溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Java基礎之MapReduce框架的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
MapTask就是Map階段的job,它的數量由切片決定
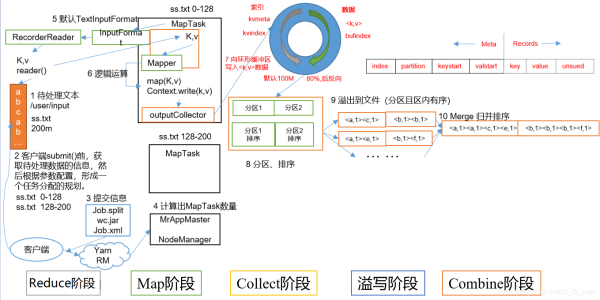
1.Read階段:讀取文件,此時進行對文件數據進行切片(InputFormat進行切片),通過切片,從而確定MapTask的數量,切片中包含數據和key(偏移量)
2.Map階段:這個階段是針對數據進行map方法的計算操作,通過該方法,可以對切片中的key和value進行處理
3.Collect收集階段:在用戶編寫map()函數中,當數據處理完成后,一般會調用OutputCollector.collect()輸出結果。在該函數內部,它會將生成的key/value分區(調用Partitioner),并寫入一個環形內存緩沖區中。
4.Spill階段:即“溢寫”,當環形緩沖區滿后,MapReduce會將數據寫到本地磁盤上,生成一個臨時文件。需要注意的是,將數據寫入本地磁盤之前,先要對數據進行一次本地排序,并在必要時對數據進行合并、壓縮等操作。
5.Combine階段:當所有數據處理完成后,MapTask對所有臨時文件進行一次合并,以確保最終只會生成一個數據文件,這個階段默認是沒有的,一般需要我們自定義
6.當所有數據處理完后,MapTask會將所有臨時文件合并成一個大文件,并保存到文件output/file.out中,同時生成相應的索引文件output/file.out.index。
7.在進行文件合并過程中,MapTask以分區為單位進行合并。對于某個分區,它將采用多輪遞歸合并的方式。每輪合并io.sort.factor(默認10)個文件,并將產生的文件重新加入待合并列表中,對文件排序后,重復以上過程,直到最終得到一個大文件。
8.讓每個MapTask最終只生成一個數據文件,可避免同時打開大量文件和同時讀取大量小文件產生的隨機讀取帶來的開銷
第四步溢寫階段詳情:
步驟1:利用快速排序算法對緩存區內的數據進行排序,排序方式是,先按照分區編號Partition進行排序,然后按照key進行排序。這樣,經過排序后,數據以分區為單位聚集在一起,且同一分區內所有數據按照key有序。
步驟2:按照分區編號由小到大依次將每個分區中的數據寫入任務工作目錄下的臨時文件output/spillN.out(N表示當前溢寫次數)中。如果用戶設置了Combiner,則寫入文件之前,對每個分區中的數據進行一次聚集操作。
步驟3:將分區數據的元信息寫到內存索引數據結構SpillRecord中,其中每個分區的元信息包括在臨時文件中的偏移量、壓縮前數據大小和壓縮后數據大小。如果當前內存索引大小超過1MB,則將內存索引寫到文件output/spillN.out.index中。
ReduceTask就是Reduce階段的job,它的數量由Map階段的分區進行決定

1.Copy階段:ReduceTask從各個MapTask上遠程拷貝一片數據,并針對某一片數據,如果其大小超過一定閾值,則寫到磁盤上,否則直接放到內存中。
2.Merge階段:在遠程拷貝數據的同時,ReduceTask啟動了兩個后臺線程對內存和磁盤上的文件進行合并,以防止內存使用過多或磁盤上文件過多。
3.Sort階段:按照MapReduce語義,用戶編寫reduce()函數輸入數據是按key進行聚集的一組數據。為了將key相同的數據聚在一起,Hadoop采用了基于排序的策略。由于各個MapTask已經實現對自己的處理結果進行了局部排序,因此,ReduceTask只需對所有數據進行一次歸并排序即可。
4.Reduce階段:reduce()函數將計算結果寫到HDFS上
我們在大數據開篇概述中說過,數據是低價值的,所以我們要從海量數據中獲取到我們想要的數據,首先就需要對數據進行清洗,這個過程也稱之為ETL
還記得上一章中的Join案例么,我們對pname字段的填充,也算數據清洗的一種,下面我通過一個簡單的案例來演示一下數據清洗
數據清洗案例
需求:過濾一下log日志中字段個數小于11的日志(隨便舉個栗子而已)
測試數據:就拿我們這兩天學習中HadoopNodeName產生的日志來當測試數據吧,我將log日志信息放到我的windows中,數據位置如下
/opt/module/hadoop-3.1.3/logs/hadoop-xxx-nodemanager-hadoop102.log
編寫思路:
直接通過切片,然后判斷長度即可,因為是舉個栗子,沒有那么復雜
真正的數據清洗會使用框架來做,這個我后面會為大家帶來相關的知識
ETLDriver
package com.company.etl;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class ETLDriver {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(ETLDriver.class);
