溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python中怎么利用KNN算法處理缺失數據,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
KNN代表" K最近鄰居",這是一種簡單算法,可根據定義的最接近鄰居數進行預測。 它計算從您要分類的實例到訓練集中其他所有實例的距離。
正如標題所示,我們不會將算法用于分類目的,而是填充缺失值。 本文將使用房屋價格數據集,這是一個簡單而著名的數據集,僅包含500多個條目。
這篇文章的結構如下:
數據集加載和探索
KNN歸因
歸因優化
結論
數據集加載和探索
如前所述,首先下載房屋數據集。 另外,請確保同時導入了Numpy和Pandas。 這是前幾行的外觀:
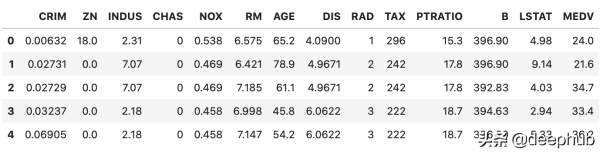
默認情況下,數據集缺失值非常低-單個屬性中只有五個:

讓我們改變一下。 您通常不會這樣做,但是我們需要更多缺少的值。 首先,我們創建兩個隨機數數組,其范圍從1到數據集的長度。 第一個數組包含35個元素,第二個數組包含20個(任意選擇):
i1 = np.random.choice(a=df.index, size=35) i2 = np.random.choice(a=df.index, size=20)
這是第一個數組的樣子:

您的數組將有所不同,因為隨機化過程是隨機的。 接下來,我們將用NAN替換特定索引處的現有值。 這是如何做:
df.loc[i1, 'INDUS'] = np.nan df.loc[i2, 'TAX'] = np.nan
現在,讓我們再次檢查缺失值-這次,計數有所不同:

這就是我們從歸因開始的全部前置工作。 讓我們在下一部分中進行操作。
KNN歸因
整個插補可歸結為4行代碼-其中之一是庫導入。 我們需要sklearn.impute中的KNNImputer,然后以一種著名的Scikit-Learn方式創建它的實例。 該類需要一個強制性參數– n_neighbors。 它告訴冒充參數K的大小是多少。
首先,讓我們選擇3的任意數字。稍后我們將優化此參數,但是3足以啟動。 接下來,我們可以在計算機上調用fit_transform方法以估算缺失的數據。
最后,我們將結果數組轉換為pandas.DataFrame對象,以便于解釋。 這是代碼:
from sklearn.impute import KNNImputer imputer = KNNImputer(n_neighbors=3) imputed = imputer.fit_transform(df) df_imputed = pd.DataFrame(imputed, columns=df.columns)
非常簡單。 讓我們現在檢查缺失值:

盡管如此,仍然存在一個問題-我們如何為K選擇正確的值?
歸因優化
該住房數據集旨在通過回歸算法進行預測建模,因為目標變量是連續的(MEDV)。 這意味著我們可以訓練許多預測模型,其中使用不同的K值估算缺失值,并查看哪個模型表現最佳。
但首先是導入。 我們需要Scikit-Learn提供的一些功能-將數據集分為訓練和測試子集,訓練模型并進行驗證。 我們選擇了"隨機森林"算法進行訓練。 RMSE用于驗證:
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error rmse = lambda y, yhat: np.sqrt(mean_squared_error(y, yhat))
以下是執行優化的必要步驟:
迭代K的可能范圍-1到20之間的所有奇數都可以
使用當前的K值執行插補
將數據集分為訓練和測試子集
擬合隨機森林模型
預測測試集
使用RMSE進行評估
聽起來很多,但可以歸結為大約15行代碼。 這是代碼段:
def optimize_k(data, target): errors = [] for k in range(1, 20, 2): imputer = KNNImputer(n_neighbors=k) imputed = imputer.fit_transform(data) df_imputed = pd.DataFrame(imputed, columns=df.columns) X = df_imputed.drop(target, axis=1) y = df_imputed[target] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) model = RandomForestRegressor() model.fit(X_train, y_train) preds = model.predict(X_test) error = rmse(y_test, preds) errors.append({'K': k, 'RMSE': error}) return errors現在,我們可以使用修改后的數據集(在3列中缺少值)調用optimize_k函數,并傳入目標變量(MEDV):
k_errors = optimize_k(data=df, target='MEDV')
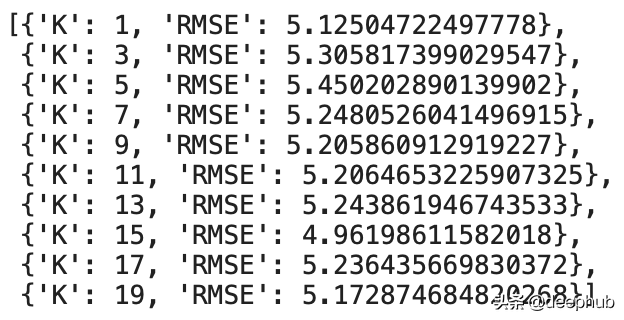
就是這樣! k_errors數組如下所示:
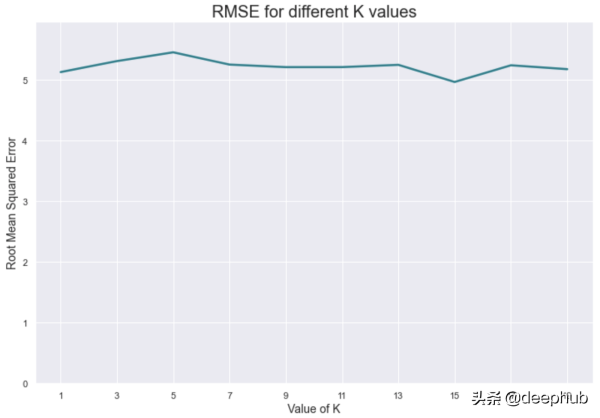
以視覺方式表示:
關于Python中怎么利用KNN算法處理缺失數據就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





