溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Python中urllib庫和requests庫區別”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Python中urllib庫和requests庫區別”吧!
在使用Python爬蟲時,需要模擬發起網絡請求,主要用到的庫有requests庫和python內置的urllib庫,一般建議使用requests,它是對urllib的再次封裝。
那它們兩者有什么區別 ?
下面通過案例詳細的講解 ,了解他們使用的主要區別。
urllib庫的response對象是先創建http,request對象,裝載到reques.urlopen里完成http請求。
返回的是http,response對象,實際上是html屬性。使用.read().decode()解碼后轉化成了str字符串類型,decode解碼后中文字符能夠顯示出來。
例
from urllib import request #請求頭 headers = { "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36' } wd = {"wd": "中國"} url = "http://www.baidu.com/s?" req = request.Request(url, headers=headers) response = request.urlopen(req) print(type(response)) print(response) res = response.read().decode() print(type(res)) print(res)運行結果:
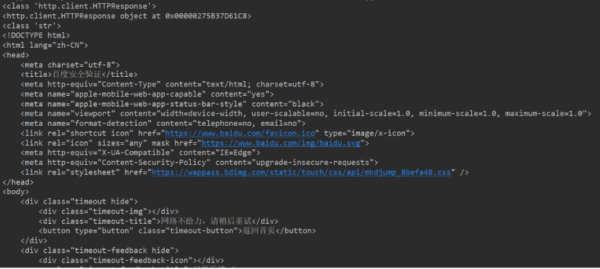
注意:
通常爬取網頁,在構造http請求的時候,都需要加上一些額外信息,什么Useragent,cookie等之類的信息,或者添加代理服務器。往往這些都是一些必要的反爬機制。
requests庫調用是requests.get方法傳入url和參數,返回的對象是Response對象,打印出來是顯示響應狀態碼。
通過.text 方法可以返回是unicode 型的數據,一般是在網頁的header中定義的編碼形式,而content返回的是bytes,二級制型的數據,還有 .json方法也可以返回json字符串。
如果想要提取文本就用text,但是如果你想要提取圖片、文件等二進制文件,就要用content,當然decode之后,中文字符也會正常顯示。
Python爬蟲時,更建議用requests庫。因為requests比urllib更為便捷,requests可以直接構造get,post請求并發起,而urllib.request只能先構造get,post請求,再發起。
例:
import requests headers = { "User-Agent": "Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36" } wd = {"wd": "中國"} url = "http://www.baidu.com/s?" response = requests.get(url, params=wd, headers=headers) data = response.text data2 = response.content print(response) print(type(response)) print(data) print(type(data)) print(data2) print(type(data2)) print(data2.decode()) print(type(data2.decode()))運行結果 (可以直接獲取整網頁的信息,打印控制臺):
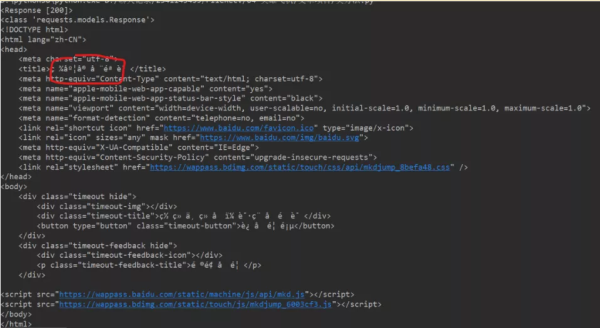
本文基于Python基礎,主要介紹了urllib庫和requests庫的區別。
在使用urllib內的request模塊時,返回體獲取有效信息和請求體的拼接需要decode和encode后再進行裝載。進行http請求時需先構造get或者post請求再進行調用,header等頭文件也需先進行構造。
requests是對urllib的進一步封裝,因此在使用上顯得更加的便捷,建議在實際應用當中盡量使用requests。
希望能給一些對爬蟲感興趣,有一個具體的概念。方法只是一種工具,試著去爬一爬會更容易上手,網絡也會有很多的坑,做爬蟲更需要大量的經驗來應付復雜的網絡情況。
到此,相信大家對“Python中urllib庫和requests庫區別”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