job.setMapperClass(ETLMapper.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\io\\input8"));
FileOutputFormat.setOutputPath(job,new Path("D:\\io\\output88"));
job.waitForCompletion(true);
}
}ETLMapper
package com.company.etl;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ETLMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//清洗(過濾)
String line = value.toString();
String[] info = line.split(" ");
//判斷
if (info.length > 11){
context.write(value,NullWritable.get());
}
}
}顧名思義,計數器的作用就是用于計數的,在Hadoop中,它內部也有一個計數器,用于監控統計我們處理數據的數量
我們通常在MapReduce中通過上下文 context進行應用,例如在Mapper中,我通過step方法進行初始化計數器,然后在我們map方法中進行計數
在上面數據清洗的基礎上進行計數器的使用,Driver沒什么變化,只有Mapper
我們在Mapper的setup方法中,創建計數器的對象,然后在map方法中調用它即可
ETLMapper
package com.company.etl;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ETLMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
private Counter sucess;
private Counter fail;
/*
創建計數器對象
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
/*
getCounter(String groupName, String counterName);
第一個參數 :組名 隨便寫
第二個參數 :計數器名 隨便寫
*/
sucess = context.getCounter("ETL", "success");
fail = context.getCounter("ETL", "fail");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//清洗(過濾)
String line = value.toString();
String[] info = line.split(" ");
//判斷
if (info.length > 11){
context.write(value,NullWritable.get());
//統計
sucess.increment(1);
}else{
fail.increment(1);
}
}
}好了,到這里,我們MapReduce就全部學習完畢了,接下來,我再把整個內容串一下,還是MapReduce的那個圖
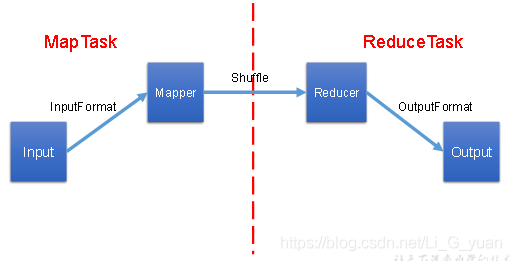
MapReduce的主要工作就是對數據進行運算、分析,它的工作流程如下:
1.我們會將HDFS中的數據通過InputFormat進行進行讀取、切片,從而計算出MapTask的數量
2.每一個MapTask中都會有Mapper類,里面的map方法就是任務的具體實現,我們通過它,可以完成數據的key,value封裝,然后通過分區進入shuffle中來完成每個MapTask中的數據分區排序
3.通過分區來決定ReduceTask的數量,每一個ReduceTask都有一個Reducer類,里面的reduce方法是ReduceTask的具體實現,它主要是完成最后的數據合并工作
4.當Reduce任務過重,我們可以通過Combiner合并,在Mapper階段來進行局部的數據合并,減輕Reduce的任務量,當然,前提是Combiner所做的局部合并工作不會影響最終的結果
5.當Reducer的任務完成,會將最終的key,value寫出,交給OutputFormat,用于數據的寫出,通過OutputFormat來完成HDFS的寫入操作
每一個MapTask和ReduceTask內部都是循環進行讀取,并且它有三個方法:setup() map()/reduce() cleanup()setup()方法是在MapTask/ReduceTask剛剛啟動時進行調用,cleanup()是在任務完成后調用
Java是一門面向對象編程語言,可以編寫桌面應用程序、Web應用程序、分布式系統和嵌入式系統應用程序。
以上是“Java基礎之MapReduce框架的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





