溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了怎么使用正則匹配最后一個字符串,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
前幾天遇到一個需求,輸入的是
<user> <user> <name>a</name> </user> <user> <name>a</name> </user> </user> <password>123</password>
要求拿到
<user> <user> <name>a</name> </user> <user> <name>a</name> </user> </user>
也就是去掉最后一個</user>后面的字符串。
方法有很多,我首先想到的是用正則匹配去掉</user>后面的字符串。
最后寫出來的表達式是
(?<=</user>)(?![\w\W]*</user>)[\w\W]+。
首先用(?<=</user>)匹配所有前面是</user>的位置,如圖,總共有三個位置。
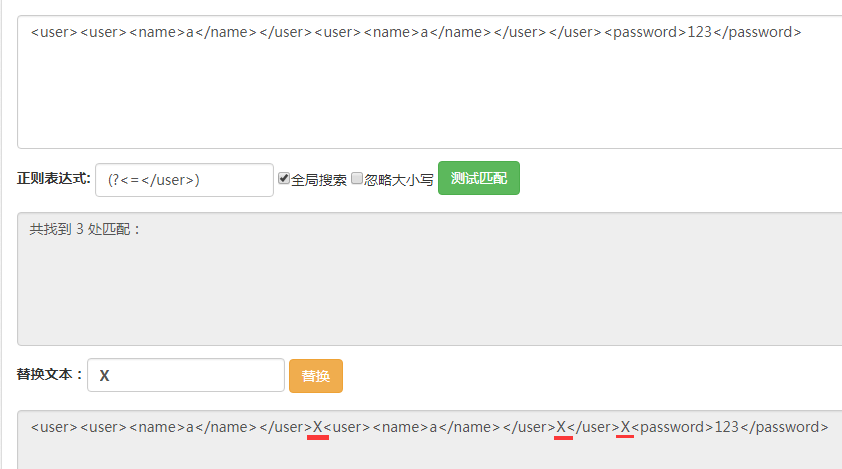
這里我們正則表達式(?<=</user>)的意思就是匹配的位置之前的字符串是</user>,也就是我們匹配到的位置在</user>之后。
這里用到了正則表達式語法中的斷言,有的書上也稱該語法為預查或者環視,都是一樣的用法。有如下語法:(?=pattern) 零寬正向先行斷言 (?!pattern) 零寬負向先行斷言 (?<=pattern) 零寬正向后行斷言 (?<!pattern) 零寬負向后行斷言
這里用到的是(?<=pattern),零寬表示它匹配的是在字符串中的位置,如同^匹配字符串串首,$匹配字符串串尾。正向代表它必須滿足pattern。后行代表它匹配的位置在pattern之后。
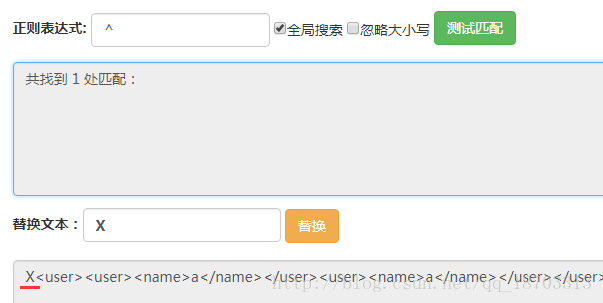
其次,再這三個位置上進行篩選,能夠看出這三個位置的區別是后面是否有</user>,如果沒有的話那么它就是最后一個</user>后面的位置。在之前的表達式后面添上(?![\w\W]*?</user>)此時表達式變為(?<=</user>)(?![\w\W]*?</user>)。
