溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
線程同步,線程間協同,通過某種技術,讓一個線程訪問某些數據時,其他線程不能訪問這個數據,直到該線程完成對數據的操作為止。
臨界區(critical section 所有碰到的都不能使用,等一個使用完成),互斥量(Mutex一個用一個不能用),信號量(semaphore),事件event
event 事件。是線程間通信機制中最簡單的實現,使用一個內部標記的flag,通過flag的True或False的變化來進行操作。
| 名稱 | 含義 |
|---|---|
| set() | 標記設置為True,用于后面wait執行和is_set檢查 |
| clear() | 標記設置為False |
| is_set() | 標記是否為True |
| wait(timeout=None) | 設置等待標記為True的時長,None為無限等待,等到返回為True,未等到了超時返回為False |
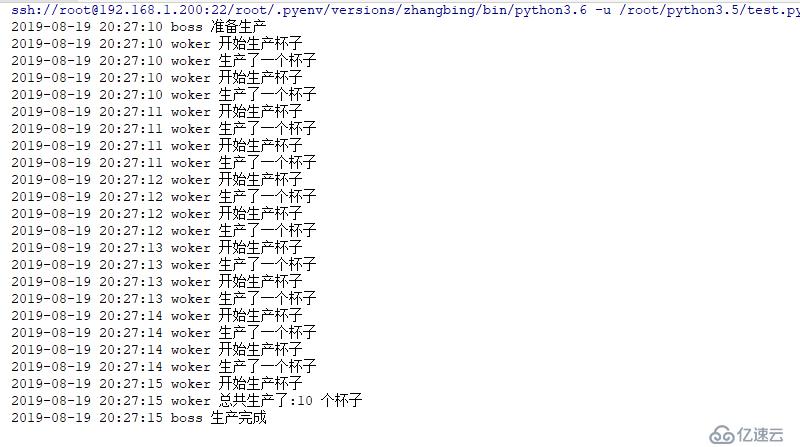
老板雇傭了一個工人,讓他生產杯子,老板一直等著工人。直到生成了10個杯子
import logging
import threading
import time
event=threading.Event()
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
def boss(event:threading.Event):
logging.info("準備生產")
event.wait()
logging.info("生產完成")
def woker(event:threading.Event,count:int=10):
cups=[]
while True:
logging.info("開始生產杯子")
if len(cups) >= count:
event.set()
break
logging.info("生產了一個杯子")
cups.append(1)
time.sleep(0.5)
logging.info("總共生產了:{} 個杯子".format(len(cups)))
b=threading.Thread(target=boss,args=(event,),name='boss')
w=threading.Thread(target=woker,args=(event,10),name='woker')
b.start()
w.start()結果如下
import logging
import threading
import datetime
event=threading.Event()
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
def do(event:threading.Event,interval:int):
while not event.wait(interval): # 此處需要的結果是返回False或True
logging.info('do sth.')
e=threading.Event()
start=datetime.datetime.now()
threading.Thread(target=do,args=(e,3)).start()
e.wait(10)
e.set()
print ("整體運行時間為:{}".format((datetime.datetime.now()-start).total_seconds()))
print ('main exit')結果如下

wait 優于sleep,wait 會主動讓出時間片,其他線程可以被調度,而sleep會占用時間片不讓出。
import logging
import threading
import datetime
import time
event=threading.Event()
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
def add(x:int,y:int):
return x+y
class Timer:
def __init__(self,interval,fn,*args,**kwargs):
self.interval=interval
self.fn=fn
self.args=args
self.kwargs=kwargs
self.event=threading.Event()
def __run(self):
start=datetime.datetime.now()
logging.info('開始啟動步驟')
event.wait(self.interval) #在此處等待此時間后返回為False
if not self.event.is_set(): # 此處返回為False 為正常
self.fn(*self.args,**self.kwargs)
logging.info("函數執行成功,執行時間為{}".format((datetime.datetime.now()-start).total_seconds()))
def start(self):
threading.Thread(target=self.__run()).start()
def cancel(self):
self.event.set()
t=Timer(3,add,10,20)
t.start()結果如下

