溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“數據科學家該了解的Python自動庫有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“數據科學家該了解的Python自動庫有哪些”吧!
1.auto-sklearn
auto-sklearn是一個自動機器學習工具包,無縫集成業內許多人都熟悉的標準sklearn界面。通過使用貝葉斯優化等最新方法,構建庫來導航可能的模型空間,并學習推斷特定的配置是否能很好地完成給定任務。
這個庫是由Matthias Feurer等人創建,其技術細節在一篇名為《高效和魯棒機器學習》的論文中進行了描述。Feurer寫道:“我們引入了一個基于scikit-learn的新魯棒性自動系統——使用15個分類器、14個特征預處理方法和4個數據預處理方法生成110個超參數的結構化假設空間。”
auto-sklearn可能是入門AutoML的最佳庫。除了挖掘數據集的數據準備和模型選擇之外,它還能學習類似數據集上性能良好的模型。

圖源:Efficient and Robust Automated Machine Learning(2015)
在有效實施的基礎上,auto-sklearn將所需用戶交互降至最低。可以使用pip install auto-sklearn來安裝庫。
可以使用的兩大類是Auto Sklearn Classifier和Auto Sklearn Regressor,分別用于分類和回歸任務。兩者都有相同的用戶指定參數,其中最重要的是時間限制和集成大小。
import autosklearn as ask #ask.regression.AutoSklearnRegressor()for regression tasks model =ask.classification.AutoSklearnClassifier(ensemble_size=10, #size of the endensemble (minimum is 1) time_left_for_this_task=120, #the number ofseconds the process runs for per_run_time_limit=30) #maximum secondsallocated per model model.fit(X_train, y_train) #begin fittingthe search model print(model.sprint_statistics()) #printstatistics for the search y_predictions = model.predict(X_test) #get predictionsfrom the model
2.TPOT
TPOT是另一個自動化建模管道的Python庫,它更強調數據準備、建模算法和模型超參數。它通過一種進化的基于樹結構自動化特征選擇、預處理和構造,“該結構稱為基于樹管道優化工具(TPOT),可以自動設計和優化機器學習管道。”
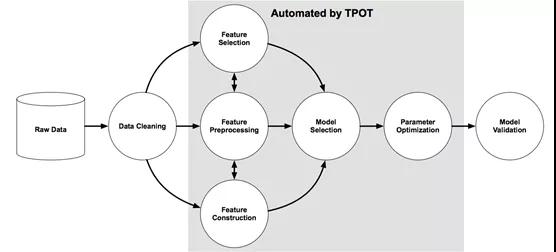
圖源:數據科學自動化中基于樹的流水線優化工具的評價(2016)
程序或管道以樹狀圖呈現。遺傳程序選擇并進化某些程序,以最大化每個自動機器學習管道的最終結果。
正如Pedro Domingos所說:“一個擁有大量數據的愚蠢算法勝過一個擁有有限數據的聰明算法。”事實確實如此,TPOT可以生成復雜的數據預處理管道。
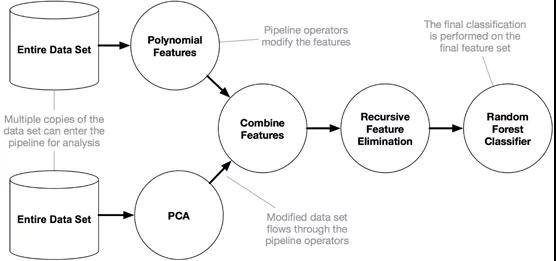
圖源:TPOT documentation
就像許多AutoML算法一樣,TPOT管道優化器可能要花幾個小時才能產生好的結果,你可以在Kaggle commits或者谷歌Colab中運行這些長時間的程序。
import tpot pipeline_optimizer = tpot.TPOTClassifier(generations=5, #number ofiterations to run the training population_size=20, #number ofindividuals to train cv=5) #number of foldsin StratifiedKFold pipeline_optimizer.fit(X_train, y_train) #fit thepipeline optimizer - can take a long time print(pipeline_optimizer.score(X_test, y_test)) #print scoringfor the pipeline pipeline_optimizer.export( tpot_exported_pipeline.py ) #export thepipeline - in Python code!
