溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Python中關聯的規則有哪些,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
大家可能聽說過用于宣傳數據挖掘的一個案例:啤酒和尿布;據說是沃爾瑪超市在分析顧客的購買記錄時,發現許多客戶購買啤酒的同時也會購買嬰兒尿布,于是超市調整了啤酒和尿布的貨架擺放,讓這兩個品類擺放在一起;結果這兩個品類的銷量都有明顯的增長;分析原因是很多剛生小孩的男士在購買的啤酒時,會順手帶一些嬰幼兒用品。
不論這個案例是否是真實的,案例中分析顧客購買記錄的方式就是關聯規則分析法Association Rules。
關聯規則分析也被稱為購物籃分析,用于分析數據集各項之間的關聯關系。
項集:item的集合,如集合{牛奶、麥片、糖}是一個3項集,可以認為是購買記錄里物品的集合。
頻繁項集:顧名思義就是頻繁出現的item項的集合。如何定義頻繁呢?用比例來判定,關聯規則中采用支持度和置信度兩個概念來計算比例值
支持度:共同出現的項在整體項中的比例。以購買記錄為例子,購買記錄100條,如果商品A和B同時出現50條購買記錄(即同時購買A和B的記錄有50),那邊A和B這個2項集的支持度為50%
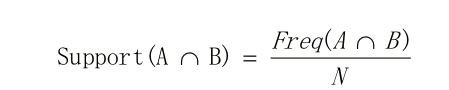
置信度:購買A后再購買B的條件概率,根據貝葉斯公式,可如下表示:
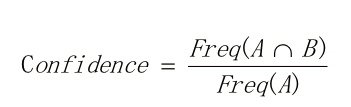
提升度:為了判斷產生規則的實際價值,即使用規則后商品出現的次數是否高于商品單獨出現的評率,提升度和衡量購買X對購買Y的概率的提升作用。如下公式可見,如果X和Y相互獨立那么提升度為1,提升度越大,說明X->Y的關聯性越強
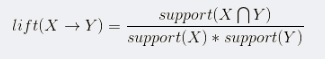
關聯規則方法的步驟如下:
發現頻繁項集
找出關聯規則
Apriori算法是經典的關聯規則算法。Apriori算法的目標是找到最大的K項頻繁集。Apriori算法從尋找1項集開始,通過最小支持度閾值進行剪枝,依次尋找2項集,3項集直到沒有更過項集為止。
下面是一個案例圖解:
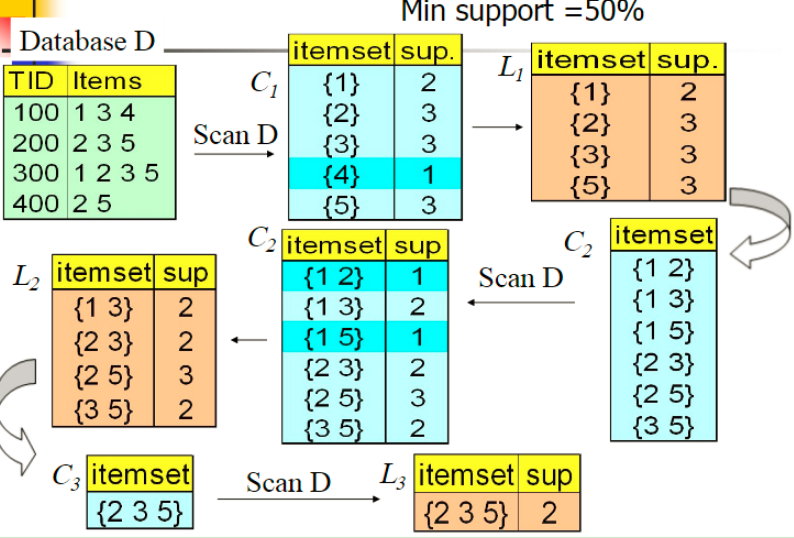
圖中有4個記錄,記錄項有1,2,3,4,5若干
首先先找出1項集對應的支持度(C1),可以看出4的支持度低于最小支持閾值,先剪掉(L1)。
從1項集生成2項集,并計算支持度(C2),可以看出(1,5)(1,2)支持度低于最小支持閾值,先剪掉(L2)
從2項集生成3項集,(1,2,3)(1,2,5)(2,3,5)只有(2,3,5)滿足要求
沒有更多的項集了,就定制迭代
關聯規則目前在scikit-learn中并沒有實現。這里介紹另一個python庫mlxtend。
pip install mlxtend
來看下數據集:
import pandas as pd item_list = [['牛奶','面包'], ['面包','尿布','啤酒','土豆'], ['牛奶','尿布','啤酒','可樂'], ['面包','牛奶','尿布','啤酒'], ['面包','牛奶','尿布','可樂']] item_df = pd.DataFrame(item_list)
數據格式處理,傳入模型的數據需要滿足bool值的格式
from mlxtend.preprocessing import TransactionEncode te = TransactionEncoder() df_tf = te.fit_transform(item_list) df = pd.DataFrame(df_tf,columns=te.columns_)
計算頻繁項集
from mlxtend.frequent_patterns import apriori # use_colnames=True表示使用元素名字,默認的False使用列名代表元素, 設置最小支持度min_support frequent_itemsets = apriori(df, min_support=0.05, use_colnames=True) frequent_itemsets.sort_values(by='support', ascending=False, inplace=True) # 選擇2頻繁項集 print(frequent_itemsets[frequent_itemsets.itemsets.apply(lambda x: len(x)) == 2])

計算關聯規則
from mlxtend.frequent_patterns import association_rules # metric可以有很多的度量選項,返回的表列名都可以作為參數 association_rule = association_rules(frequent_itemsets,metric='confidence',min_threshold=0.9) #關聯規則可以提升度排序 association_rule.sort_values(by='lift',ascending=False,inplace=True) association_rule # 規則是:antecedents->consequents

選擇出來關聯規則之后,根據提升度排序后,可能最高提升度的規則是在我們常識范圍內,那這個規則的價值就不高。所以我們要在產生的規則中根據業務特點進行篩選,像開篇提到(啤酒->尿布)完全不同的品類之間的關聯。
看完上述內容,你們對Python中關聯的規則有哪些有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