使用同一個event對象標記flag
誰wait就是等待flag變為True,或者等到超時返回False,不限制等待的個數。
lock: 鎖,凡是在共享資源爭搶的地方都可以使用,從而保證只有一個使用者可以完全使用這個資源。一旦線程獲取到鎖,其他試圖獲取的鎖的線程將被阻塞。
| 名稱 | 含義 |
|---|---|
| acquire(blocking=True,timeout=1) | 默認阻塞,阻塞可以設置超時時間,非阻塞時,timeout禁止設置,成功獲取鎖后,返回True,否則返回False |
| release() | 釋放鎖,可以從任何線程調用釋放。已上鎖的鎖,會被重置為unlocked,未上鎖的鎖上調用,拋出RuntimeError異常 |
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
lock=threading.Lock() # 實例化鎖對象
lock.acquire() # 加鎖處理,默認是阻塞,阻塞時間可以設置,非阻塞時,timeout禁止設置,成功獲取鎖,返回True,否則返回False
print ('get locker 1')
lock.release() # 釋放鎖,可以從任何線程調用釋放,已上鎖的鎖,會被重置為unlocked未上鎖的鎖上調用,拋出RuntimeError異常。
print ('release Locker')
lock.acquire()
print ('get locker 2')
lock.release()
print ('release Locker')
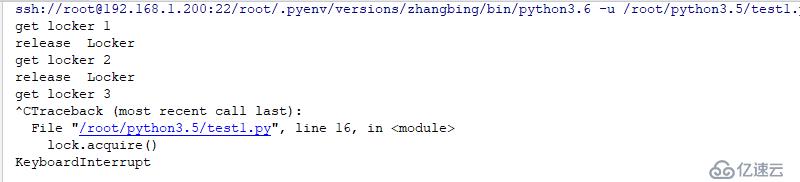
lock.acquire()
print ('get locker 3')
lock.acquire() # 此處未進行相關的釋放操作,因此其下面的代碼將不能被執行,其會一直阻塞
print ('get locker 4')結果如下
#!/usr/bin/poython3.6
#conding:utf-8
import threading
lock=threading.Lock()
lock.acquire()
print ('1')
lock.release()
print ('2')
lock.release() # 此處二次調用釋放,導致的結果是拋出異常。
print ('3')結果如下

鎖釋放后資源一定會出現爭搶情況,鎖一定要支持上下文,否則所有的線程都將等待。
鎖的注意事項是最好不要出現死鎖的情況。
解不開的鎖就是死鎖。
此處是沒有退出的情況的
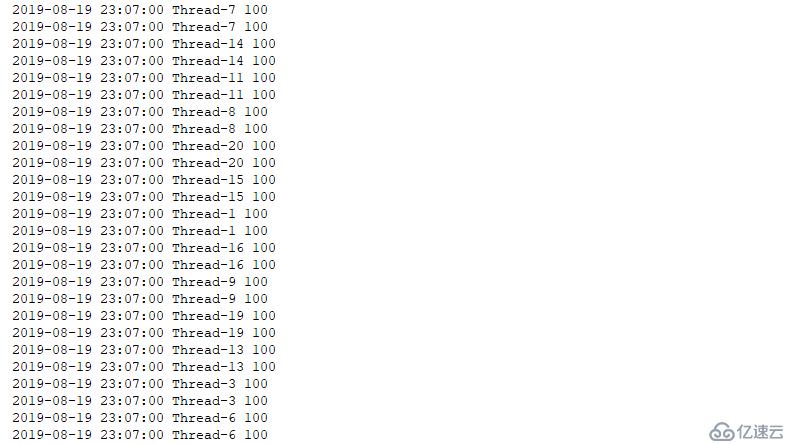
訂單要求生成100個杯子,組織10人生產
不加鎖的情況下
import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
cups=[]
def worker(task=100):
flag=False
while True:
count = len(cups)
logging.info(len(cups))
if count >= task:
flag=True
time.sleep(0.001)
if not flag:
cups.append(1)
if flag:
break
logging.info("共制造{}個容器".format(len(cups)))
for i in range(10): #此處起10個線程,表示10個工人
threading.Thread(target=worker,args=(100,),name="woker-{}".format(i)).start()結果如下
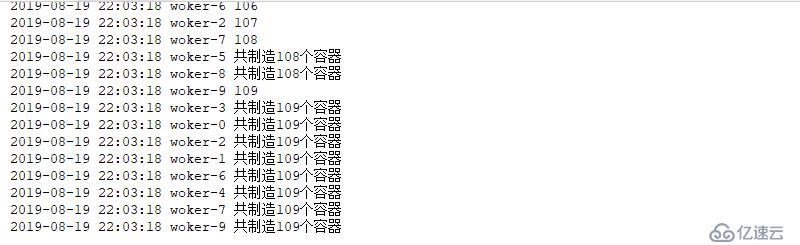
import logging
import threading
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
cups=[]
def worker(task=100):
while True:
count = len(cups)
logging.info(len(cups))
if count >= task:
break
cups.append(1)
logging.info("{}".format(threading.current_thread().name))
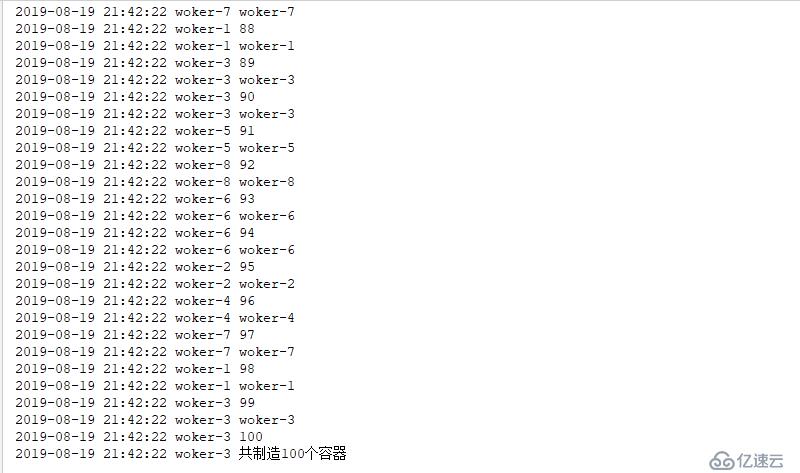
logging.info("共制造{}個容器".format(len(cups)))
for i in range(10): #此處起10個線程,表示10個工人
threading.Thread(target=worker,args=(100,),name="woker-{}".format(i)).start()結果如下

