溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了在R語言中如何實現Logistic邏輯回歸的操作,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
R語言是用于統計分析、繪圖的語言和操作環境,屬于GNU系統的一個自由、免費、源代碼開放的軟件,它是一個用于統計計算和統計制圖的優秀工具。
邏輯回歸是擬合回歸曲線的方法,當y是分類變量時,y = f(x)。典型的使用這種模式被預測?給定一組預測的X。預測因子可以是連續的,分類的或兩者的混合。
R可以很容易地擬合邏輯回歸模型。要調用的函數是glm(),擬合過程與線性回歸中使用的過程沒有太大差別。在這篇文章中,我將擬合一個二元邏輯回歸模型并解釋每一步。
我們將研究泰坦尼克號數據集。這個數據集有不同版本可以在線免費獲得,但我建議使用Kaggle提供的數據集。
目標是預測生存(如果乘客幸存,則為1,否則為0)基于某些諸如服務等級,性別,年齡等特征。
我們將使用分類變量和連續變量。
在處理真實數據集時,我們需要考慮到一些數據可能丟失的情況,因此我們需要為我們的分析準備數據集。
作為第一步,我們使用該函數加載csv數據read.csv()。
使每個缺失值編碼為NA。
training.data.raw < - read.csv('train.csv',header = T,na.strings = c(“”))
現在我們需要檢查缺失的值,查看每個變量的唯一值,使用sapply()函數將函數作為參數傳遞給數據框的每一列。
PassengerId Survived Pclass Name Sex 0 0 0 0 0 Age SibSp Parch Ticket Fare 177 0 0 0 0 Cabin Embarked 687 2 length(unique(x))) PassengerId Survived Pclass Name Sex 891 2 3 891 2 Age SibSp Parch Ticket Fare 89 7 7 681 248 Cabin Embarked 148 4
對缺失值進行可視化處理可能會有所幫助:可以繪制數據集并顯示缺失值:
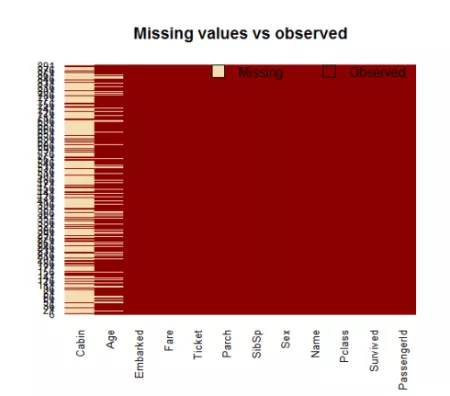
機艙有太多的缺失值,我們不使用它。
使用subset()函數我們對原始數據集進行子集化,只選擇相關列。
data < - subset(training.data.raw,select = c(2,3,5,6,7,8,10,12))
現在我們需要解釋其他缺失的值。通過在擬合函數內設置參數來擬合廣義線性模型時,R可以很容易地處理它們。
有不同的方法可以做到這一點,一種典型的方法是用現有的平均值,中位數或模式代替缺失值。我將使用平均值。
data$ Age [is.na(data $ Age)] < - mean(data$ Age,na.rm = T)
就分類變量而言,使用read.table()或read.csv()默認會將分類變量編碼為因子。
為了更好地理解R如何處理分類變量,我們可以使用contrasts()函數。
在進行擬合過程之前,先清潔和格式化數據。這個預處理步驟對于獲得模型的良好擬合和更好的預測能力通常是至關重要的。
我們將數據分成兩部分:訓練和測試集。訓練集將用于擬合我們的模型。
model <- glm(Survived ~.,family=binomial(link='logit'),data=train)
通過使用函數,summary()我們獲得了我們模型的結果:
Deviance Residuals: Min 1Q Median 3Q Max -2.6064 -0.5954 -0.4254 0.6220 2.4165 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 5.137627 0.594998 8.635 < 2e-16 *** Pclass -1.087156 0.151168 -7.192 6.40e-13 *** Sexmale -2.756819 0.212026 -13.002 < 2e-16 *** Age -0.037267 0.008195 -4.547 5.43e-06 *** SibSp -0.292920 0.114642 -2.555 0.0106 * Parch -0.116576 0.128127 -0.910 0.3629 Fare 0.001528 0.002353 0.649 0.5160 EmbarkedQ -0.002656 0.400882 -0.007 0.9947 EmbarkedS -0.318786 0.252960 -1.260 0.2076 --- Signif. codes: 0 ‘***' 0.001 ‘**' 0.01 ‘*' 0.05 ‘.' 0.1 ‘ ' 1
現在我們可以分析擬合并解釋模型告訴我們什么。
首先,我們可以看到SibSp,Fare和Embarked沒有統計意義。至于統計上顯著的變量,性別具有最低的p值,這表明乘客的性別與存活的可能性有很強的關聯。
預測因子的負系數表明所有其他變量相同,男性乘客不太可能存活下來。
由于男性是虛擬變量,因此男性將對數概率降低2.75,而單位年齡增加則將對數概率降低0.037。
現在我們可以運行anova()模型上的函數來分析偏差表
Analysis of Deviance Table Model: binomial, link: logit Response: Survived Terms added sequentially (first to last) Df Deviance Resid. Df Resid. Dev Pr(>Chi) NULL 799 1065.39 Pclass 1 83.607 798 981.79 < 2.2e-16 *** Sex 1 240.014 797 741.77 < 2.2e-16 *** Age 1 17.495 796 724.28 2.881e-05 *** SibSp 1 10.842 795 713.43 0.000992 *** Parch 1 0.863 794 712.57 0.352873 Fare 1 0.994 793 711.58 0.318717 Embarked 2 2.187 791 709.39 0.334990
零偏差和剩余偏差之間的差異越大越好。通過分析表格,我們可以看到每次添加一個變量時出現偏差的情況。
同樣,增加Pclass,Sex and Age可以顯著減少殘余偏差。
這里的大p值表示沒有變量的模型或多或少地解釋了相同的變化量。最終你想看到的是一個顯著的下降和偏差AIC。
在上面的步驟,我們簡要評價模型的擬合。通過設置參數type='response',R將以P(y = 1 | X)的形式輸出概率。我們的決策邊界將是0.5。如果P(y = 1 | X)> 0.5,則y = 1,否則y = 0。請注意,對于某些應用場景,不同的閾值可能是更好的選擇。
fitting.results < - ifelse(fitted.results> 0.5,1,0) misClasificError < - mean(fitted.results!= test $ Survived
測試集上的0.84精度是相當不錯的結果。但是,如果您希望得到更精確的分數,最好運行交叉驗證,如k折交叉驗證驗證。
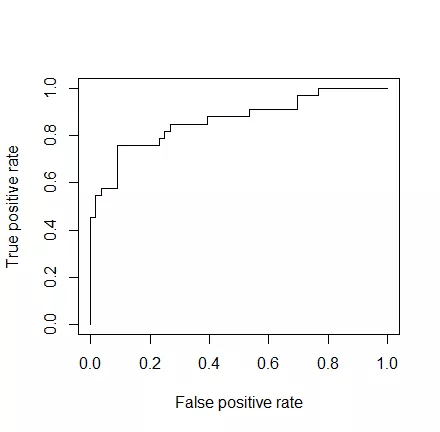
作為最后一步,我們將繪制ROC曲線并計算二元分類器典型性能測量的AUC(曲線下面積)。
ROC是通過在各種閾值設置下將真陽性率(TPR)與假陽性率(FPR)作圖而產生的曲線,而AUC是ROC曲線下的面積。作為一個經驗法則,具有良好預測能力的模型應該接近于1。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“在R語言中如何實現Logistic邏輯回歸的操作”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





