溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Linux在多核可擴展性設計上的有哪些不足,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
我其實并不想討論微內核的概念,也并不擅長去闡述概念,這是百科全書的事,但無奈最近由于鴻蒙的發布導致這個話題過火,也就經不住誘惑,加上我又一直比較喜歡操作系統這個話題,就來個老生常談吧。
說起微內核,其性能往往因為IPC飽受詬病。然而除了這個顯而易見的 “缺陷” ,其它方面貌似被關注的很少。因此我寫點稍微不同的。
微內核的性能 “缺陷” 我假設是高開銷的IPC引起的(實際上也真是),那么,我接下來便繼續假設這個IPC性能是可以優化的,并且它已經被優化(即便不做任何事,隨著硬件技術的發展,所謂的歷史缺點往往也將逐漸弱化...)。我不公道地回避了核心問題,這并不是很道德,但為了下面的行文順利,我不得不這么做。
很多人之所以并不看好微內核,很大程度上是因為它和Linux內核是如此不同,人們認為不同于Linux內核的操作系統內核都有這樣那樣的缺陷,這是因為Linux內核給我們洗了腦。
Linux內核的設計固化了人們對操作系統內核的理解上的觀念 ,以至于 Linux內核做什么都是對的,反Linux的大概率是錯的。 Linux內核就一定正確嗎?
在我看來,Linux內核只是在恰當的時間出現的一個恰好能跑的內核,并且恰好它是開源的,讓人們可以第一次內窺一個操作系統內核的全貌罷了,這并不意味著它就一定是正確的。相反,它很可能是錯誤的。【 20世紀90年代,Windows NT系統初始,但很難看到它的內在,《windows internal》風靡一時;UNIX陷入糾紛,GNU呼之卻不出,此時Linux內核滿足了人們一切的好奇心,于是先入為主,讓人們覺的操作系統就應該是這個樣子,并且在大多數人看來,這是它唯一的相貌。 】
本文主要說 內核的可擴展性 。
先潑一盆冷水,Linux內核在這方面做得并非已經爐火純青。
誠然,近十幾年來Linux內核從2.6發展到5.3,一直在SMP多核擴展方面精益求精,但是說實話架構上并沒有什么根本性的調整,要說比較大的調整,當屬:
$O(1)$調度算法。
SMP處理器域負載均衡算法。
percpu數據結構。
數據結構拆鎖。
都是一些細節,沒有什么讓人哇塞的東西,還有更細節的cache刷新的管理,這種第二天不用就忘記的東西,引多少人競折腰。
這不禁讓人想起在交換式以太網出現之前,人們不斷優化CSMA/CD算法的過程,同樣沒有讓人哇塞,直到交換機的出現,讓人眼前一亮,CSMA/CD隨之幾乎被完全廢棄,因為它不是 正確 的東西。
交換機之所以 正確 的核心在于 仲裁。
當一個共享資源每次只能容納一個實體占用訪問時,我們稱該資源為 “必須串行訪問的共享資源” ,當有多個實體均意欲訪問這種資源時,one by one是必然的,one by one的方案有兩種:
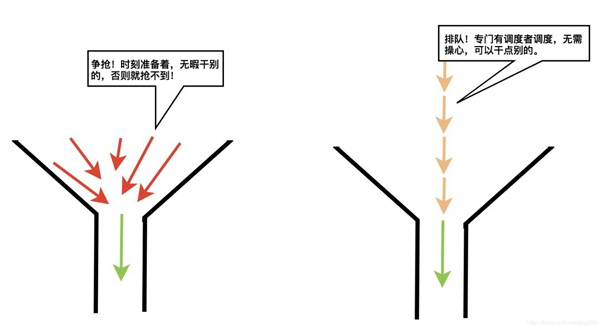
哪個好?說說看。
爭搶必會產生沖突,沖突便耽誤整體通過的時間,你會選哪個?