也許TPOT的最佳特性是可以將模型導出為Python代碼文件,方便以后使用。
3.HyperOpt
由James Bergstra開發的HyperOpt是一個用于貝葉斯優化的Python庫。為大規模優化具有數百個參數的模型而設計,該庫明確用于優化機器學習管道,并具有在多個核和機器之間擴展優化過程的選項。
“我們的方法是公開一個性能度量(例如驗證示例上的分類精度)如何從超參數計算的底層表達式圖,這些超參數不僅控制單個處理步驟的應用,而且甚至控制包含哪些處理步驟。”
然而,HyperOpt很難直接使用,因為它存在技術壁壘,需要仔細指定優化過程和參數。我建議使用HyperOpt-sklearn,這是一個包含sklearn庫的HyperOpt包裝器。
具體來說,盡管HyperOpt支持預處理,但其主要關注幾十個進入特定模型的超參數。考慮一次HyperOpt-sklearn搜索的結果,在沒有進行預處理的情況下,得到了一個梯度增強分類器:
{ learner : GradientBoostingClassifier(ccp_alpha=0.0, criterion= friedman_mse , init=None, learning_rate=0.009132299586303643, loss= deviance , max_depth=None, max_features= sqrt , max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=342, n_iter_no_change=None, presort= auto , random_state=2, subsample=0.6844206624548879, tol=0.0001, validation_fraction=0.1, verbose=0, warm_start=False), preprocs : (), ex_preprocs : ()}構建HyperOpt-sklearn模型的文檔提到,它比auto-sklearn要復雜得多,比TPOT稍微復雜一點。但如果超參數的作用很重要,那么多余的繁瑣工作也是值得的。
4.AutoKeras
與標準的機器學習庫相比,神經網絡和深度學習要強大得多,因此也更難實現自動化。
使用AutoKeras,神經結構搜索算法會找到最好的結構,比如一層中的神經元數量,層的數量,要合并的層,層的特定參數,比如過濾器的大小或Dropout中丟失的神經元的百分比等等。一旦搜索完成,就可以將其當作一個普通的TensorFlow/Keras模型來使用這個模型。
通過使用AutoKeras,你可以構建一個包含復雜元素的模型,比如嵌入和空間縮減,否則那些仍在摸索深度學習的人將很難獲得這些元素。
當AutoKeras創建模型時,已完成并優化許多預處理,如向量化或清理文本數據。
啟動和訓練搜索只需要兩行代碼。而AutoKeras擁有一個類似于keras的界面,所以它易于記憶和使用。
AutoKeras支持文本、圖像和結構化數據,并為初學者和那些希望深入技術知識的人提供接口,AutoKeras使用進化神經結構搜索方法來消除困難和歧義。盡管AutoKeras運行的時間很長,但有許多用戶指定的參數可用來控制運行時間、探索的模型數量、搜索空間大小等。
Hyperparameter |Value |BestValueSoFar text_block_1/block_type|transformer|transformer classification_head_1/dropout|0 |0 optimizer |adam |adam learning_rate |0.001 |0.001 text_block_1/max_tokens|20000 |20000 text_block_1/text_to_int_sequence_1/output_sequence_length|200 |200 text_block_1/transformer_1/pretraining|none |none text_block_1/transformer_1/embedding_dim|32 |32 text_block_1/transformer_1/num_heads|2 |2 text_block_1/transformer_1/dense_dim|32 |32 text_block_1/transformer_1/dropout|0.25 |0.25 text_block_1/spatial_reduction_1/reduction_type|global_avg|global_avg text_block_1/dense_block_1/num_layers|1 |1 text_block_1/dense_block_1/use_batchnorm|False |False text_block_1/dense_block_1/dropout|0.5 |0.5 text_block_1/dense_block_1/units_0|20 |20
應該使用哪一個自動庫呢?
如果你首選整潔、簡單的界面和相對快速的結果,請使用auto-sklearn。可以與sklearn的自然集成,與常用的模型和方法一起使用。
如果注重的是高精確度而不介意訓練所需消耗時間較長,可以使用TPOT。可通過用樹狀結構代表管道而達成其強調的先進預處理方法,它還能額外輸出最佳模型的Python代碼。
如果注重高精確度而不介意潛在的較長訓練時間,則使用HyperOpt-sklearn,強調模型的超參數優化是否有成效取決于數據集和算法。
如果你的問題涉及神經網絡,特別是文本或圖像形式的問題,請使用AutoKeras。其訓練確實需要很長時間,但有大量的措施可以控制時間和搜索空間的大小。
想實現自動化,千萬不要錯過這四個庫。
到此,相信大家對“數據科學家該了解的Python自動庫有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





