溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了使用python怎么實現逐步回歸,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
逐步回歸是一種線性回歸模型自變量選擇方法;
逐步回歸的基本思想是將變量逐個引入模型,每引入一個解釋變量后都要進行F檢驗,并對已經選入的解釋變量逐個進行t檢驗,當原來引入的解釋變量由于后面解釋變量的引入變得不再顯著時,則將其刪除。以確保每次引入新的變量之前回歸方程中只包含顯著性變量。這是一個反復的過程,直到既沒有顯著的解釋變量選入回歸方程,也沒有不顯著的解釋變量從回歸方程中剔除為止。以保證最后所得到的解釋變量集是最優的。
這里我們選擇赤池信息量(Akaike Information Criterion)來作為自變量選擇的準則,赤池信息量(AIC)達到最小:基于最大似然估計原理的模型選擇準則。
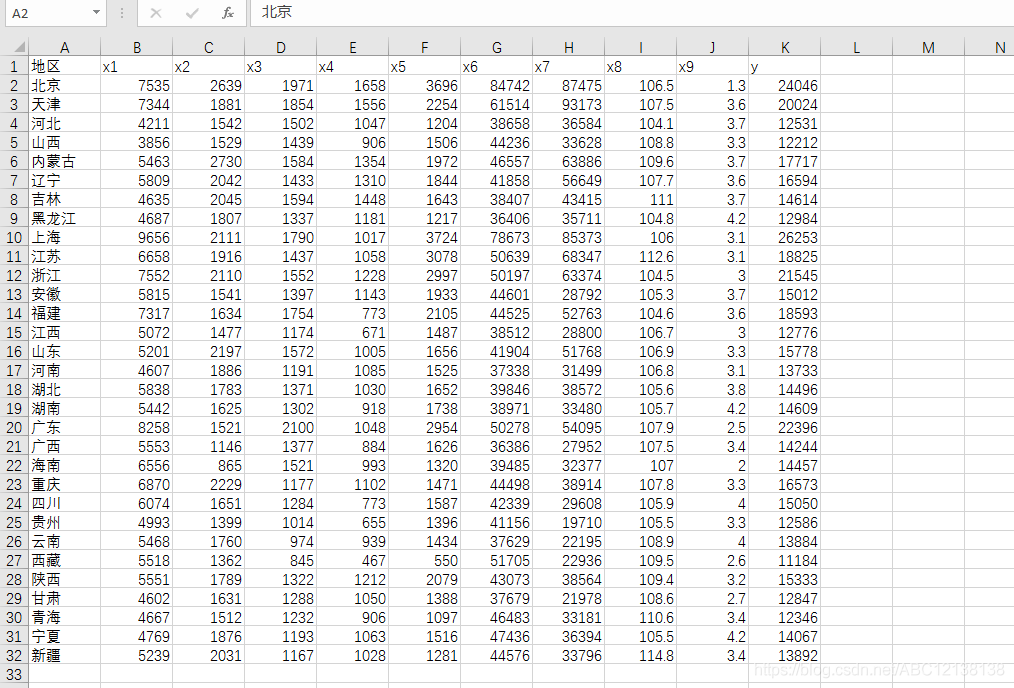
在現實生活中,影響一個地區居民消費的因素有很多,例如一個地區的人均生產總值、收入水平等等,本案例選取了9個解釋變量研究城鎮居民家庭平均每人全年的消費新支出y,解釋變量為:
x1——居民的食品花費
x2——居民的衣著消費
x3——居民的居住花費
x4——居民的醫療保健花費
x5——居民的文教娛樂花費
x6——地區的職工平均工資
x7——地區的人均GDP
x8——地區的消費價格指數
x9——地區的失業率(%)
# -*- coding: UTF-8 -*-
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.stats.api import anova_lm
import matplotlib.pyplot as plt
import pandas as pd
from patsy import dmatrices
import itertools as it
import random
# Load data 讀取數據
df = pd.read_csv('data3.1.csv',encoding='gbk')
print(df)
target = 'y'
variate = set(df.columns) #獲取列名
variate.remove(target) #去除無關列
variate.remove('地區')
#定義多個數組,用來分別用來添加變量,刪除變量
x = []
variate_add = []
variate_del = variate.copy()
# print(variate_del)
y = random.sample(variate,3) #隨機生成一個選模型,3為變量的個數
print(y)
#將隨機生成的三個變量分別輸入到 添加變量和刪除變量的數組
for i in y:
variate_add.append(i)
x.append(i)
variate_del.remove(i)
global aic #設置全局變量 這里選擇AIC值作為指標
formula="{}~{}".format("y","+".join(variate_add)) #將自變量名連接起來
aic=smf.ols(formula=formula,data=df).fit().aic #獲取隨機函數的AIC值,與后面的進行對比
print("隨機化選模型為:{}~{},對應的AIC值為:{}".format("y","+".join(variate_add), aic))
print("\n")
#添加變量
def forwark():
score_add = []
global best_add_score
global best_add_c
print("添加變量")
for c in variate_del:
formula = "{}~{}".format("y", "+".join(variate_add+[c]))