使用上述方式會導致多線程數據同步產生問題,進而導致產生的數據不準確。
import logging
import threading
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
cups=[]
Lock=threading.Lock()
def worker(lock:threading.Lock,task=100):
while True:
lock.acquire()
count = len(cups)
logging.info(len(cups))
if count >= task:
break # 此處保證每個線程執行完成會自動退出,否則會阻塞其他線程的繼續執行
cups.append(1)
lock.release() # 釋放鎖
logging.info("{}".format(threading.current_thread().name))
logging.info("共制造{}個容器".format(len(cups)))
for i in range(10): #此處起10個線程,表示10個工人
threading.Thread(target=worker,args=(Lock,100,),name="woker-{}".format(i)).start()結果如下
import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
def add(self):
self.__x+=1
def sub(self):
self.__x-=1
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此處的100是執行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=1000
c2=10
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value)結果如下

import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
def add(self):
self.__x+=1
def sub(self):
self.__x-=1
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此處的100是執行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=10
c2=10000
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value) #此處可能在未執行完成就進行了打印操作,可能造成延遲問題。結果如下

總結如下:
如果修改線程多少,則效果不明顯,因為其函數執行時長和CPU分配的時間片相差較大,因此在時間片的時間內,足夠完成相關的計算操作,但若是增加執行的循環次數,則可能會導致一個線程在一個時間片內未執行完成相關的計算,進而導致打印結果錯誤。
一般來說加鎖后還有一些代碼實現,在釋放鎖之前還可能拋出一些異常,一旦出現異常,鎖是無法釋放的,但是當前線程可能因為這個異常被終止了,就會產生死鎖,可通過上下文對出現異常的鎖進行關閉操作。
1 使用try...finally語句保證鎖的釋放
2 with上下文管理,鎖對象支持上下文管理源碼如下:
其類中是支持enter和exit的,因此其是可以通過上下文管理來進行相關的鎖關閉操作的。

import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
self.__lock=threading.Lock()
def add(self):
try:
self.__lock.acquire()
self.__x+=1
finally:
self.__lock.release() # 此處不管是否上述異常,此處都會執行
def sub(self):
try:
self.__lock.acquire()
self.__x-=1
finally:
self.__lock.release()
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此處的100是執行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=10
c2=1000
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value)結果如下

import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
self.__lock=threading.Lock()
def add(self):
try:
self.__lock.acquire()
self.__x+=1
finally:
self.__lock.release() # 此處不管是否上述異常,此處都會執行
def sub(self):
try:
self.__lock.acquire()
self.__x-=1
finally:
self.__lock.release()
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此處的100是執行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=100
c2=10
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value)結果如下

import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
self.__lock=threading.Lock()
def add(self):
with self.__lock:
self.__x+=1
def sub(self):
with self.__lock:
self.__x-=1
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此處的100是執行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=100
c2=10
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value)結果如下

通過存活線程數進行判斷
import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
self.__lock=threading.Lock()
def add(self):
with self.__lock:
self.__x+=1
def sub(self):
with self.__lock:
self.__x-=1
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此處的100是執行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=10
c2=1000
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
while True:
time.sleep(1)
if threading.active_count()==1:
print (threading.enumerate())
print (c.value)
break
else:
print (threading.enumerate())結果如下 
不阻塞,timeout沒啥用,False表示不使用鎖
非阻塞鎖能提高效率,但可能導致數據不一致
#!/usr/bin/poython3.6
#conding:utf-8
import threading
lock=threading.Lock()
lock.acquire()
print ('1')
ret=lock.acquire(blocking=False)
print (ret)結果如下

