
# maxsplit 參數用于指定最大分割次數,默認會將這個字符串分割示例:
import re
pattern = re.compile(r'\d+')
m = pattern.split('abc23de3fgh4456ij') # 或者直接 re.split('\d+','abc23de3fgh4ij')
print(m)
# 結果輸出:
['abc', 'de', 'fgh', 'ij']正則表達式中添加括號后,則會保留分隔符
import re
ret = re.split("(\d+)", "abc23de3fgh4456ij")
print(ret)
# 結果輸出”
['abc', '23', 'de', '3', 'fgh', '3456', 'ij']sub方法用于將字符串中匹配的子串替換為指定的字符串
pattern.sub(repl, string[, count])
或者
re.sub(pattern, repl, string[, count])count為可選參數,指定最大替換次數,repl 可以是一個字符串,也可以是一個 \id 引用匹配到的分組(但不能使用 \0),還可以是一個方法,該方法僅接受一個參數(Match對象),且返回一個字符串~
1)repl 是一個字符串
import re
ret = re.sub(r'\d+', '###', 'abc123cde')
print(ret)
# 輸出結果:
abc###cde2)repl 是一個分組引用
將類似于 'hello world' 這樣的字符串前后兩個單詞替換~
import re
ret = re.sub(r'(\w+) (\w+)', r'\2 \1', 'hello world; hello kitty')
print(ret)
# 輸出結果:
world hello; kitty hello3)repl是一個方法
import re
def func(m):
return 'hi' + ' ' + m.group(2)
ret = re.sub(r'(\w+) (\w+)', func, 'hello world; hello kitty')
print(ret)
# 輸出結果:
hi world; hi kittysubn方法和sub方法類似,subn方法會返回一個元組,元組有兩個元素,第一個元素與sub方法返回的結果一致,第二個元素為字符串中被替換的子串個數
import re
def func(m):
return 'hi' + ' ' + m.group(2)
ret = re.subn(r'\d+', '###', 'abc123cde')
print(ret)
ret = re.subn(r'(\w+) (\w+)', r'\2 \1', 'hello world; hello kitty')
print(ret)
ret = re.subn(r'(\w+) (\w+)', func, 'hello world; hello kitty')
print(ret)
# 輸出結果:
('abc###cde', 1)
('world hello; kitty hello', 2)
('hi world; hi kitty', 2)正則匹配默認使用的就是貪婪匹配,也就是盡可能的多匹配,如下示例為貪婪匹配:
import re
m = re.match('[a-z]+', 'abc123def')
print(m.group())
# 輸出結果:
abc同一示例使用非貪婪匹配,在正則后面加上一個 '?' 即可,注意這個問號不是代表0個或者一個(注意區分):
import re
m = re.match('[a-z]+?', 'abc123def')
print(m.group())
# 輸出結果:
a?
貪婪匹配(單單使用 ?),?重復0個或者1個,貪婪模式下匹配一個
ret=re.findall('13\d?','1312312312, 134, 34234, 2313')
print(ret)
# 輸出結果:
['131', '134', '13']?
惰性匹配示例:
ret=re.findall('131\d+?','1312312312')
print(ret)
# 輸出結果:
['1312']1、反斜杠后邊跟元字符去除特殊功能, 比如.
2、反斜杠后邊跟普通字符實現特殊功能, 比如\d
\d 匹配任何十進制數; 它相當于類 [0-9]。
\D 匹配任何非數字字符; 它相當于類 [^0-9]。
\s 匹配任何空白字符; 它相當于類 [ \t\n\r\f\v]。
\S 匹配任何非空白字符; 它相當于類 [^ \t\n\r\f\v]。
\w 匹配任何字母數字字符; 它相當于類 [a-zA-Z0-9_]。
\W 匹配任何非字母數字字符; 它相當于類 [^a-zA-Z0-9_]
\b 匹配一個特殊字符邊界,比如空格 ,&,#等?
