溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何Java中的hashCode()方法”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何Java中的hashCode()方法”吧!
Object 類中就包含了 hashCode() 方法:
@HotSpotIntrinsicCandidate public native int hashCode();
意味著所有的類都會有一個 hashCode() 方法,該方法會返回一個 int 類型的值。由于 hashCode() 方法是一個本地方法(native 關鍵字修飾的方法,用 C/C++ 語言實現,由 Java 調用),意味著 Object 類中并沒有給出具體的實現。
具體的實現可以參考 jdk/src/hotspot/share/runtime/synchronizer.cpp(源碼可以到 GitHub 上 OpenJDK 的倉庫中下載)。get_next_hash() 方法會根據 hashCode 的取值來決定采用哪一種哈希值的生成策略。
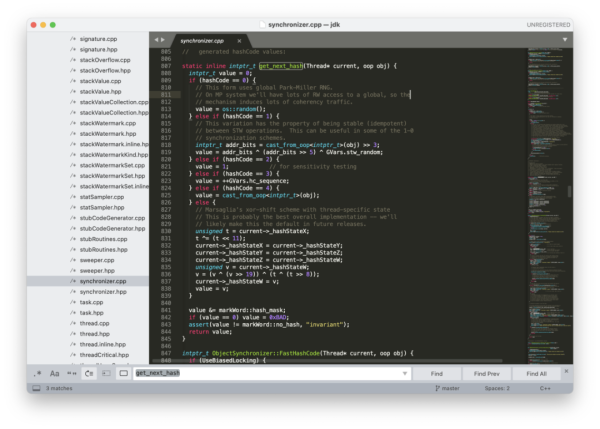
并且 hashCode() 方法被 @HotSpotIntrinsicCandidate 注解修飾,說明它在 HotSpot 虛擬機中有一套高效的實現,基于 CPU 指令。
那大家有沒有想過這樣一個問題:為什么 Object 類需要一個 hashCode() 方法呢?
在 Java 中,hashCode() 方法的主要作用就是為了配合哈希表使用的。
哈希表(Hash Table),也叫散列表,是一種可以通過關鍵碼值(key-value)直接訪問的數據結構,它最大的特點就是可以快速實現查找、插入和刪除。其中用到的算法叫做哈希,就是把任意長度的輸入,變換成固定長度的輸出,該輸出就是哈希值。像 MD5、SHA1 都用的是哈希算法。
像 Java 中的 HashSet、Hashtable(注意是小寫的 t)、HashMap 都是基于哈希表的具體實現。其中的 HashMap 就是最典型的代表,不僅面試官經常問,工作中的使用頻率也非常的高。
大家想一下,如果沒有哈希表,但又需要這樣一個數據結構,它里面存放的數據是不允許重復的,該怎么辦呢?
要不使用 equals() 方法進行逐個比較?這種方案當然是可行的。但如果數據量特別特別大,采用 equals() 方法進行逐個對比的效率肯定很低很低,最好的解決方案就是哈希表。
拿 HashMap 來說吧。當我們要在它里面添加對象時,先調用這個對象的 hashCode() 方法,得到對應的哈希值,然后將哈希值和對象一起放到 HashMap 中。當我們要再添加一個新的對象時:
獲取對象的哈希值;
和之前已經存在的哈希值進行比較,如果不相等,直接存進去;
如果有相等的,再調用 equals() 方法進行對象之間的比較,如果相等,不存了;
如果不等,說明哈希沖突了,增加一個鏈表,存放新的對象;
如果鏈表的長度大于 8,轉為紅黑樹來處理。
就這么一套下來,調用 equals() 方法的頻率就大大降低了。也就是說,只要哈希算法足夠的高效,把發生哈希沖突的頻率降到最低,哈希表的效率就特別的高。
來看一下 HashMap 的哈希算法:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }先調用對象的 hashCode() 方法,然后對該值進行右移運算,然后再進行異或運算。
通常來說,String 會用來作為 HashMap 的鍵進行哈希運算,因此我們再來看一下 String 的 hashCode() 方法:
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { hash = h = isLatin1() ? StringLatin1.hashCode(value) : StringUTF16.hashCode(value); } return h; } public static int hashCode(byte[] value) { int h = 0; int length = value.length >> 1; for (int i = 0; i < length; i++) { h = 31 * h + getChar(value, i); } return h; }可想而知,經過這么一系列復雜的運算,再加上 JDK 作者這種大師級別的設計,哈希沖突的概率我相信已經降到了最低。
當然了,從理論上來說,對于兩個不同對象,它們通過 hashCode() 方法計算后的值可能相同。因此,不能使用 hashCode() 方法來判斷兩個對象是否相等,必須得通過 equals() 方法。
也就是說:
如果兩個對象調用 equals() 方法得到的結果為 true,調用 hashCode() 方法得到的結果必定相等;
如果兩個對象調用 hashCode() 方法得到的結果不相等,調用 equals() 方法得到的結果必定為 false;
反之:
如果兩個對象調用 equals() 方法得到的結果為 false,調用 hashCode() 方法得到的結果不一定不相等;
如果兩個對象調用 hashCode() 方法得到的結果相等,調用 equals() 方法得到的結果不一定為 true;
來看下面這段代碼。
public class Test { public static void main(String[] args) { Student s1 = new Student(18, "張三"); Map<Student, Integer> scores = new HashMap<>(); scores.put(s1, 98); System.out.println(scores.get(new Student(18, "張三"))); } } class Student { private int age; private String name; public Student(int age, String name) { this.age = age; this.name = name; } @Override public boolean equals(Object o) { Student student = (Student) o; return age == student.age && Objects.equals(name, student.name); } }我們重寫了 Student 類的 equals() 方法,如果兩個學生的年紀和姓名相同,我們就認為是同一個學生,雖然很離譜,但我們就是這么草率。
在 main() 方法中,18 歲的張三考試得了 98 分,很不錯的成績,我們把張三和成績放到了 HashMap 中,然后準備輸出張三的成績:
null
很不巧,結果為 null,而不是預期當中的 98。這是為什么呢?