import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
cups=[]
lock=threading.Lock()
def worker(lock:threading.Lock,task=100):
while True:
if lock.acquire(False): # 此處返回為False,則表示未成功獲取到鎖
count=len(cups)
logging.info(count)
if count >=task:
lock.release()
break
cups.append(1)
lock.release()
logging.info("{} make1 ".format(threading.current_thread().name))
logging.info("{}".format(len(cups)))
for x in range(20):
threading.Thread(target=worker,args=(lock,100)).start()結果如下
鎖適用于訪問和修改同一個共享資源的時候,及就是讀取同一個資源的時候。
如果全部都是讀取同一個資源,則不需要鎖,因為讀取不會導致其改變,因此沒必要所用鎖的注意事項:
少用鎖,必要時用鎖,多線程訪問被鎖定的資源時,就成了穿行訪問,要么排隊執行,要么爭搶執行加鎖的時間越短越好,不需要就立即釋放鎖
一定要避免死鎖多線程運行模型(ATM機)
跟鎖無關的盡量排列在后面,和鎖區分開
可重入鎖,是線程相關的鎖,線程A獲得可重入鎖,并可以多次成功獲取,不會阻塞,最后在線程A 中做和acquire次數相同的release即可。
import threading
rlock=threading.RLock() #初始化可重用鎖
rlock.acquire() #進行阻塞處理
print ('1')
rlock.acquire()
print ('2')
rlock.acquire(False) # 此處設置為非阻塞
print ('3')
rlock.release()
print ('4')
rlock.release()
print ('5')
rlock.release()
print ('6')
rlock.release() # 此處表示不能釋放多余的鎖,只能釋放和加入鎖相同次數
print ('7')結果如下
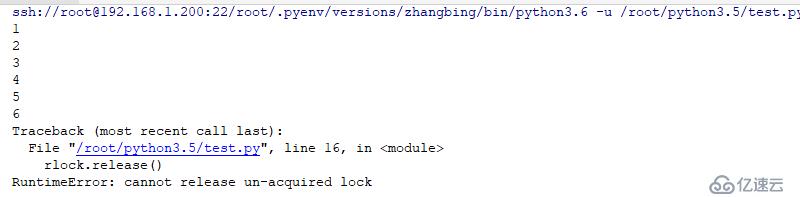
不同線程對Rlock操作的結果
import threading
rlock=threading.RLock() #初始化可重用鎖
def sub(lock:threading.RLock):
lock.release()
ret=rlock.acquire()
print (ret)
ret=rlock.acquire(timeout=5)
print (ret)
ret=rlock.acquire(False)
print (ret)
ret=rlock.acquire(False)
print (ret)
threading.Thread(target=sub,args=(rlock,)).start() # 此處是啟用另一個線程來完成對上述的開啟的鎖的關閉,因為其是基于線程的,
#因此其必須在該線程中進行相關的處理操作,而不是在另外一個線程中進行解鎖操作結果如下
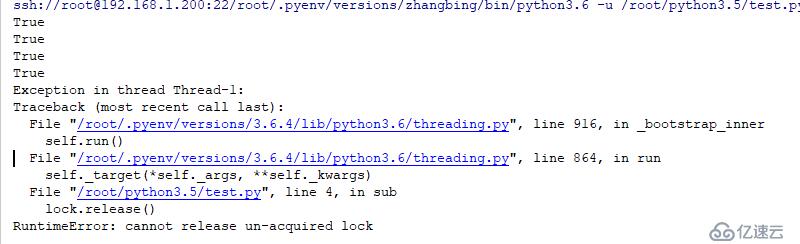
跨線程的Rlock就沒用了,必須使用Lock,Rlock是線程級別的,其他的鎖都是可以在當前進程的另一個線程中進行加鎖和解鎖的。
構造方法condition(lock=None),可傳入一個Lock或Rlock,默認是Rlock。其主要應用于生產者消費者模型,為了解決生產者和消費者速度匹配的問題。
| 名稱 | 含義 |
|---|---|
| acquire(*args) | 獲取鎖 |
| wait(self,timeout=None) | 等待或超時 |
| notify(n=1) | 喚醒至少指定數目個數的等待的線程,沒有等待線程就沒有任何操作 |
| notify_all() | 喚醒所有等待的線程 |
def __init__(self, lock=None):
if lock is None:
lock = RLock() # 此處默認使用的是Rlock
self._lock = lock
# Export the lock's acquire() and release() methods
self.acquire = lock.acquire # 進行相關處理
self.release = lock.release
# If the lock defines _release_save() and/or _acquire_restore(),
# these override the default implementations (which just call
# release() and acquire() on the lock). Ditto for _is_owned().
try:
self._release_save = lock._release_save
except AttributeError:
pass
try:
self._acquire_restore = lock._acquire_restore
except AttributeError:
pass
try:
self._is_owned = lock._is_owned
except AttributeError:
pass
self._waiters = _deque()
def __enter__(self): # 此處定義了上下文管理的內容
return self._lock.__enter__()
def __exit__(self, *args): # 關閉鎖操作
return self._lock.__exit__(*args)
def __repr__(self): # 此處實現了可視化相關的操作
return "<Condition(%s, %d)>" % (self._lock, len(self._waiters))其內部存儲使用了_waiter 進行相關的處理,來對線程進行集中的放置操作。
def wait(self, timeout=None):
if not self._is_owned():
raise RuntimeError("cannot wait on un-acquired lock")
waiter = _allocate_lock()
waiter.acquire()
self._waiters.append(waiter) # 此處使用此方式存儲鎖
saved_state = self._release_save()
gotit = False
try: # restore state no matter what (e.g., KeyboardInterrupt)
if timeout is None:
waiter.acquire()
gotit = True
else:
if timeout > 0:
gotit = waiter.acquire(True, timeout)
else:
gotit = waiter.acquire(False)
return gotit
finally:
self._acquire_restore(saved_state)
if not gotit:
try:
self._waiters.remove(waiter)
except Value喚醒一個release
def notify(self, n=1):
if not self._is_owned(): # 此處是用于判斷是否有鎖
raise RuntimeError("cannot notify on un-acquired lock")
all_waiters = self._waiters
waiters_to_notify = _deque(_islice(all_waiters, n))
if not waiters_to_notify:
return
for waiter in waiters_to_notify:
waiter.release()
try:
all_waiters.remove(waiter)
except ValueError:
pass喚醒所有的所等待
def notify_all(self):
"""Wake up all threads waiting on this condition.
If the calling thread has not acquired the lock when this method
is called, a RuntimeError is raised.
"""
self.notify(len(self._waiters))
notifyAll = notify_allimport threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
def produce(self):# 生產者
for i in range(10):
data=random.randint(1,100)
self.data=data # 產生數據
self.event.wait(1) #此處用于一秒產生一個數據
def custom(self): # 消費者,消費者可能有多個
while True:
logging.info(self.data) # 獲取生產者生產的數據
self.event.wait(0.5) # 此處用于等待0.5s產生一個數據
d=Dispather(0)
p=threading.Thread(target=d.produce,name='produce')
c=threading.Thread(target=d.custom,name='custom')
p.start()
c.start()

