溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我們直接用 Requests、Selenium 等庫寫爬蟲,如果爬取量不是太大,速度要求不高,是完全可以滿足需求的。但是寫多了會發現其內部許多代碼和組件是可以復用的,如果我們把這些組件抽離出來,將各個功能模塊化,就慢慢會形成一個框架雛形,久而久之,爬蟲框架就誕生了。
利用框架我們可以不用再去關心某些功能的具體實現,只需要去關心爬取邏輯即可。有了它們,可以大大簡化代碼量,而且架構也會變得清晰,爬取效率也會高許多。所以如果對爬蟲有一定基礎,上手框架是一種好的選擇。
本書主要介紹的爬蟲框架有PySpider和Scrapy,本節我們來介紹一下 PySpider、Scrapy 以及它們的一些擴展庫的安裝方式。
PySpider 是國人 binux 編寫的強大的網絡爬蟲框架,它帶有強大的 WebUI、腳本編輯器、任務監控器、項目管理器以及結果處理器,同時它支持多種數據庫后端、多種消息隊列,另外它還支持 JavaScript 渲染頁面的爬取,使用起來非常方便,本節介紹一下它的安裝過程。
PySpider 是支持 JavaScript 渲染的,而這個過程是依賴于 PhantomJS 的,所以還需要安裝 PhantomJS,所以在安裝之前請安裝好 PhantomJS,安裝方式在前文有介紹。
推薦使用 Pip 安裝,命令如下:
pip3 install pyspider
Python資源分享qun 784758214 ,內有安裝包,PDF,學習視頻,這里是Python學習者的聚集地,零基礎,進階,都歡迎命令執行完畢即可完成安裝。
Windows 下可能會出現這樣的錯誤提示:Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-vXo1W3/pycurl
這個是 PyCurl 安裝錯誤,一般會出現在 Windows 下,需要安裝 PyCurl 庫,下載鏈接為:http://www.lfd.uci.edu/~gohlk...,找到對應 Python 版本然后下載相應的 Wheel 文件。
如 Windows 64 位,Python3.6 則下載 pycurl?7.43.0?cp36?cp36m?win_amd64.whl,隨后用 Pip 安裝即可,命令如下:
pip3 install pycurl?7.43.0?cp36?cp36m?win_amd64.whlLinux 下如果遇到 PyCurl 的錯誤可以參考本文:https://imlonghao.com/19.html
Mac遇到這種情況,執行下面操作:
brew install openssl
openssl version
查看版本
find /usr/local -name ssl.h
可以看到形如:
usr/local/Cellar/openssl/1.0.2s/include/openssl/ssl.h
添加環境變量
export PYCURL_SSL_LIBRARY=openssl
export LDFLAGS=-L/usr/local/Cellar/openssl/1.0.2s/lib
export CPPFLAGS=-I/usr/local/Cellar/openssl/1.0.2s/include
pip3 install pyspider安裝完成之后,可以直接在命令行下啟動 PySpider:
pyspider all圖 1-75 控制臺
這時 PySpider 的 Web 服務就會在本地 5000 端口運行,直接在瀏覽器打開:http://localhost:5000/ 即可進入 PySpider 的 WebUI 管理頁面,如圖 1-76 所示:
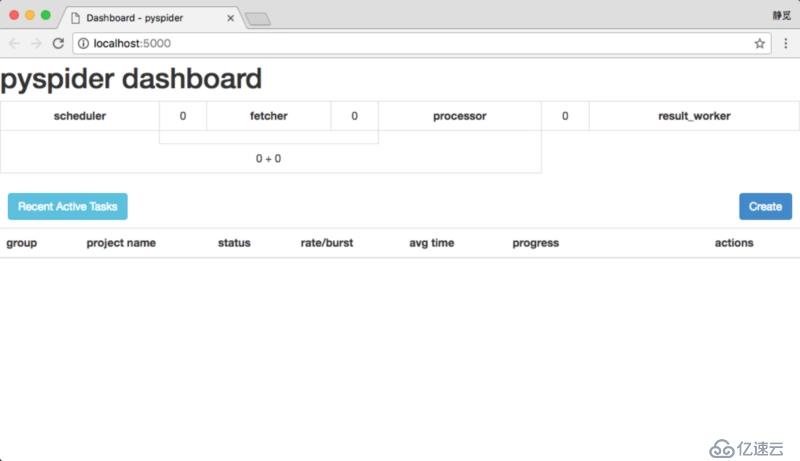
圖 1-76 管理頁面
如果出現類似頁面那證明 PySpider 已經安裝成功了。
在后文會介紹 PySpider 的詳細用法。
這里有一個深坑,PySpider在Python3.7上運行時會報錯
File "/usr/local/lib/python3.7/site-packages/pyspider/run.py", line 231
async=True, get_object=False, no_input=False):