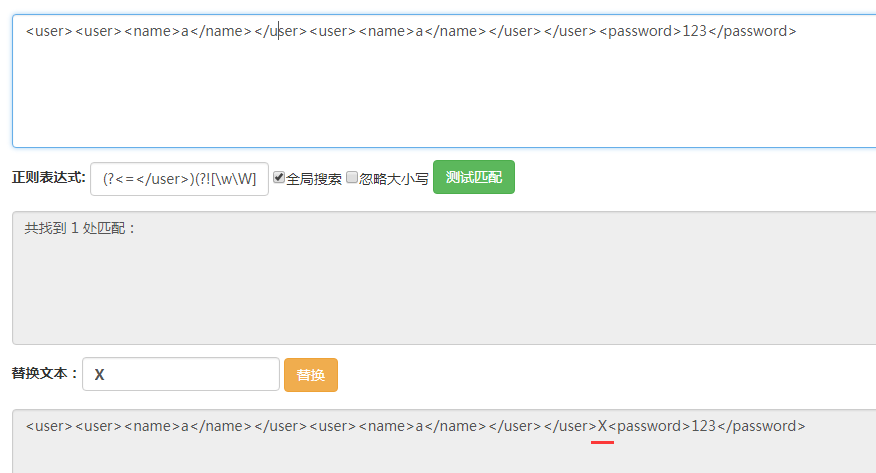
能夠看到得到了最后一個匹配結果。
這里的正則表達式(?!pattern) 是零寬負向先行斷言,也就是它會往后匹配pattern,匹配到的位置在pattern之前,并且匹配到的字符串必須不滿足pattern。
(?![\w\W]*?</user>)的意思是在匹配到的位置后面必須不是[\w\W]*?</user>,\w匹配的是[a-zA-Z0-9_]即匹配字母數字和下劃線,而\W匹配的是[^a-zA-Z0-9_]即不是字母數字也不是下劃線的字符,同時匹配這兩個就相當于匹配任意字符。[\w\W]后面的*代表匹配0-任意多次,后面的?代表懶惰模式,即只要滿足條件就立即返回。
最后,在之前的正則表達式后面加上[\w\W]+貪婪匹配即盡可能多的匹配該位置后面的字符串。最終的正則表達式是(?<=</user>)(?![\w\W]*?</user>)[\w\W]*
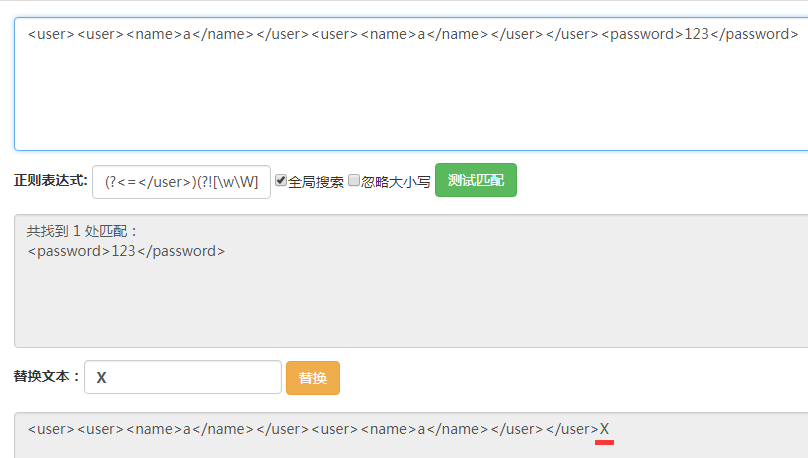
最后的最后用四張圖簡單地描述四種斷言的不同之處。
這里輸入的字符串都是123456。
(?=3),它匹配的位置是后面的字符為3的位置。
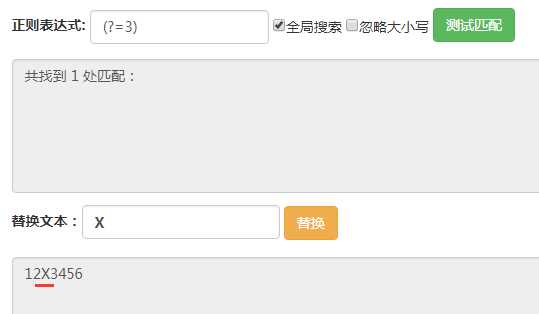
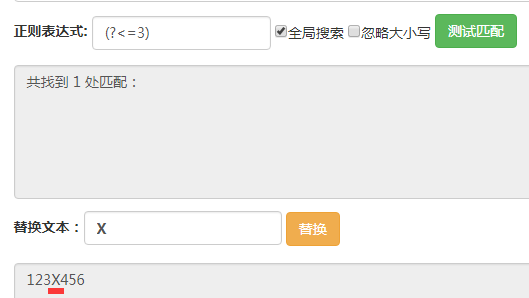
(?<=3),它匹配的位置是前面的字符為3的位置。
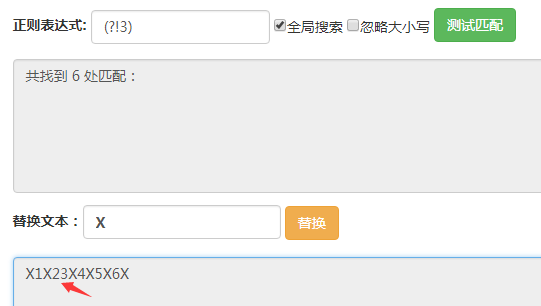
(?!3)匹配的位置是后面的字符不為3的位置,可以看到箭頭所指的地方沒有被匹配到,其他位置都被匹配到了。
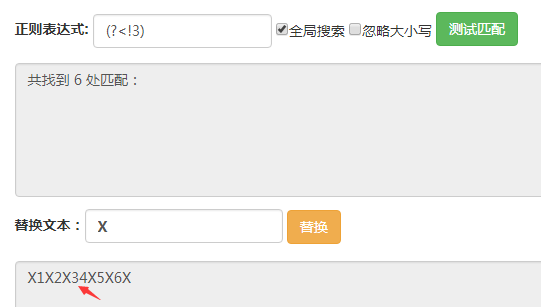
(?<!3)匹配的位置是前面的字符不為3的位置,可以看到箭頭所指的地方沒有被匹配到,其他位置都被匹配到了。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“怎么使用正則匹配最后一個字符串”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