此處會使得產生的數據只有一個,而消費者拿到的數據卻有兩份,此處是由消費者來控制其拿出的步驟的。
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
self.conition=threading.Condition()
def produce(self):# 生產者
for i in range(10):
data=random.randint(1,100)
with self.conition: #此處用于先進行上鎖處理,然后最后釋放鎖
self.data=data # 產生數據
self.conition.notify_all() #通知,此處表示有等待線程就通知處理
self.event.wait(1) #此處用于一秒產生一個數據
def custom(self): # 消費者,消費者可能有多個
while True:
with self.conition:
self.conition.wait() # 此處用于等待notify產生的數據
logging.info(self.data) # 獲取生產者生產的數據
self.event.wait(0.5) # 此處用于等待0.5s產生一個數據
d=Dispather(0)
p=threading.Thread(target=d.produce,name='produce')
c=threading.Thread(target=d.custom,name='custom')
p.start()
c.start()
此處是由生產者產生數據,通知給消費者,然后消費者再進行拿取,
有時候可能需要多一點的消費者,來保證生產者無庫存
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
self.conition=threading.Condition()
def produce(self):# 生產者
for i in range(10):
data=random.randint(1,100)
with self.conition: #此處用于先進行上鎖處理,然后最后釋放鎖
self.data=data # 產生數據
self.conition.notify_all() #通知,通知處理產生的數據
self.event.wait(1) #此處用于一秒產生一個數據
def custom(self): # 消費者,消費者可能有多個
while True:
with self.conition:
self.conition.wait() # 此處用于等待notify產生的數據
logging.info(self.data) # 獲取生產者生產的數據
self.event.wait(0.5) # 此處用于等待0.5s產生一個數據
d=Dispather(0)
p=threading.Thread(target=d.produce,name='produce')
c1=threading.Thread(target=d.custom,name='custom-1')
c2=threading.Thread(target=d.custom,name='custom-2')
p.start()
c1.start()
c2.start()結果如下
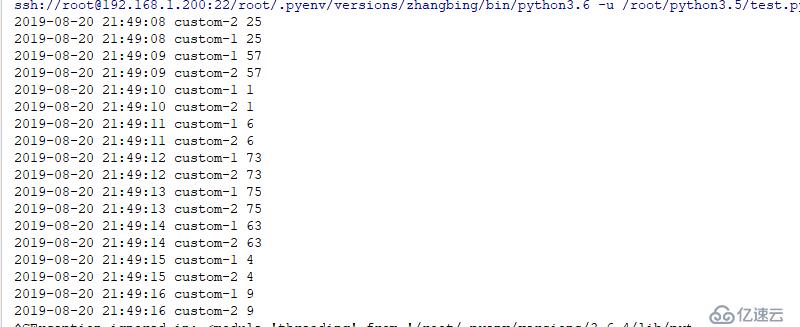
因為此默認是基于線程的鎖,因此其產生另一個消費者并不會影響當前消費者的操作,因此可以拿到兩份生產得到的數據。
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
self.conition=threading.Condition()
def produce(self):# 生產者
for i in range(10):
data=random.randint(1,100)
with self.conition: #此處用于先進行上鎖處理,然后最后釋放鎖
self.data=data # 產生數據
self.conition.notify(2) #通知兩個線程來處理數據
self.event.wait(1) #此處用于一秒產生一個數據
def custom(self): # 消費者,消費者可能有多個
while True:
with self.conition:
self.conition.wait() # 此處用于等待notify產生的數據
logging.info(self.data) # 獲取生產者生產的數據
self.event.wait(0.5) # 此處用于等待0.5s產生一個數據
d=Dispather(0)
p=threading.Thread(target=d.produce,name='produce')
p.start()
for i in range(5): # 此處用于配置5個消費者,
threading.Thread(target=d.custom,name="c-{}".format(i)).start()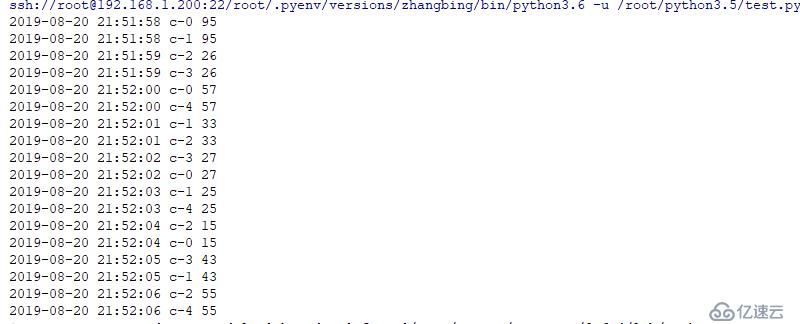
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
self.conition=threading.Condition()
def produce(self):# 生產者
for i in range(10):
data=random.randint(1,100)
with self.conition: #此處用于先進行上鎖處理,然后最后釋放鎖
self.data=data # 產生數據
self.conition.notify(5) #通知全部線程來處理數據
self.event.wait(1) #此處用于一秒產生一個數據
def custom(self): # 消費者,消費者可能有多個
while True:
with self.conition:
self.conition.wait() # 此處用于等待notify產生的數據
logging.info(self.data) # 獲取生產者生產的數據
self.event.wait(0.5) # 此處用于等待0.5s產生一個數據
d=Dispather(0)
p=threading.Thread(target=d.produce,name='produce')
p.start()
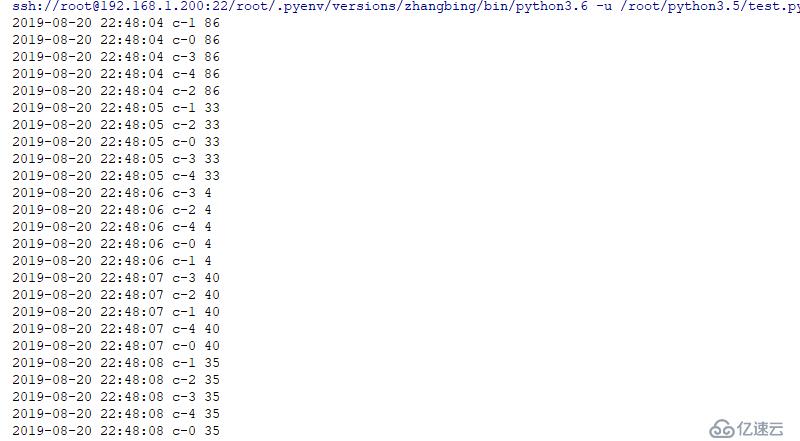
for i in range(5): # 此處用于配置5個消費者,
threading.Thread(target=d.custom,name="c-{}".format(i)).start()結果如下
注: 上述實例中。程序本身不是線程安全的,程序邏輯有很多瑕疵,但是可以很好的幫助理解condition的使用,和生產者消費者模式
輪循太消耗CPU時間了
condition 用于生產者消費者模型中,解決生產者消費者速度匹配的問題
采用了通知機制,非常有效率
使用方式
使用condition,必須先acquire,用完了要release,因為內部使用了鎖,默認是Rlock,最好的方式使用with上下文。消費者wait,等待通知
生產者生產好消息,對消費者發送消息,可以使用notifiy或者notify_all方法。
賽馬模式,并行初始化,多線程并行初始化
有人翻譯為柵欄,有人稱為屏障,可以想象為路障,道閘
python3.2 中引入的新功能
| 名稱 | 含義 |
|---|---|
| Barrier(parties,action=None,timeout=None) | 構建 barrier對象,指定參與方數目,timeout是wait方法未指定超時的默認值 |
| n_waiting | 當前在屏障中等待的線程數 |
| parties | 各方數,需要多少等待 |
| wait(timeout=None) | 等待通過屏障,返回0到線程-1的整數,每個線程返回不同,如果wait方法設置了超時,并超時發送,屏障將處于broken狀態 |
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
def worker(barrier:threading.Barrier):
logging.info("當前等待線程數量為:{}".format(barrier.n_waiting))
# 此處一旦到了第三個線程,則其會直接向下執行,而可能不是需要重新等待第一個等待的線程順序執行
try:
bid=barrier.wait() # 此處只有3個線程都存在的情況下才會直接執行下面的,否則會一直等待
logging.info("after barrier:{}".format(bid))
except threading.BrokenBarrierError:
logging.info("Broken Barrier in {}".format(threading.current_thread().name))
barrier=threading.Barrier(parties=3) # 三個線程釋放一次
for x in range(3): # 此處表示產生3個線程
threading.Event().wait(2)
threading.Thread(target=worker,args=(barrier,),name="c-{}".format(x)).start()結果如下