^
SyntaxError: invalid syntax原因是python3.7中async已經變成了關鍵字。因此出現這個錯誤。
修改方式是手動替換一下
下面位置的async改為mark_async
/usr/local/lib/python3.7/site-packages/pyspider/run.py 的231行、245行(兩個)、365行
/usr/local/lib/python3.7/site-packages/pyspider/webui/app.py 的95行
/usr/local/lib/python3.7/site-packages/pyspider/fetcher/tornado_fetcher.py 的81行、89行(兩個)、95行、117行
Scrapy 是一個十分強大的爬蟲框架,依賴的庫比較多,至少需要依賴庫有 Twisted 14.0,lxml 3.4,pyOpenSSL 0.14。而在不同平臺環境又各不相同,所以在安裝之前最好確保把一些基本庫安裝好。本節介紹一下 Scrapy 在不同平臺的安裝方法。
在 Mac 上構建 Scrapy 的依賴庫需要 C 編譯器以及開發頭文件,它一般由 Xcode 提供,運行如下命令安裝即可:
xcode-select --install隨后利用 Pip 安裝 Scrapy 即可,運行如下命令:
pip3 install Scrapy運行完畢之后即可完成 Scrapy 的安裝。
安裝之后,在命令行下輸入 scrapy,如果出現類似下方的結果,就證明 Scrapy 安裝成功,如圖 1-80 所示:
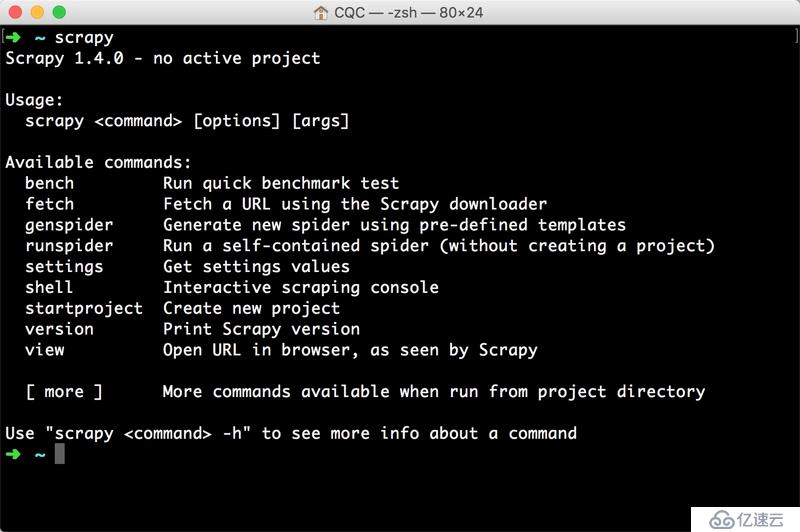
圖 1-80 驗證安裝
pkg_resources.VersionConflict: (six 1.5.2 (/usr/lib/python3/dist-packages), Requirement.parse('six>=1.6.0'))six 包版本過低,six包是一個提供兼容 Python2 和 Python3 的庫,升級 six 包即可:
sudo pip3 install -U sixc/_cffi_backend.c:15:17: fatal error: ffi.h: No such file or directory這是在 Linux 下常出現的錯誤,缺少 Libffi 這個庫。什么是 libffi?“FFI” 的全名是 Foreign Function Interface,通常指的是允許以一種語言編寫的代碼調用另一種語言的代碼。而 Libffi 庫只提供了最底層的、與架構相關的、完整的”FFI”。
安裝相應的庫即可。
Ubuntu、Debian:
sudo apt-get install build-essential libssl-dev libffi-dev python3-devCentOS、RedHat:
sudo yum install gcc libffi-devel python-devel openssl-develCommand "python setup.py egg_info" failed with error code 1 in/tmp/pip-build/cryptography/這是缺少加密的相關組件,利用Pip 安裝即可。
pip3 install cryptographyImportError: No module named 'packaging'缺少 packaging 這個包,它提供了 Python 包的核心功能,利用 Pip 安裝即可。
ImportError: No module named '_cffi_backend'缺少 cffi 包,使用 Pip 安裝即可:
pip3 install cffiImportError: No module named 'pyparsing'
Python資源分享qun 784758214 ,內有安裝包,PDF,學習視頻,這里是Python學習者的聚集地,零基礎,進階,都歡迎缺少 pyparsing 包,使用 Pip 安裝即可:
pip3 install pyparsing appdirs免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





