溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關怎么用JavaScript學習算法復雜度的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
1、能夠嵌入動態文本于HTML頁面。2、對瀏覽器事件做出響應。3、讀寫HTML元素。4、在數據被提交到服務器之前驗證數據。5、檢測訪客的瀏覽器信息。6、控制cookies,包括創建和修改等。7、基于Node.js技術進行服務器端編程。
在本文中,我們將探討 “二次方” 和 “n log(n)” 等術語在算法中的含義。
在后面的例子中,我將引用這兩個數組,一個包含 5 個元素,另一個包含 50 個元素。我還會用到JavaScript中方便的performance API來衡量執行時間的差異。
const smArr = [5, 3, 2, 35, 2]; const bigArr = [5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3, 2, 35, 2, 5, 3, 2, 35, 2];
Big O 表示法是用來表示隨著數據集的增加,計算任務難度總體增長的一種方式。盡管還有其他表示法,但通常 big O 表示法是最常用的,因為它著眼于最壞的情況,更容易量化和考慮。最壞的情況意味著完成任務需要最多的操作次數;如果你在一秒鐘內就能恢復打亂魔方,那么你只擰了一圈的話,不能說自己是做得最好的。
當你進一步了解算法時,就會發現這非常有用,因為在理解這種關系的同時去編寫代碼,就能知道時間都花在了什么地方。
當你了解更多有關 Big O 表示法的信息時,可能會看到下圖中不同的變化。我們希望將復雜度保持在盡可能低的水平,最好避免超過 O(n)。
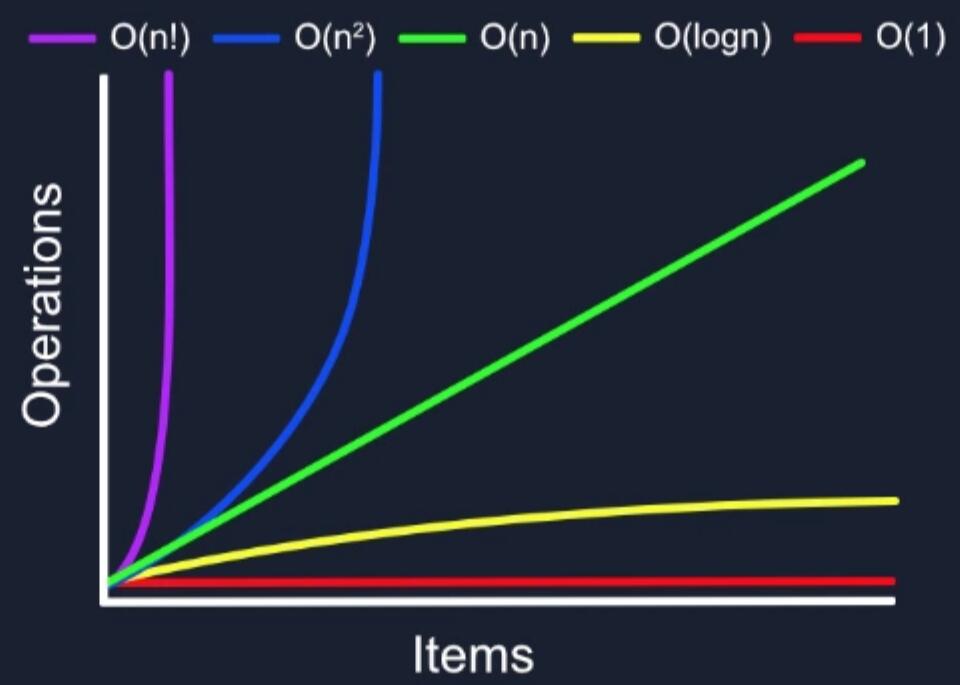
這是理想的情況,無論有多少個項目,不管是一個還是一百萬個,完成的時間量都將保持不變。執行單個操作的大多數操作都是 O(1)。把數據寫到數組、在特定索引處獲取項目、添加子元素等都將會花費相同的時間量,這與數組的長度無關。
const a1 = performance.now();
smArr.push(27);
const a2 = performance.now();
console.log(`Time: ${a2 - a1}`); // Less than 1 Millisecond
const b1 = performance.now();
bigArr.push(27);
const b2 = performance.now();
console.log(`Time: ${b2 - b1}`); // Less than 1 Millisecond在默認情況下,所有的循環都是線性增長的,因為數據的大小和完成的時間之間存在一對一的關系。所以如果你有 1,000 個數組項,將會花費的 1,000 倍時間。
const a1 = performance.now();
smArr.forEach(item => console.log(item));
const a2 = performance.now();
console.log(`Time: ${a2 - a1}`); // 3 Milliseconds
const b1 = performance.now();
bigArr.forEach(item => console.log(item));
const b2 = performance.now();
console.log(`Time: ${b2 - b1}`); // 13 Milliseconds指數增長是一個陷阱,我們都掉進去過。你是否需要為數組中的每個項目找到匹配對?將循環放入循環中是一種很好的方式,可以把 1000 個項目的數組變成一百萬個操作搜索,這將會使你的瀏覽器失去響應。與使用雙重嵌套循環進行一百萬次操作相比,最好在兩個單獨的循環中進行 2,000 次操作。