產生的線程不是等待線程的倍數
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
def worker(barrier:threading.Barrier):
logging.info("當前等待線程數量為:{}".format(barrier.n_waiting))
# 此處一旦到了第三個線程,則其會直接向下執行,而可能不是需要重新等待第一個等待的線程順序執行
try:
bid=barrier.wait() # 此處只有3個線程都存在的情況下才會直接執行下面的,否則會一直等待
logging.info("after barrier:{}".format(bid))
except threading.BrokenBarrierError:
logging.info("Broken Barrier in {}".format(threading.current_thread().name))
barrier=threading.Barrier(parties=3) # 三個線程釋放一次
for x in range(4): # 此處表示產生4個線程,則會有一個一直等待
threading.Event().wait(2)
threading.Thread(target=worker,args=(barrier,),name="c-{}".format(x)).start()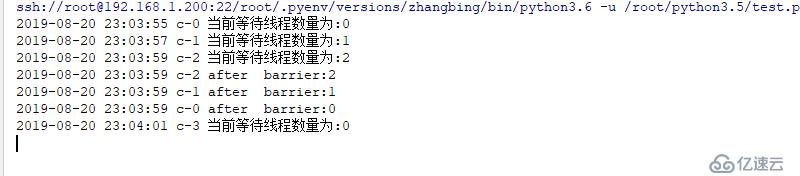
其第4個線程會一直等待下去,直到有3個線程在等待的同時才進行下一步操作。
從運行結果來看,所有線程沖到了barrier前等待,直到parties的數目,屏障將會打開,所有線程停止等待,繼續執行
再有wait,屏障就就緒等待達到參數數目時再放行
| 參數 | 含義 |
|---|---|
| broken | 如果屏障處于打破狀態,則返回True |
| abort() | 將屏障處于broken狀態,等待中的線程或調用等待方法的線程都會拋出BrokenbarrierError異常,直到reset方法來恢復屏障 |
| reset() | 恢復屏障,重新開始攔截 |
import threading
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
def worker(barrier:threading.Barrier):
logging.info("當前等待線程數量為:{}".format(barrier.n_waiting))
# 此處一旦到了第三個線程,則其會直接向下執行,而可能不是需要重新等待第一個等待的線程順序執行
try:
bid=barrier.wait() # 此處只有3個線程都存在的情況下才會直接執行下面的,否則會一直等待
logging.info("after barrier:{}".format(bid))
except threading.BrokenBarrierError:
logging.info("Broken Barrier in {}".format(threading.current_thread().name))
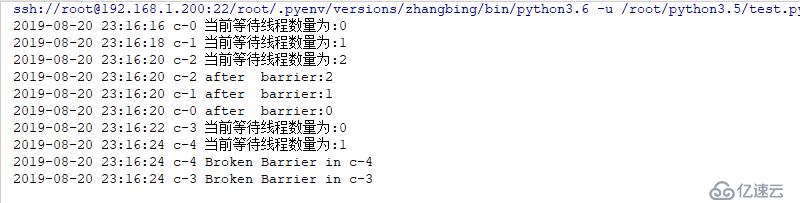
barrier=threading.Barrier(parties=3) # 三個線程釋放一次
for x in range(5): # 此處表示產生5個線程
threading.Event().wait(2)
threading.Thread(target=worker,args=(barrier,),name="c-{}".format(x)).start()
if x==4:
barrier.abort() # 打破屏障,前三個沒問題,后兩個會導致屏障打破一起走出結果如下
import threading
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
def worker(barrier:threading.Barrier):
logging.info("當前等待線程數量為:{}".format(barrier.n_waiting))
# 此處一旦到了第三個線程,則其會直接向下執行,而可能不是需要重新等待第一個等待的線程順序執行
try:
bid=barrier.wait() # 此處只有3個線程都存在的情況下才會直接執行下面的,否則會一直等待
logging.info("after barrier:{}".format(bid))
except threading.BrokenBarrierError:
logging.info("Broken Barrier in {}".format(threading.current_thread().name))
barrier=threading.Barrier(parties=3) # 三個線程釋放一次
for x in range(9): # 此處表示產生5個線程
if x==2: #此處第一個和第二個等到,等到了第三個直接打破,前兩個和第三個一起都是打破輸出
barrier.abort() # 打破屏障,前三個沒問題,后兩個會導致屏障打破一起走出
elif x==6: #x=6表示第7個,直到第6個,到第7個,第8個,第9個,剛好3個直接柵欄退出
barrier.reset()
threading.Event().wait(2)
threading.Thread(target=worker,args=(barrier,)).start()結果如下

