溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Python中如何使用中文變量名,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
Python3.x 已經支持全面 Unicode 編碼,比如支持使用中文作為變量名。
>>> 姓名 ="Python貓" >>> print(f"我是{姓名},歡迎關注!") 我是Python貓,歡迎關注!由于我手頭上沒有其它樣本,所以,我不確定有多少新版的書籍還在使用老的規則。但是,翻譯類的書籍大概率都會有這樣的問題,另外,有些不嚴謹的國內書籍,也可能因為借鑒了過時的材料而犯錯。
如此一來,恐怕有些新接觸 Python 的同學,就會形成錯誤的認識。雖然這可能不會造成嚴重的問題,但是它終歸是一個應該避免而且很容易就能避免的問題。
因此,我覺得這個話題值得聊一聊。
在編程語言中有一個很常見的概念,即標識符(identifier),通常又會稱之為名字(name),用于標識出變量、常量、函數、類、符號等實體的名字。
在定義標識符時,有一些必須要考慮的基本規則:
它可以由哪些字符組成?
它是否區分大小寫?(即大小寫敏感)
它是否允許出現某些特殊的單詞?(即關鍵字/保留字)
對于第一個問題,大多數的編程語言在早期版本都遵循這條規則:標識符由字母、數字和下劃線組成,并且不能以數字為開頭。 少數的編程語言有例外,還支持使用$、@、%等特殊符號(例如PHP、Ruby、Perl等等)。
Python 的早期版本,確切地說是 3.0 之前的版本,就遵循以上的命名規則。下面是官方文檔中的描述:
identifier ::= (letter|"_") (letter | digit | "_")* letter ::= lowercase | uppercase lowercase ::= "a"..."z" uppercase ::= "A"..."Z" digit ::= "0"..."9"
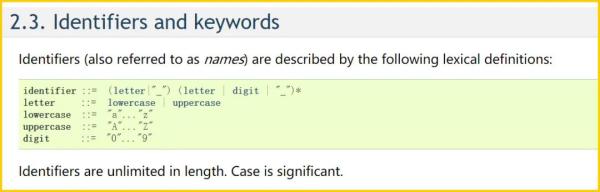
出處:https://docs.python.org/2.7/reference/lexical_analysis.html#identifiers
但是,這條規則從 3.0 版本起,就被打破了。最新的官方文檔已經變成了這樣:
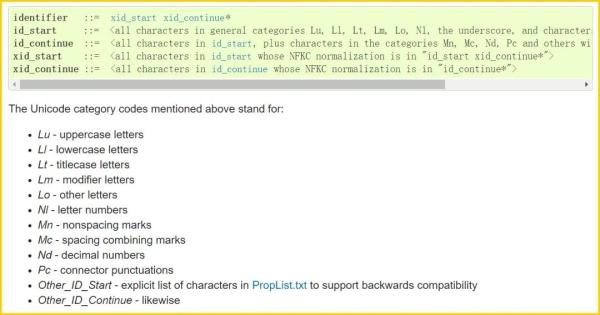
出處:https://docs.python.org/3/reference/lexical_analysis.html#identifiers
隨著互聯網的普及,各國語言進入了國際化的語境中,編程語言也與時俱進地增長了對國際化的訴求。
Unicode(譯作統一碼、萬國碼)編碼標準在 1994 年發布,隨后逐步被主流的編程語言所接納。到目前為止,至少有 73 種編程語言支持 Unicode 變量名(數據依據:https://rosettacode.org/wiki/Unicode_variable_names)。
2007 年,當 Python 正在設計劃時代的 3.0 版本時,官方也考慮了對 Unicode 編碼的支持,于是,誕生了重要的《PEP 3131 -- Supporting Non-ASCII Identifiers》。

出處:https://www.python.org/dev/peps/pep-3131
事實上,除了我們最關心的中文,Unicode 字符集還包含非常非常多的內容。
在對變量命名時,下面這些用法都是可行的(謹慎使用,如若被打,本貓概不負責……):
>>> ψ = 1 >>> Δ = 1 >>> ?_? = "hello"
上述就是小編為大家分享的Python中如何使用中文變量名了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





