溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
最近由于業務需要進行性能升級,將原來需要經過http進行數據交互的方式修改為消息隊列的形式。于是原來的同步處理的方式變成了異步處理,在一定程度上提升我們系統的性能,不過debug的時候,不免哭了出來。因為每個環節都需要進行詳細檢查。
對于RabbitMQ,我們知道,其是AMQP的一種代理服服務器,具有一套嚴格的通信方式,即在核心產品進行通信的各個方面幾乎都采用了RPC(Remote Procedure Call, 遠程過程調用)模式。
RabbitMQ通信時用到的類和方法與AMQP協議層面的類和方法一一對應。因此AMQP本質上是RPC的一種傳輸機制
AMQ(Advanced Message Queuing)模型,這個模型是針對代理服務器軟件例如(RabbitMQ)設計的,該模型在邏輯上定義了三種抽象組件用于指定消息的路由行為,分別是:
Exchange,消息代理服務器中用于把消息路由到隊列的組件Queue,用來存儲消息的數據結構,位于硬盤或內存中,以FIFO的順序進行投遞Binding,一套規則,用于告訴交換器消息應該被存儲到哪個隊列
在將消息發布到隊列之前,我們需要經歷過以下若干個步驟。至少,必須要設置交換器和隊列,然后將他們綁定再一起。接下來我們將通過python來實現AMQP機制。
我用到了pika這個庫,需要的話,需要通過以下指令安裝。該庫實現了絕大部分rabbitmq的api以及提供了相關的調優參數,后續有機會不妨可以詳談。
pip install pika交換器在AMQ模型中是非常重要的角色存在。因此,在AMQP規范中都有自己的類。聲明一個交換器,我們可以直接在控制臺界面進行創建。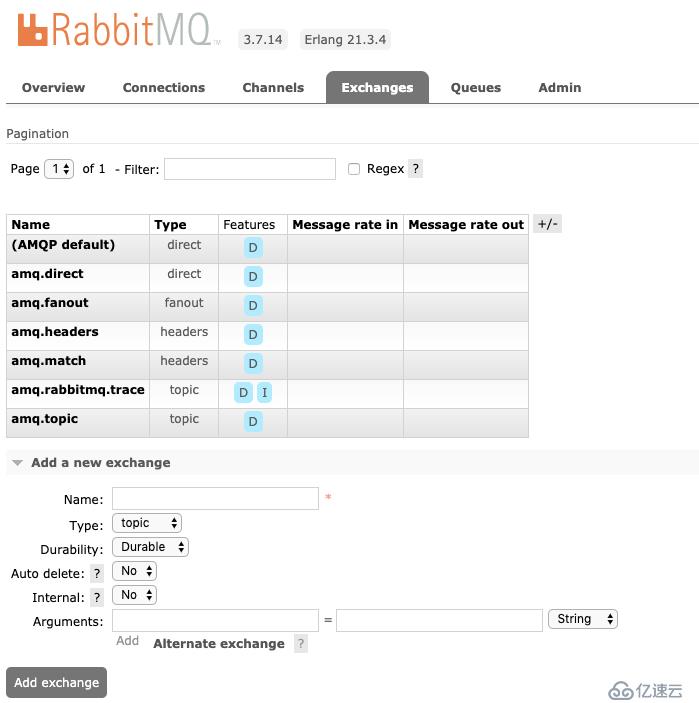
不過這樣僅僅是在極少數的情況下才適合,動手調戲鼠標對開發工程師的來說實在是太蠢啦,能玩鍵盤就別玩鼠標啊,我們不妨通過以下代碼來聲明(創建)一個交換器。pika內置函數會事先通過get的方式來檢查我們待聲明的交換器是否存在,如果存在則不創建,否則創建一個新的交換器。
self.channel.exchange_declare(
exchange=exchange,
exchange_type="direct",
passive=False,
durable=True,
auto_delete=False)一旦交換器創建成功,就可以通過發送類似queue.declare命令讓rabbitmq創建一個隊列。同樣的,我們仍然可以在圖形化界面里面創建隊列。
還是那句話,動手調戲鼠標對開發工程師的來說實在是太蠢啦,能玩鍵盤就別玩鼠標啊,我們不妨通過以下代碼來聲明(創建)若干個隊列。pika內置函數會事先通過get的方式來檢查我們待聲明的隊列是否存在,如果存在則不創建,否則創建一個新的隊列。
self.channel.queue_declare(queue=queue, durable=True)當隊列同名時,即如果我們多次發送同一個queue.declare命令并不會有任何副作用,因為RabbitMQ并不會處理后續的隊列聲明,究其原因,每次創建都會先通過get的方式調用消息隊列引擎查詢隊列是否存在。如果需要返回隊列相關的有用信息,則將會返回隊列中待處理消息的數量以及該隊列的消費者數量。當然了如果隊列同名,而且新隊列的屬性與原有的隊列不一樣,那么RabbitMQ將關閉發出的RPC請求的信道,返回403錯誤
一旦創建了交換器和隊列,之后就可以將它們綁定在一起了,如同queue.declare命令,將隊列綁定到交換器Queue.Bind每次只能指定一個隊列。我們既可以通過圖形化界面進行綁定,也可以通過代碼實現這個效果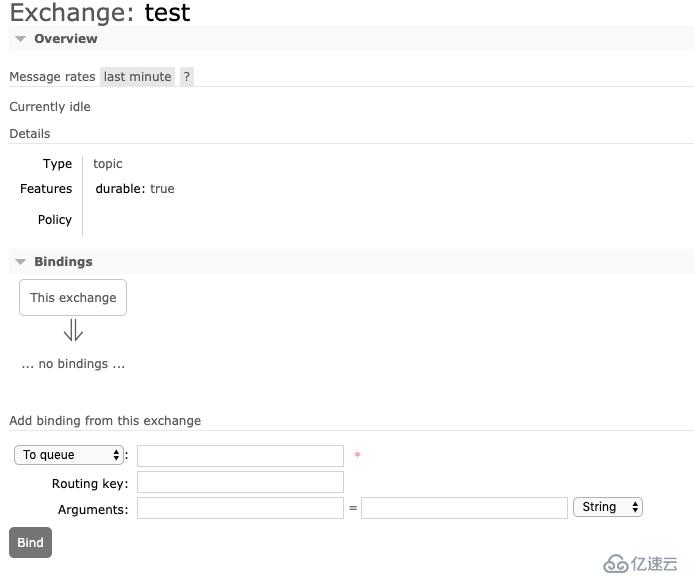
self.channel.queue_bind(
queue=queue, exchange=exchange, routing_key=rk)發布消息到RabbitMQ時,多個幀封裝了發送到服務器的消息數據。在實際的消息內容到達rabbitMQ之前,客戶端應用程序會發送一個basic.publish方法幀、一個內容頭幀和至少一個消息體幀。
默認情況下,只要沒有消費者正在監聽隊列,消息就會被存儲在隊列中。當添加更多消息時,隊列大小也會隨之增加。RabbitMQ可以將這些消息保存在內存或者寫入磁盤。
def produce(self, body):
self.channel.basic_publish(exchange=self.exchange, routing_key=self.route_key, body=body,
properties=pika.BasicProperties(content_type='text/plain', delivery_mode=1)
)一旦發布消息被路由并且保存在一個或者多個隊列中,剩下的就是如何對其進行消費。注意到,發送和消費是異步的。 消費時,可以讓RabbitMQ知道如何消費他們
Basic.Consume命令中
no_ack為true時,RabbitMQ將連續發送消息直到消費者發送一個Basic.Cancel命令或者斷開連接為止
如果為false,則需要發送一個Basic.Ack來確認收到每條消息的請求
def on_message(chan, method_frame, _header_frame, body, userdata=None):
"""Called when a message is received. Log message and ack it."""
# LOGGER.info('Userdata: %s Message body: %s', userdata, body)
# print(" [x] Received %r" % body.decode())
data = body.decode()
result = alarmFun(data)