并發初始化
所有的線程都必須初始化完成后,才能繼續工作,例如運行加載數據,檢查,如果這些工作沒有完成,就開始運行,則不能正常工作
10個線程做10種不同的工作準備,每個線程負責一種工作,只有這10個線程都完成后,才能繼續工作,先完成的要等待后完成的線程。
如 啟動了一個線程,需要先加載磁盤,緩存預熱,初始化鏈接池等工作,這些工作可以齊頭并進,只不過只有都滿足了,程序才能繼續向后執行,假設數據庫鏈接失敗,則初始化工作就會失敗,就要about,屏蔽broken,所有線程收到異常后直接退出。
和Lock 很像,信號量對象內部維護一個倒計數器,每一次acquire都會減1,當acquire方法發現計數為0時就會阻塞請求的線程,直到其他線程對信號量release后,計數大于0,恢復阻塞的線程。
| 名稱 | 含義 |
|---|---|
| Semaphore(value=1) | 構造方法,value小于0,拋出ValueError異常 |
| acquire(blocking=True,timeout=None) | 獲取信號量,計數器減1,獲取成功返回為True |
| release() | 釋放信號量,計數器加1 |
semaphore 默認值是1,表示只能去一個后就等待著,其相當于初始化一個值。
計數器中的數字永遠不可能低于0
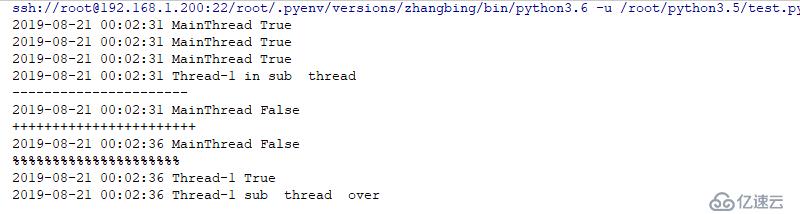
import threading
import logging
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
def woker(sem:threading.Semaphore):
logging.info("in sub thread")
logging.info(sem.acquire())
logging.info("sub thread over")
s=threading.Semaphore(3) # 初始化3個信號量
logging.info(s.acquire()) # 取出三個信號量
logging.info(s.acquire())
logging.info(s.acquire())
threading.Thread(target=woker,args=(s,)).start() # 此處若再想取出,則不能成功,則會阻塞
print ('----------------------')
logging.info(s.acquire(False)) #此處表示不阻塞
print ('+++++++++++++++++++++++')
time.sleep(2)
logging.info(s.acquire(timeout=3)) # 此處表示阻塞超時3秒后釋放
print ('%%%%%%%%%%%%%%%%%%%%%')
s.release() # 此處用于對上述線程中的調用的函數中的內容進行處理結果如下
都是針對同一個對象進行的處理
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Name:
def __init__(self,name):
self.name=name
class Pool:
def __init__(self,count=3):
self.count=count
self.pool=[ Name("conn-{}".format(i)) for i in range(3)] # 初始化鏈接
def get_conn(self):
if len(self.pool)>0:
data=self.pool.pop() # 從尾部拿出來一個
logging.info(data)
else:
return None
def return_conn(self,name:Name): # 此處添加一個
self.pool.append(name)
pool=Pool(3)
pool.get_conn()
pool.get_conn()
pool.get_conn()
pool.return_conn(Name('aaa'))
pool.get_conn()結果如下