讓我們看一下 \b 的應用:
ret=re.findall(r'I\b','I am LIST')
print(ret) # ['I']?
Tip:
如上示例中 ret=re.findall(r'I\b','I am LIST') 使用的是 r'I\b' 而不能使用 'I\b' ,解釋如下:
Python程序在這里的執行過程分為2步:
第一步:python 解釋器讀取 'I\b' 字符串進行解析,解析完成后傳遞給 re 模塊
第二步:re 模塊 對接收到的字符串進行解析?
在第一步中,'\b' 和 '\n' 類似,對于Python解釋器而言,有特殊的意義,Python解釋器針對 '\b' 和 '\n' 會根據ASCII碼表進行翻譯,翻譯完成之后再傳遞給 re 模塊進行后續的處理;所以 re 模塊獲取到的不會是 原模原樣的 'I\b'。這里若要讓 re 模塊接收到原模原樣的 'I\b',有兩種方式:
1)在字符串中使用 \ ,將 \b 轉義
re.findall('I\\b','I am LIST')
2)直接在字符串前面加 r,使字符串中的 \b 失效,建議使用這種方式
re.findall(r'I\b','I am LIST')?
還有一種情況,要匹配的字符串本身就包含 '\' , 例如匹配 'hello\kitty' 中的 'o\k'
分析:\ 對于re 模塊而言,有轉義的意思,所以 re 模塊希望獲取到的字符串規則是 'o\k',也就是說Python解釋器解析完字符串后傳遞給 re 模塊的是 'o\k'(如果直接使用 re.findall('o\k','hello\kitty') ,re模塊獲取到的是 'o\k'),所以這里也有兩種實現方式:
1)re.findall(r'o\\k','hello\kitty') ,建議使用這種方式
2)針對2個 \ 分別進行轉義
re.findall('o\\\\k','hello\kitty')也許這里會有疑問,re.findall("1\d?", "123,12345235,124234,1,abc,13") ,為何這里的\d 可以直接使用,那是因為 \d 在ASCII碼表里面沒有對應的字符串(Python解釋器對 \d 不會進行翻譯),所以可以直接使用。ASCII碼表中和 '\' 連用的特殊字符見下圖: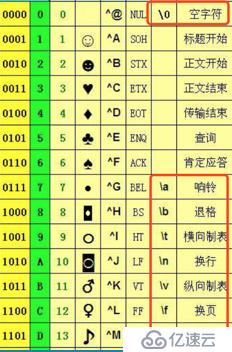
?
|表示 或者,使用 | 時一般需要和 括號配合使用,不然無法區分 | 的左邊與右邊
import re
ret = re.search('(ab)|\d','#@123abc') # 匹配 ab 或者 數字,search僅會返回第一個匹配到的
print(ret.group()) # 1import re
# [bc] 表示僅匹配 b 或者 c,如下示例中表示,匹配 abd 或者 acd
ret = re.findall('a[bc]d','acd')
print(ret) #['acd']
# [a-zA-Z] : 所有大小寫字母
# [a-zA-Z0-9] : 所有大小寫字母及數字
# [a-zA-Z0-9_] : 所有大小寫字母及數字,再加上一個下劃線
ret = re.findall('[a-z]','acd') # 匹配所有小寫字母
print(ret) #['a', 'c', 'd']
# 注意:元字符在 字符集[] 中沒有任何效果,這里的 . 和 + 就是普通的符號,有效果的元字符包括:- ^ \
ret = re.findall('[.*+]','a.cd+')
print(ret) #['.', '+']
# - 表示范圍符號
ret = re.findall('[1-9]','45dha3') # 匹配數字 1 至 9
print(ret) #['4', '5', '3']
# ^ 表示取反,即匹配 非a,非b的字符
ret = re.findall('[^ab]','45bdha3')
print(ret) #['4', '5', 'd', 'h', '3']
# \ 為轉義符
ret = re.findall('[\d]','45bdha3')
print(ret) #['4', '5', '3'].................^_^
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