原因就在于重寫 equals() 方法的時候沒有重寫 hashCode() 方法。默認情況下,hashCode() 方法是一個本地方法,會返回對象的存儲地址,顯然 put() 中的 s1 和 get() 中的 new Student(18, "張三") 是兩個對象,它們的存儲地址肯定是不同的。
HashMap 的 get() 方法會調用 hash(key.hashCode()) 計算對象的哈希值,雖然兩個不同的 hashCode() 結果經過 hash() 方法計算后有可能得到相同的結果,但這種概率微乎其微,所以就導致 scores.get(new Student(18, "張三")) 無法得到預期的值 18。
怎么解決這個問題呢?很簡單,重寫 hashCode() 方法。
@Override public int hashCode() { return Objects.hash(age, name); }Objects 類的 hash() 方法可以針對不同數量的參數生成新的 hashCode() 值。
public static int hashCode(Object a[]) { if (a == null) return 0; int result = 1; for (Object element : a) result = 31 * result + (element == null ? 0 : element.hashCode()); return result; }代碼似乎很簡單,歸納出的數學公式如下所示(n 為字符串長度)。
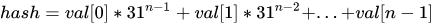
注意:31 是個奇質數,不大不小,一般質數都非常適合哈希計算,偶數相當于移位運算,容易溢出,造成數據信息丟失。
這就意味著年紀和姓名相同的情況下,會得到相同的哈希值。scores.get(new Student(18, "張三")) 就會返回 98 的預期值了。
《Java 編程思想》這本圣經中有一段話,對 hashCode() 方法進行了一段描述。
設計 hashCode() 時最重要的因素就是:無論何時,對同一個對象調用 hashCode() 都應該生成同樣的值。如果在將一個對象用 put() 方法添加進 HashMap 時產生一個 hashCode() 值,而用 get() 方法取出時卻產生了另外一個 hashCode() 值,那么就無法重新取得該對象了。所以,如果你的 hashCode() 方法依賴于對象中易變的數據,用戶就要當心了,因為此數據發生變化時,hashCode() 就會生成一個不同的哈希值,相當于產生了一個不同的鍵。
也就是說,如果在重寫 hashCode() 和 equals() 方法時,對象中某個字段容易發生改變,那么最好舍棄這些字段,以免產生不可預期的結果。
好。有了上面這些內容作為基礎后,我們回頭再來看看本地方法 hashCode() 的 C++ 源碼。
static inline intptr_t get_next_hash(Thread* current, oop obj) { intptr_t value = 0; if (hashCode == 0) { // This form uses global Park-Miller RNG. // On MP system we'll have lots of RW access to a global, so the // mechanism induces lots of coherency traffic. value = os::random(); } else if (hashCode == 1) { // This variation has the property of being stable (idempotent) // between STW operations. This can be useful in some of the 1-0 // synchronization schemes. intptr_t addr_bits = cast_from_oop<intptr_t>(obj) >> 3; value = addr_bits ^ (addr_bits >> 5) ^ GVars.stw_random; } else if (hashCode == 2) { value = 1; // for sensitivity testing } else if (hashCode == 3) { value = ++GVars.hc_sequence; } else if (hashCode == 4) { value = cast_from_oop<intptr_t>(obj); } else { // Marsaglia's xor-shift scheme with thread-specific state // This is probably the best overall implementation -- we'll // likely make this the default in future releases. unsigned t = current->_hashStateX; t ^= (t << 11); current->_hashStateX = current->_hashStateY; current->_hashStateY = current->_hashStateZ; current->_hashStateZ = current->_hashStateW; unsigned v = current->_hashStateW; v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)); current->_hashStateW = v; value = v; } value &= markWord::hash_mask; if (value == 0) value = 0xBAD; assert(value != markWord::no_hash, "invariant"); return value; }如果沒有 C++ 基礎的話,不用細致去看每一行代碼,我們只通過表面去了解一下 get_next_hash() 這個方法就行。其中的 hashCode 變量是 JVM 啟動時的一個全局參數,可以通過它來切換哈希值的生成策略。
hashCode==0,調用操作系統 OS 的 random() 方法返回隨機數。
hashCode == 1,在 STW(stop-the-world)操作中,這種策略通常用于同步方案中。利用對象地址進行計算,使用不經常更新的隨機數(GVars.stw_random)參與其中。
hashCode == 2,使用返回 1,用于某些情況下的測試。
hashCode == 3,從 0 開始計算哈希值,不是線程安全的,多個線程可能會得到相同的哈希值。
hashCode == 4,與創建對象的內存位置有關,原樣輸出。
hashCode == 5,默認值,支持多線程,使用了 Marsaglia 的 xor-shift 算法產生偽隨機數。所謂的 xor-shift 算法,簡單來說,看起來就是一個移位寄存器,每次移入的位由寄存器中若干位取異或生成。所謂的偽隨機數,不是完全隨機的,但是真隨機生成比較困難,所以只要能通過一定的隨機數統計檢測,就可以當作真隨機數來使用。
至于更深層次的挖掘,涉及到數學知識和物理知識,就不展開了。畢竟菜是原罪。
到此,相信大家對“如何Java中的hashCode()方法”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