import logging
import threading
import random
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Name:
def __init__(self,name):
self.name=name
class Pool:
def __init__(self,count=3):
self.count=count
self.sem=threading.Semaphore(count)
self.event=threading.Event()
self.pool=[ Name("conn-{}".format(i)) for i in range(count)]
def get_conn(self):
self.sem.acquire()
data=self.pool.pop()
return data
def return_conn(self,name:Name): # 此處添加一個
self.pool.append(name)
self.sem.release()
def woker(pool:Pool):
conn=pool.get_conn()
logging.info(conn)
threading.Event().wait(random.randint(1,4))
pool.return_conn(conn)
pool=Pool(3)
for i in range(8):
threading.Thread(target=woker,name="worker-{}".format(i),args=(pool,)).start()結果如下

上述實例中,使用信號量解決資源有限的問題,如果池中有資源,請求者獲取資源時信號量減1,請求者只能等待,當使用者完全歸資源后信號量加1,等待線程就可以喚醒拿走資源。
有界信號量,不允許使用release超出初始值范圍,否則,拋出ValueError異常,這個用有界信號修改源代碼,保證如果多return_conn 就會拋出異常,保證了歸還鏈接拋出異常。
信號量一直release會一直向上加,其會將信號量和鏈接池都擴容了此處便產生了BoundedSemaphore
import logging
import threading
import random
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
s=threading.BoundedSemaphore(3) # 邊界
s.acquire() # 此處需要拿取,否則不能直接向其中加
print (1)
s.release()
print (2)
s.release()
print (3)結果如下

應用如下
import logging
import threading
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
class Conn:
def __init__(self,name):
self.name=name
class Pool:
def __init__(self,count=3):
self.count=count # 初始化鏈接池
self.sema=threading.BoundedSemaphore(count)
self.pool=[Conn("conn-{}".format(i)) for i in range(count)] # 初始化鏈接
def get_conn(self):
self.sema.acquire() # 當拿取的時候,減一
data=self.pool.pop() # 從尾部拿出一個
print (data)
def return_conn(self,conn:Conn): #此處返回一個連接池
self.pool.append(conn) # 必須保證其在拿的時候有 # 使用try 可以進行處理,下面的必須執行,加成功了,下面的一定要成功的,
self.sema.release()
pool=Pool(3)
con=Conn('a')
conn=pool.get_conn()
conn=pool.get_conn()
conn=pool.get_conn()結果如下

如果使用了信號量,還是沒有用完
self.pool.append(conn)
self.sem.release()
一種極端的情況下,計數器還差1就滿了,有3個線程A,B,C都執行了第一句,都沒有來得release,這時候輪到線程A release,正常的release,然后輪到線程C先release,一定出現問題,超界了,一定出現問題。
很多線程用完了信號量
沒有獲取信號量的線程都會阻塞,沒有線程和歸還的線程爭搶,當append后才release,這時候才能等待的線程被喚醒,才能Pop,也就是沒有獲取信號量就不能pop,這是安全的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