const a1 = performance.now();
smArr.forEach(() => {
arr2.forEach(item => console.log(item));
});
const a2 = performance.now();
console.log(`Time: ${a2 - a1}`); // 8 Milliseconds
const b1 = performance.now();
bigArr.forEach(() => {
arr2.forEach(item => console.log(item));
});
const b2 = performance.now();
console.log(`Time: ${b2 - b1}`); // 307 Milliseconds我認為關于對數增長最好的比喻,是想象在字典中查找像 “notation” 之類的單詞。你不會在一個詞條一個詞條的去進行搜索,而是先找到 “N” 這一部分,然后是 “OPQ” 這一頁,然后按字母順序搜索列表直到找到匹配項。
通過這種“分而治之”的方法,找到某些內容的時間仍然會因字典的大小而改變,但遠不及 O(n) 。因為它會在不查看大部分數據的情況下逐步搜索更具體的部分,所以搜索一千個項目可能需要少于 10 個操作,而一百萬個項目可能需要少于 20 個操作,這使你的效率最大化。
在這個例子中,我們可以做一個簡單的快速排序。
const sort = arr => {
if (arr.length < 2) return arr;
let pivot = arr[0];
let left = [];
let right = [];
for (let i = 1, total = arr.length; i < total; i++) {
if (arr[i] < pivot) left.push(arr[i]);
else right.push(arr[i]);
};
return [
...sort(left),
pivot,
...sort(right)
];
};
sort(smArr); // 0 Milliseconds
sort(bigArr); // 1 Millisecond最糟糕的一種可能性是析因增長。最經典的例子就是旅行的推銷員問題。如果你要在很多距離不同的城市之間旅行,如何找到在所有城市之間返回起點的最短路線?暴力方法將是檢查每個城市之間所有可能的路線距離,這是一個階乘并且很快就會失控。
由于這個問題很快會變得非常復雜,因此我們將通過簡短的遞歸函數演示這種復雜性。這個函數會將一個數字去乘以函數自己,然后將數字減去1。階乘中的每個數字都會這樣計算,直到為 0,并且每個遞歸層都會把其乘積添加到原始數字中。
階乘只是從 1 開始直至該數字的乘積。那么6!是1x2x3x4x5x6 = 720。
const factorial = n => {
let num = n;
if (n === 0) return 1
for (let i = 0; i < n; i++) {
num = n * factorial(n - 1);
};
return num;
};
factorial(1); // 2 Milliseconds
factorial(5); // 3 Milliseconds
factorial(10); // 85 Milliseconds
factorial(12); // 11,942 Milliseconds我原本打算顯示factorial(15),但是 12 以上的值都太多,并且使頁面崩潰了,這也證明了為什么需要避免這種情況。
感謝各位的閱讀!關于“怎么用JavaScript學習算法復雜度”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