publish = Publish(exchange='spider', queue='alarm', rk='rk-alarm')
publish.produce(result)
# chan.basic_ack(delivery_tag=method_frame.delivery_tag)
on_message_callback = functools.partial(on_message)
self.channel.basic_consume(on_message_callback=on_message_callback,
queue=self.queue,
auto_ack=True
)經過前面的描述,我們需要理論聯系實踐,讓我們通過python開發消費者角色和發布者角色。
按照配置流程,我們需要初始化連接、配置交換器、隊列、綁定,然后才能通過連接件信息推送(publish)到隊列中。
import logging
from random import randint
import pika
BROKER_USER = os.environ.get('BROKER_USER', 'guest')
BROKER_PASSWD = os.environ.get('BROKER_PASSWD', 'guest')
BROKER_IP = os.environ.get('BROKER_IP', '127.0.0.1')
BROKER_PORT = os.environ.get('BROKER_PORT', '5672')
BROKER_VHOST = os.environ.get('BROKER_VHOST', 'my_vhost')
CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler'
BROKER_URL = 'amqp://{}:{}@{}:{}/{}'.format(BROKER_USER, BROKER_PASSWD, BROKER_IP, BROKER_PORT, BROKER_VHOST)
# logging.basicConfig(level=logging.DEBUG)
# LOG_FORMAT = ('%(levelname) -10s %(asctime)s %(name) -30s %(funcName) '
# '-35s %(lineno) -5d: %(message)s')
# LOGGER = logging.getLogger(__name__)
class Publish(object):
def __init__(self, exchange, queue, rk):
# LOGGER.info('Connecting to %s', BROKER_URL)
# logging.basicConfig(level=logging.DEBUG)
self.credentials = pika.PlainCredentials(BROKER_USER, BROKER_PASSWD)
# 通過這個方式設置備用鏈路,保證connection穩定性
self.parameters = (
pika.ConnectionParameters(BROKER_IP, BROKER_PORT, BROKER_VHOST, self.credentials),
pika.ConnectionParameters(BROKER_IP, BROKER_PORT, BROKER_VHOST, self.credentials, connection_attempts=5,
retry_delay=1))
self.connection = pika.BlockingConnection(self.parameters)
self.channel = self.connection.channel()
self.exchange = exchange
self.channel.exchange_declare(
exchange=exchange,
exchange_type="direct",
passive=False,
durable=True,
auto_delete=False)
self.channel.queue_declare(queue=queue, durable=True)
self.route_key = rk
def produce(self, body):
self.channel.basic_publish(exchange=self.exchange, routing_key=self.route_key, body=body,
properties=pika.BasicProperties(content_type='text/plain', delivery_mode=1)
)
def close(self):
self.connection.close()
def test():
publish = Publish(exchange='test_yerik', queue='test_test', rk='rk-test_test')
for i in range(1, 10000):
publish.produce(randint(1, 100).__str__())
publish.close()
if __name__ == '__main__':
test()消費者的設計和生產者在初始化的時候設計大致相同,都是通過建立連接、開啟channel、exange、queue、bind等過程,主要的區別在于commsum
import functools
import logging
import pika
BROKER_USER = os.environ.get('BROKER_USER', 'guest')
BROKER_PASSWD = os.environ.get('BROKER_PASSWD', 'guest')
BROKER_IP = os.environ.get('BROKER_IP', '127.0.0.1')
