溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
基于拉丁字母的一套電腦編碼系統,主要用于顯示現代英語和其他西歐語言,最多只能用8位標識,即2**8=256-1,所以最多只能表示255個字符。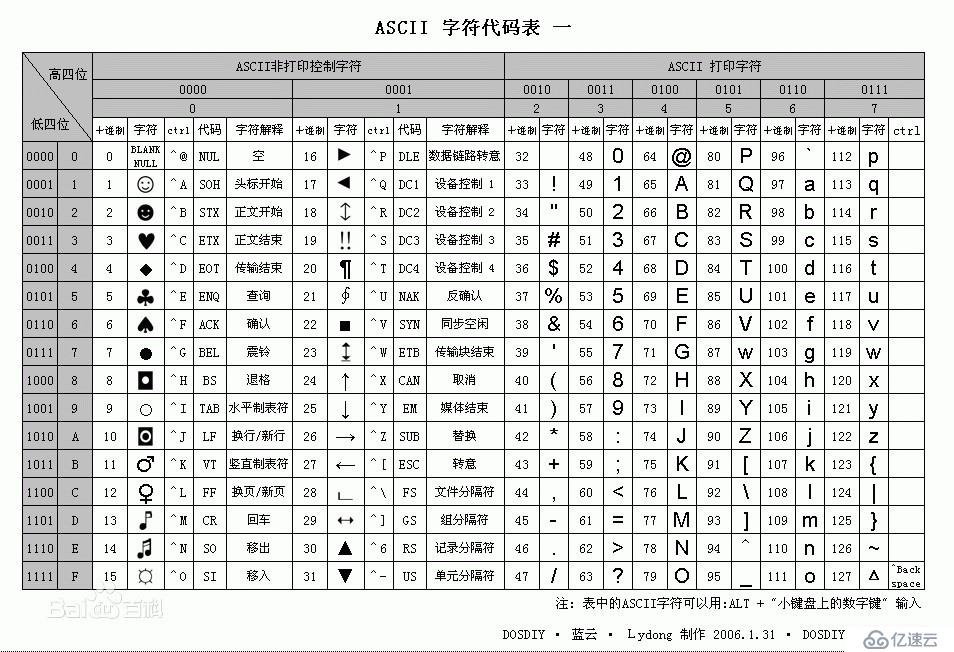
計算機沿用中國,中文顯然遠大于255字符,必須要對中文進行編碼
為處理漢字,程序設計用于簡體中文GB2132和繁體中文big5
GB2312(1980年) 共7445個字符,包括6763個漢字和682個其它符號,
GBK1.0(1995年)收錄了21886個符號,它分為漢字區和圖形符號區。漢字區包括21003個字符
GB18030(2000)取代GBK1.0證實成為國家標準。該標準收錄了27484個漢字,同時還收錄了藏文、蒙文、維吾爾文等主要的少數民族文字。現在的PC平臺必須支持GB18030,對嵌入式產品暫不作要求。所以手機、MP3一般只支持GB2312。
總結:1、從ASCII,GB2312,GBK到GB18030,編碼方法向下兼容。
2、中文版Windows的缺省內碼還是GBK,可以通過GB18030升級包升級到GB18030
顯然ASCII碼無法將世界上的各種文字和符號全部表示,所以,就需要新出一種可以代表所有字符和符號的編碼,即:Unicode。它為每種語言中每個字符設定了統一并且唯一的二進制編碼。最少2個字節,可能更多
對Unicode編碼的壓縮和優化,他不再使用最少使用2個字節,而是將所有的字符和符號進行分類:ascii碼中的內容用1個字節保存、歐洲的字符用2個字節保存,東亞的字符用3個字節保存...
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





