溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python怎么實現多線程的事件監控”,在日常操作中,相信很多人在Python怎么實現多線程的事件監控問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python怎么實現多線程的事件監控”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
設想這樣一個場景:
你創建了10個子線程,每個子線程分別爬一個網站,一開始所有子線程都是阻塞等待。一旦某個事件發生:例如有人在網頁上點了一個按鈕,或者某人在命令行輸入了一個命令,10個爬蟲同時開始工作。
肯定有人會想到用Redis來實現這個開關:所有子線程全部監控Redis中名為start_crawl的字符串,如果這個字符串不存在,或者為0,那么就等待1秒鐘,再繼續檢查。如果這個字符串為1,那么就開始運行。
代碼片段可以簡寫為:
import time import redis client = redis.Redis() while client.get('start_crawl') != 1: print('繼續等待') time.sleep(1)這樣做確實可以達到目的,不過每一個子線程都會頻繁檢查Redis。
實際上,在Python的多線程中,有一個Event模塊,天然就是用來實現這個目的的。
Event是一個能在多線程中共用的對象,一開始它包含一個為False的信號標志,一旦在任一一個線程里面把這個標記改為True,那么所有的線程都會看到這個標記變成了True。
我們通過一段代碼來說明它的使用方法:
import threading import time class spider(threading.Thread): def __init__(self, n, event): super().__init__() self.n = n self.event = event def run(self): print(f'第{self.n}號爬蟲已就位!') self.event.wait() print(f'信號標記變為True!!第{self.n}號爬蟲開始運行') eve = threading.Event() for num in range(10): crawler = spider(num, eve) crawler.start() input('按下回車鍵,啟動所有爬蟲!') eve.set() time.sleep(10)運行效果如下圖所示:
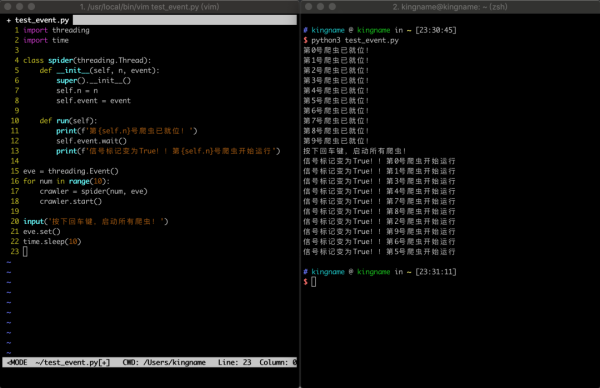
在這段代碼中,線程spider在運行以后,會運行到self.event.wait()這一行,然后10個子線程會全部阻塞在這里。而這里的self.event,就是主線程中eve = threading.Event()生成的對象傳入進去的。
在主線程里面,當執行了eve.set()后,所有子線程的阻塞會被同時解除,于是子線程就可以繼續運行了。
到此,關于“Python怎么實現多線程的事件監控”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