現在,我們暫時忘掉諸如宏內核,微內核,進程隔離,進程切換,cache刷新,IPC等概念,這些概念對于我們理解事情的本質毫無幫助,相反,它們會阻礙我們建立新的認知。比如,無論你覺得微內核多么好,總有人跳出來說IPC是微內核的瓶頸,當你提出一個類似頁表項交換等優化后,又會有人說進程切換刷cache,寄存器上下文save/restore的開銷也不小,然后你可能知道點 帶有進程PID鍵值的cache方案 ,吧啦吧啦,最后一個show me the code 讓你無言以對,一來二去,還沒有認識全貌,便已經陷入了細節。
所以,把這些忘掉,來看一個觀點:
對待必須串行訪問的共享資源,正確的做法是引入一個仲裁者排隊調度訪問者,而不是任由訪問者們去并發爭鎖!
所謂 操作系統 這個概念,本來就是莫須有的,你可以隨便叫它什么,早期它叫 監視器 ,現在我們姑且就叫它操作系統吧,但這并不意味著這個概念有多么神奇。
操作系統本就是用來協調多個進程(這也是個抽象后的概念,你叫它任務也可以,無所謂)對底層共享資源的 多對一訪問 的,最典型的資源恐怕就是CPU資源了,而幾乎所有人都知道,CPU資源是需要調度使用的,于是任務調度一直都是一個熱門話題。
你看, CPU就不是所有任務并發爭搶使用的,而是調度器讓誰用誰才能用 。調度,或者說仲裁,這是操作系統的精髓。
那么對于系統中共享的文件,socket,對于各種表比如路由表等資源,憑什么要用并發爭搶的方式去使用?!所有的共享資源,都應該是被調度使用的,就像CPU資源一樣。
如果我們循著操作系統理應實現的最本質的功能去思考,而不是以Linux作為先入為主的標準去思考,會發現Linux內核處理并發明顯是一種錯誤的方式!
Linux內核大量使用了自旋鎖,這明顯是從單核向SMP進化時最最最簡單的方案,即 只要保證不出問題的方案!
也確實如此,單核上的自旋鎖并不能如其字面表達的那樣 自旋 , 在單核場景下,Linux的自旋鎖實現僅僅是 禁用了搶占 。因為,這樣即可保證 不出問題 。
但到了必須要支持SMP的時候,簡單的禁用搶占已經無法保證不出問題,所以 待在原地自旋等待持鎖者離開 便成了最顯而易見的方案。自旋鎖就這樣一直用到了現在。一直到今天,自旋鎖在不斷被優化,然而無論怎么優化,它始終都是一個不合時宜的自旋鎖。
可見,Linux內核一開始就不是為SMP設計的,因此其并發模式是錯誤的,至少不是合適的。
有破就要有立,我下面將用一套用戶態的代碼來模擬 無仲裁的宏內核 以及 有仲裁的微內核 分別是如何對待共享資源訪問的。代碼比較簡單,所以我就沒加入太多的注釋。
以下的代碼模擬宏內核中訪問共享資源時的自旋鎖并發爭搶模式:
#include <pthread.h> #include <signal.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <errno.h> #include <sys/time.h> static int count = 0; static int curr = 0; static pthread_spinlock_t spin; long long end, start; int timer_start = 0; int timer = 0; long long gettime() { struct timeb t; ftime(&t); return 1000 * t.time + t.millitm; } void print_result() { printf("%d\n", curr); exit(0); } struct node { struct node *next; void *data; }; void do_task() { int i = 0, j = 2, k = 0; // 為了更加公平的對比,既然模擬微內核的代碼使用了內存分配,這里也fake一個。 struct node *tsk = (struct node*) malloc(sizeof(struct node)); pthread_spin_lock(&spin); // 鎖定整個訪問計算區間 if (timer && timer_start == 0) { struct itimerval tick = {0}; timer_start = 1; signal(SIGALRM, print_result); tick.it_value.tv_sec = 10; tick.it_value.tv_usec = 0; setitimer(ITIMER_REAL, &tick, NULL); } if (!timer && curr == count) { end = gettime(); printf("%lld\n", end - start); exit(0); } curr ++; for (i = 0; i < 0xff; i++) { // 做一些稍微耗時的計算,模擬類似socket操作。強度可以調整,比如0xff->0xffff,CPU比較猛比較多的機器上做測試,將其調強些,否則隊列開銷會淹沒模擬任務的開銷。 k += i/j; } pthread_spin_unlock(&spin); free(tsk); } void* func(void *arg) { while (1) { do_task(); } } int main(int argc, char **argv) { int err, i; int tcnt; pthread_t tid; count = atoi(argv[1]); tcnt = atoi(argv[2]); if (argc == 4) { timer = 1; } pthread_spin_init(&spin, PTHREAD_PROCESS_PRIVATE); start = gettime(); // 創建工作線程 for (i = 0; i < tcnt; i++) { err = pthread_create(&tid, NULL, func, NULL); if (err != 0) { exit(1); } } sleep(3600); return 0; }相對的,微內核采用將請求通過IPC發送到專門的服務進程,模擬代碼如下:
#include <pthread.h> #include <signal.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <errno.h> #include <sys/time.h> static int count = 0; static int curr = 0; long long end, start; int timer = 0; int timer_start = 0; static int total = 0; long long gettime() { struct timeb t; ftime(&t); return 1000 * t.time + t.millitm; } struct node { struct node *next; void *data; }; void print_result() { printf("%d\n", total); exit(0); } struct node *head = NULL; struct node *current = NULL; void insert(struct node *node) { node->data = NULL; node->next = head; head = node; } struct node* delete() { struct node *tempLink = head; headhead = head->next; return tempLink; } int empty() { return head == NULL; } static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; static pthread_spinlock_t spin; int add_task() { struct node *tsk = (struct node*) malloc(sizeof(struct node)); pthread_spin_lock(&spin); if (timer || curr < count) { curr ++; insert(tsk); } pthread_spin_unlock(&spin); return curr; } // 強度可以調整,比如0xff->0xffff,CPU比較猛比較多的機器上做測試,將其調強些,否則隊列開銷會淹沒模擬任務的開銷。 void do_task() { int i = 0, j = 2, k = 0; for (i = 0; i < 0xff; i++) { k += i/j; } } void* func(void *arg) { int ret; while (1) { ret = add_task(); if (!timer && ret == count) { break; } } } void* server_func(void *arg) { while (timer || total != count) { struct node *tsk; pthread_spin_lock(&spin); if (empty()) { pthread_spin_unlock(&spin); continue; } if (timer && timer_start == 0) { struct itimerval tick = {0}; timer_start = 1; signal(SIGALRM, print_result); tick.it_value.tv_sec = 10; tick.it_value.tv_usec = 0; setitimer(ITIMER_REAL, &tick, NULL); } tsk = delete(); pthread_spin_unlock(&spin); do_task(); free(tsk); total++; } end = gettime(); printf("%lld %d\n", end - start, total); exit(0); } int main(int argc, char **argv) { int err, i; int tcnt; pthread_t tid, stid; count = atoi(argv[1]); tcnt = atoi(argv[2]); if (argc == 4) { timer = 1; } pthread_spin_init(&spin, PTHREAD_PROCESS_PRIVATE); // 創建服務線程 err = pthread_create(&stid, NULL, server_func, NULL); if (err != 0) { exit(1); } start = gettime(); // 創建工作線程 for (i = 0; i < tcnt; i++) { err = pthread_create(&tid, NULL, func, NULL); if (err != 0) { exit(1); } } sleep(3600); return 0; }我們對比一下執行同樣多的任務,在不同的線程數的約束下,兩種模式的時間開銷對比圖:
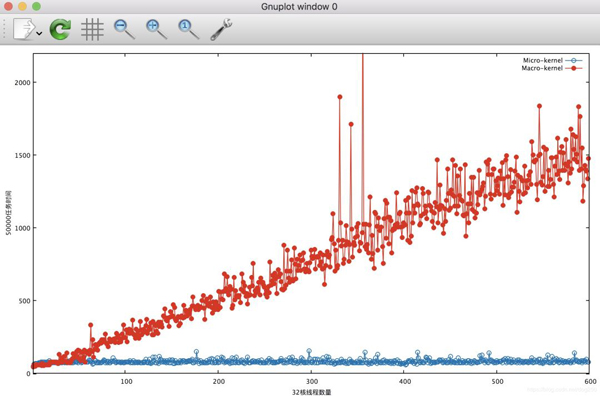
我們看到,在模擬微內核的代碼中,用多線程執行并行訪問共享數據curr時,開銷不會隨著線程數量的變化而變化,而模擬宏內核的代碼中,總時間隨著線程數的增加而線性增加,顯然,這部分開銷是自旋鎖的開銷。當今流行的CPU cache結構已經排隊自旋鎖的開銷符合這種線性增長。
那么為什么微內核的模擬代碼中的鎖開銷沒有隨著線程數量的增加而增加呢?