BROKER_PORT = os.environ.get('BROKER_PORT', '5672')
BROKER_VHOST = os.environ.get('BROKER_VHOST', 'my_vhost')
CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler'
BROKER_URL = 'amqp://{}:{}@{}:{}/{}'.format(BROKER_USER, BROKER_PASSWD, BROKER_IP, BROKER_PORT, BROKER_VHOST)
# print('pika version: %s' % pika.__version__)
# logging.basicConfig(level=logging.DEBUG)
# LOG_FORMAT = ('%(levelname) -10s %(asctime)s %(name) -30s %(funcName) '
# '-35s %(lineno) -5d: %(message)s')
# LOGGER = logging.getLogger(__name__)
from apps.alarm.alarmfun import alarmFun
from apps.utils.rabbitmq.publish import Publish
class Consummer(object):
def __init__(self, exchange, queue, rk):
# LOGGER.info('Connecting to %s', BROKER_URL)
self.credentials = pika.PlainCredentials(BROKER_USER, BROKER_PASSWD)
self.parameters = (
pika.ConnectionParameters(BROKER_IP, BROKER_PORT, BROKER_VHOST, self.credentials),
pika.ConnectionParameters(BROKER_IP, BROKER_PORT, BROKER_VHOST, self.credentials, connection_attempts=5,
retry_delay=1))
self.connection = pika.BlockingConnection(self.parameters)
self.channel = self.connection.channel()
self.exchange = exchange
self.channel.basic_qos(prefetch_count=1)
self.exchange = exchange
self.queue = queue
self.channel.exchange_declare(
exchange=exchange,
exchange_type="direct",
passive=False,
durable=True,
auto_delete=False)
self.channel.queue_declare(queue=queue, durable=True)
self.channel.queue_bind(
queue=queue, exchange=exchange, routing_key=rk)
self.channel.basic_qos(prefetch_count=1)
def consum_message(self):
# LOGGER.info('Comsummer by {}'.format(name))
def on_message(chan, method_frame, _header_frame, body, userdata=None):
"""Called when a message is received. Log message and ack it."""
# LOGGER.info('Userdata: %s Message body: %s', userdata, body)
# print(" [x] Received %r" % body.decode())
data = body.decode()
result = alarmFun(data)
publish = Publish(exchange='spider', queue='alarm', rk='rk-alarm')
publish.produce(result)
# chan.basic_ack(delivery_tag=method_frame.delivery_tag)
on_message_callback = functools.partial(on_message)
self.channel.basic_consume(on_message_callback=on_message_callback,
queue=self.queue,
auto_ack=True
)
try:
self.channel.start_consuming()
except KeyboardInterrupt:
self.channel.stop_consuming()
def cancel(self):
self.connection.close()
def test():
consummer = Consummer('test_yerik', 'test_test', 'rk-test_test')
consummer.consum_message()
print(consummer.receive)
if __name__ == '__main__':
test()參考文檔:
- 深入RabbitMQ, Gavin M.Roy 著 汪佳南 鄭天民 譯
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