score = smf.ols(formula = formula, data = df).fit().aic
score_add.append((score, c)) #將添加的變量,以及新的AIC值一起存儲在數組中
print('自變量為{},對應的AIC值為:{}'.format("+".join(variate_add+[c]), score))
score_add.sort(reverse=True) #對數組內的數據進行排序,選擇出AIC值最小的
best_add_score, best_add_c = score_add.pop()
print("最小AIC值為:{}".format(best_add_score))
print("\n")
#刪除變量
def back():
score_del = []
global best_del_score
global best_del_c
print("剔除變量")
for i in x:
select = x.copy() #copy一個集合,避免重復修改到原集合
select.remove(i)
formula = "{}~{}".format("y","+".join(select))
score = smf.ols(formula = formula, data = df).fit().aic
print('自變量為{},對應的AIC值為:{}'.format("+".join(select), score))
score_del.append((score, i))
score_del.sort(reverse=True) #排序,方便將最小值輸出
best_del_score, best_del_c = score_del.pop() #將最小的AIC值以及對應剔除的變量分別賦值
print("最小AIC值為:{}".format(best_del_score))
print("\n")
print("剩余變量為:{}".format(variate_del))
forwark()
back()
while variate:
# forwark()
# back()
if(aic < best_add_score < best_del_score or aic < best_del_score < best_add_score):
print("當前回歸方程為最優回歸方程,為{}~{},AIC值為:{}".format("y","+".join(variate_add), aic))
break
elif(best_add_score < best_del_score < aic or best_add_score < aic < best_del_score):
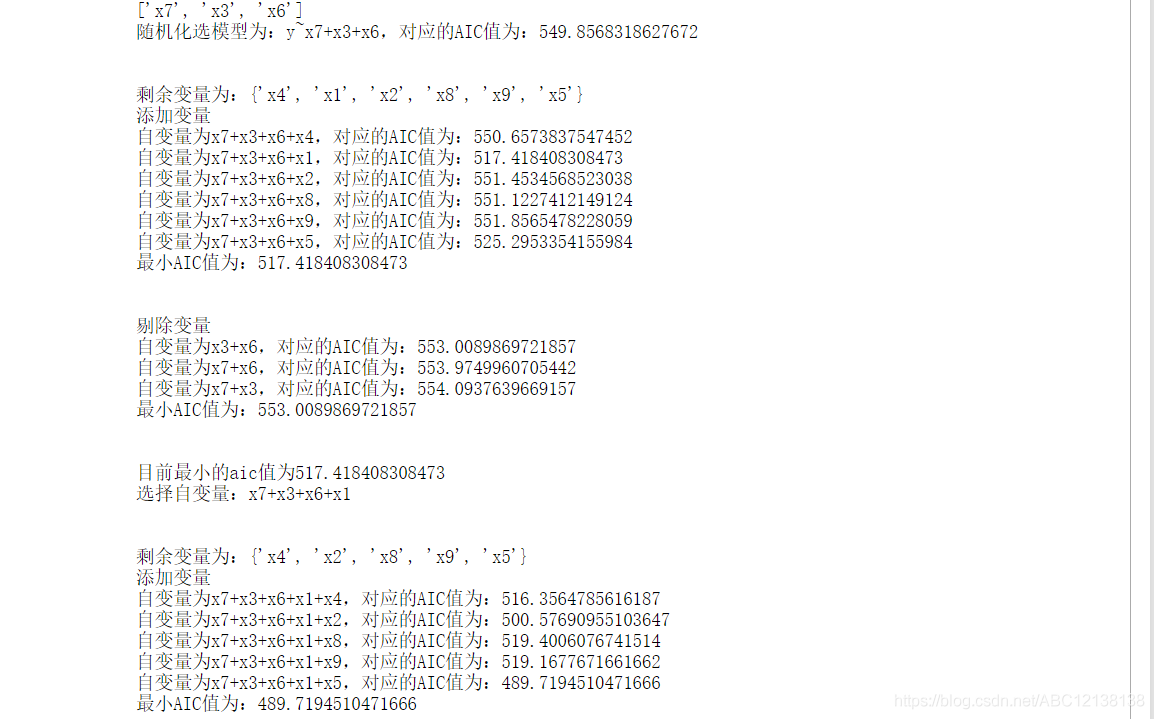
print("目前最小的aic值為{}".format(best_add_score))
print('選擇自變量:{}'.format("+".join(variate_add + [best_add_c])))
print('\n')
variate_del.remove(best_add_c)
variate_add.append(best_add_c)
print("剩余變量為:{}".format(variate_del))
aic = best_add_score
forwark()
else:
print('當前最小AIC值為:{}'.format(best_del_score))
print('需要剔除的變量為:{}'.format(best_del_c))
aic = best_del_score #將AIC值較小的選模型AIC值賦給aic再接著下一輪的對比
x.remove(best_del_c) #在原集合上剔除選模型所對應剔除的變量
back()

上述內容就是使用python怎么實現逐步回歸,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