因為在類似宏內核的同步任務中,由于并發上下文的相互隔離,整個任務必須被一個鎖保護,比如 Linux內核的tcp_v4_rcv 里面的:
bh_lock_sock_nested(sk); // 這部分耗時時間不確定,因此CPU空轉率不確定,低效,浪費! ret = 0; if (!sock_owned_by_user(sk)) { if (!tcp_prequeue(sk, skb)) ret = tcp_v4_do_rcv(sk, skb); } else if (unlikely(sk_add_backlog(sk, skb, sk->sk_rcvbuf + sk->sk_sndbuf))) { bh_unlock_sock(sk); NET_INC_STATS_BH(net, LINUX_MIB_TCPBACKLOGDROP); goto discard_and_relse; } bh_unlock_sock(sk);然而,在微內核的代碼中,類似上面的任務被打包統一交給單獨的服務線程去 調度執行 了,大大減少了鎖區里的延時。
宏內核的隔離上下文并發搶鎖場景需要鎖整個任務,造成搶鎖開銷巨大,而微內核只要鎖任務隊列的入隊出隊操作即可,這部分開銷和具體任務無關,完全可預期的開銷。
接下來讓我們對比一下執行同樣的任務,在不同CPU數量的約束下,兩種模式的時間開銷對比圖:
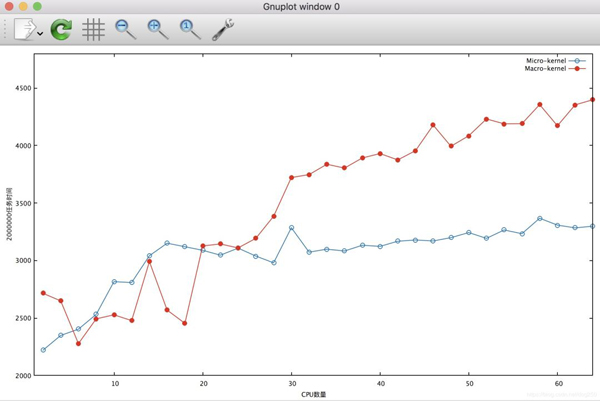
可見,隨著CPU數量的增加,模擬宏內核的代碼鎖開銷大致在線性增加,而模擬微內核的代碼,鎖開銷雖然也有所增加,但顯然并不明顯。
為什么會這樣?請看下面宏內核和微內核的對比圖,先看宏內核:
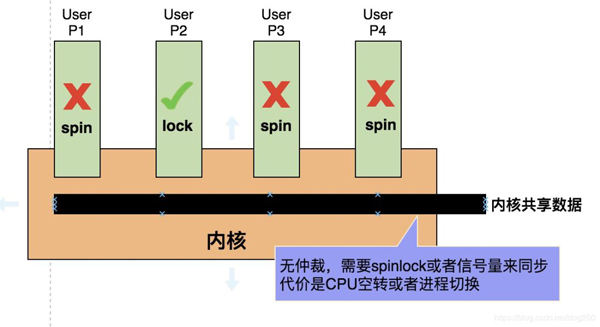
再看微內核:
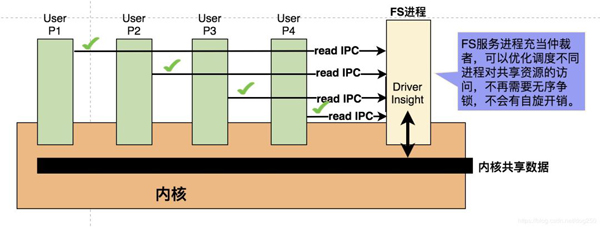
這顯然是一種更加 現代 的方式,不光是減小了鎖的開銷提高了性能,更重要的是大大減少了CPU的空轉,提高了CPU的利用率。
我們先看一下模擬宏內核的代碼在執行10秒時的CPU利用率:
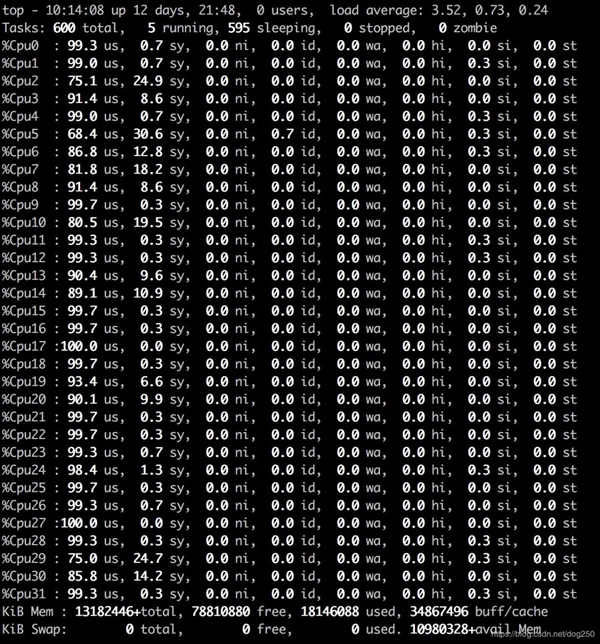
觀察下熱點,可以猜測就是spinlock:

顯然,CPU利用率那么高,并非真的在執行有用的task,而是在spin空轉。
我們再看下模擬微內核的代碼在同樣情況下的表現:
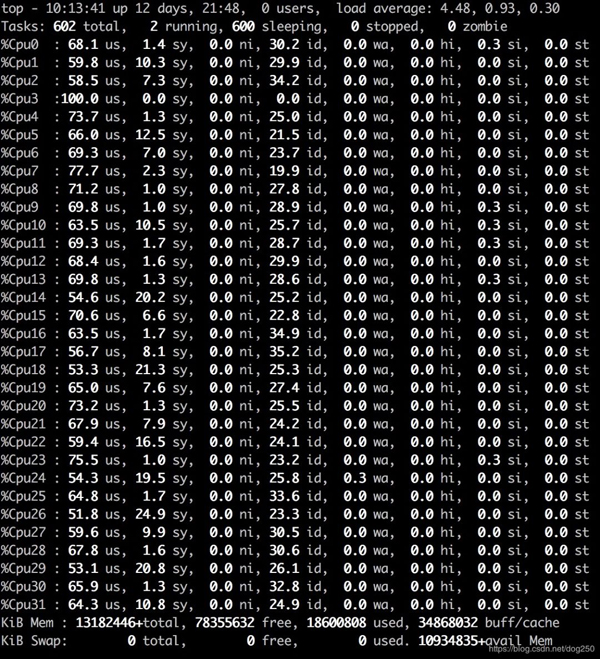
看下熱點:

顯然,仍然有個spinlock的熱點,但顯然降低了很多。在更高執行效率的保證下,CPU并沒有那么高,剩余的空閑時間可以再去執行更多有意義的工作進程。
本文只是展示一個定性的效果,實際中,微內核服務進程的任務隊列的管理效率會更高。甚至可以硬件實現。【參見交換機背板的交換網絡實現。】
說了這么多,也許有人會說, NO,你這兩個比對的case不嚴謹,你只模擬了訪問共享的數據,如果是真的可并行執行的代碼用微內核的方案豈不是要降低性能嗎?平白自廢武功,將并行改成串行!確實如此,但是 內核本身就是共享的。 操作系統本身就是協調用戶進程對底層共享資源訪問的。
所以真并行需要程序員自己來 設計可并行的應用程序。
內核本身就是共享的。共享資源的多線程訪問就應該嚴格串行化,并發爭鎖是一種最無序的方式,而最有效的方式則是統一仲裁調度。
在我們日常生活中,我們顯然能看到和理解為什么排隊上車比擁擠著上車更加高效。在計算機系統領域,同樣的事情我們也見于交換式以太網和PCIe,相比CSMA/CD的共享式以太網,交換機就是一個仲裁調度器,PCIe的消息hub也是扮演著同樣的角色。
其實,即便是宏內核,在訪問共享資源時,也并不是全都是并發爭鎖的方式,對于敏感度比較高的資源,比如時延要求很高的硬件資源,系統底層也是仲裁調度實現的,比如網卡上層發包的隊列調度程序,此外對于磁盤IO也有對應的磁盤調度程序。
然而對于宏內核,更加上層的邏輯資源,比如VFS文件對象,socket對象,各種隊列等等卻沒有采用仲裁調度的方式去訪問,當它們由多個線程并發訪問時,采用了令人遺憾的并發爭鎖模式,這也是不得已而為之,因為沒有哪個實體可以完成仲裁,畢竟訪問它們的上下文是隔離的。
來個插敘。當進行Linux系統調優時,瞄準這些方面相關的熱點基本就夠了。大量熱點問題都是這種引起的,open/close同一個文件,進程上下文和軟中斷同時操作同一個socket,收包時多個CPU上的軟中斷上下文將包排入同一個隊列,諸如此類。\如果你不準備去調優Linux,或許你已經知道Linux內核在SMP環境下的根本缺陷,調它作甚。多看看外面的世界,搞不好比你眼前唯一的那個要好。
當我們評價傳統UNIX以及Linux這種操作系統內核時,應該更多的去看它們缺失了什么,而不是一味的覺得它們就是對的。【你認為它是的,可能僅僅因為它是你第一個見到并且唯一見過的】
如果非要說下概念,那就有必要說說 現代操作系統 的虛擬機抽象。
對于我們經常說的 現代操作系統 而言,按照最初的馮諾伊曼結構,只有 “CPU和內存” 在 多處理(包括所有的多進程,多線程等機制) 機制中被抽象了出來,而對于文件系統,網絡協議棧等等卻沒有進行多處理抽象。換句話說,現代操作系統為進程提供了 獨占的虛擬機抽象 ,該虛擬機僅僅包括CPU和內存:
時間片調度讓進程認為自己獨占了CPU。
虛擬內存讓進程認為自己獨享了內存。
再無其它虛擬機抽象。
在進程使用這些抽象資源時,現代操作系統無疑采用了仲裁調度機制:
操作系統提供任務調度器仲裁CPU的分時復用(典型的是多級反饋優先級隊列算法),為進程/線程統一分配物理CPU的時間片資源。
操作系統提供內存分配算法仲裁物理內存空間的分配(典型的是伙伴系統算法),為進程/線程統一分配物理內存映射給虛擬內存。
顯然,正如本文開頭說過的,操作系統并未任由進程們去并發爭搶CPU和內存資源,然而對于其它幾乎所有資源,操作系統并未做任何嚴格的規定。操作系統以兩種態度對待它們:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
認為其它資源并非操作系統核心的一部分,于是微內核,用戶態驅動等等就形成了概念。
認為其它底層的資源也是操作系統核心的一部分,這就是宏內核比如Linux的態度。
態度如何,這并不重要,宏內核,微內核,用戶態,內核態,這些也只是概念而已,沒有什么大不了的。關鍵的問題乃是:
如何協調共享資源的分配。 或空間資源,或時間資源的或并發爭鎖,或仲裁調度的方式分配。
無疑,最大的爭議就在CPU/內存之外如何協調非進程虛擬化的文件系統的訪問和網絡協議棧的訪問。但無論它們倆的哪一個,目前無論是宏內核還是微內核都有非常非常棒的方案。遺憾的是,這些很棒的方案都不是Linux內核所采用的方案。
哦,對了Nginx便采取了類似微內核,交換機,PCIe的方法,Apache卻不是。還有很多別的例子,不再一一贅述,只是想說一點,操作系統領域,核心的東西都是大象無形的,而不是那些形形色色的概念。
摘錄一段王垠聊微內核時的一段話:
跟有些人聊操作系統是件鬧心的事,因為我往往會拋棄一些術語和概念,從零開始討論。我試圖從“計算本質”的出發點來理解這類事物,理解它們的起因,發展,現狀和可能的改進。我所關心的往往是“這個事物應該是什么樣子”,“它還可以是什么(也許更好的)樣子”,而不只是“它現在是什么樣子”。不明白我的這一特性,又自恃懂點東西的人,往往會誤以為我連基本的術語都不明白。于是天就這樣被他們聊死了。
這其實也是我想說的。
so,忘掉微內核,宏內核,忘掉內核態,用戶態,忘掉實模式,保護模式,這樣你會更深刻地理解如何仲裁共享資源的訪問的本質。
關于Linux在多核可擴展性設計上的有哪些不足就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





