溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何優化Shell腳本效率,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
一、先說一下Shell腳本語言自身的局限性
作為解釋型的腳本語言,天生就有效率上邊的缺陷。盡管它調用的其他命令可能效率上是不錯的。
Shell腳本程序的執行是順序執行,而非并行執行的。這很大程度上浪費了可能能利用上的系統資源。
Shell每執行一個命令就創建一個新的進程,如果腳本編寫者沒有這方面意識,編寫腳本不當的話,是非常浪費系統資源的。
二、我們在Shell腳本語言的局限性上盡可能的通過我們有經驗的編碼來提高腳本的效率。
1、比如我想做一個循環處理數據,可能是簡單的處理一下數據,這樣會讓人比較容易就想到Shell里的循環類似這樣:
代碼如下:
sum=0
for((i=0;i<100000;i++))
do
sum=$(($sum+$i))
done
echo $sum
我們可以使用time這個腳本來測試一下十萬次循環的三次執行耗時:
real 0m2.115s
user 0m1.975s
sys 0m0.138s
real 0m2.493s
user 0m2.173s
sys 0m0.254s
real 0m2.085s
user 0m1.886s
sys 0m0.195s
平均耗時2.2s,如果你知道awk命令里的循環的話,那更好了,我們來測試一下同數據規模的循環三次執行耗時:
代碼如下:
awk 'BEGIN{
sum=0;
for(i=0;i<100000;i++)
sum=sum+i;
print sum;
}'
real 0m0.023s
user 0m0.018s
sys 0m0.005s
real 0m0.020s
user 0m0.018s
sys 0m0.002s
real 0m0.021s
user 0m0.019s
sys 0m0.003s
你都不敢想象平均時間僅0.022s,基本上純循環的效率已經比Shell高出兩位數量級了。事實上你再跑百萬次的循環你會發現Shell已經比較吃力了,千萬級的更是艱難。所以你應該注意你的程序盡量使用awk來做循環操作。
2、關于正則,經常寫Shell的同學都明白它的重要性,但是你真的能高效使用它嗎?
下邊舉個例子:現在我有一個1694617行的日志文件 action.log,它的內容類似:
2012_02_07 00:00:04 1977575701 183.10.69.47 login 500004 1977575701 old /***/port/***.php?…
我現在想獲取//之間的port的字符串,我可以這樣:
awk -F'/' ‘{print $3}' < 7action.log > /dev/null
但是你不會想知道它的效率:
real 0m12.296s
user 0m12.033s
sys 0m0.262s
相信我,我不會再想看著光標閃12秒的。但是如果這樣執行:
awk ‘{print $9}' < 7action.log | awk -F'/' '{print $3}' > /dev/null
這句的效率三次分別是:
real 0m3.691s
user 0m5.219s
sys 0m0.630s
real 0m3.660s
user 0m5.169s
sys 0m0.618s
real 0m3.660s
user 0m5.150s
sys 0m0.612s
平均時間大概3.6秒,這前后效率大概有4倍的差距,雖然不像上一個有百倍的差距,但是也足夠讓4小時變成1小時了。我想你懂這個差距的。
其實這個正則實例你可以嘗試推測其他的情況,因為正則每次運行都是需要啟動字符串匹配的,而且默認的分隔符會較快的按字段區分出。所以我們在知道一些數據規律之后可以嘗試大幅度的縮短我們將要進行復雜正則匹配的字符串,這樣會根據你縮減數據規模有一個非常明顯的效率提升,上邊還是驗證的比較簡單的正則匹配情況,只有一個單字符“\”,你可以試想如果正則表達式是這樣:
$7!~/\.jpg$/&&$7~/\.[s]?html|\.php|\.xml|\/$/&&($9==200||$9==304)&&$1!~/^103\.108|^224\.215|^127\.0|^122\.110\.5/
我想你可以想象的出一個目標匹配字符串從500個字符縮減到50個字符的時候的巨大意義!
ps:另外詳細的正則優化請看這個日期之后發的一篇博文。
3、再說一下shell的重定向和管道。這個條目我不會再舉例子,只是說一下我個人的理解。
周所周知,很多程序或者語言都有一個比較突出的效率瓶頸就是IO,Shell也不例外(個人這么考慮)。所以建議盡可能的少用重定向來進行輸入輸出這樣的操作或者創建臨時文件來供后續使用,當然,如果必須這么干的時候那就這么干吧,我只是講一個盡量的過程。
我們可以用Shell提供的管道來實現命令間數據的傳遞。如果進行連續的對數據進行過濾性命令的時候,盡量把一次性過濾較多的命令放在前邊,這個原因都懂吧?減少數據傳遞規模。
最后我想說的連管道也盡量的少用的,雖然管道比正常的同定向IO快幾個數量級的樣子,但是那也是需要消耗額外的資源的,好好設計你的代碼來減少這個開銷吧。比如sort | uniq 命令,完全可以使用 sort -u 來實現。
4、再說一下Shell腳本程序的順序執行。這塊的優化取決于你的系統負載是否達到了極限,如果你的系統連命令的順序執行負載都到了一個較高的線的話,你就沒有必要進行Shell腳本程序的并行改造了。下邊給出一個例子,如果你要模仿這個優化,請保證你的系統還能有負載空間。比如現在有這樣一個程序:
supportdatacommand1
supportdatacommand2
supportdatacommand3
supportdatacommand4
supportdatacommand5
supportdatacommand6
need13datacommand
need24datacommand
need56datacommand
大意就是有6個提供數據的命令在前邊,后面有3個需要數據的命令,第一個需要數據的命令需要數據13,第二個需要24,第三個需要56。但是正常情況下Shell會順序的執行這些命令,從supportdatacommand1,一條一條執行到need56datacommand。這樣的過程你看著是不是也很蛋疼?明明可以更好的做這一塊的,蛋疼的程序可以這樣改造:
代碼如下:
supportdatacommand1 &
supportdatacommand2 &
supportdatacommand3 &
supportdatacommand4 &
supportdatacommand5 &
supportdatacommand6 &
#2012-02-22 ps:這里的循環判斷后臺命令是否執行完畢是有問題的,pidnum循#環減到最后也還是1不會得到0值,具體解決辦法看附錄,因為還有解釋,就不在這#里添加和修改了。
while true
do
sleep 10s
pidnum=`jobs -p | wc -l`
if [ $pidnum -le 0 ]
then
echo "run over"
break
fi
done
need13datacommand &
need24datacommand &
need56datacommand &
wait
...
可以類似上邊的改造。這樣改造之后蛋疼之感就紓解的多了。但還是感覺不是很暢快,那好吧,我們可以再暢快一點(我是指程序。。。),可以類似這樣:
代碼如下:
for((i=0;i<1;i++));do
{
command1
command2
}&
done
for((i=0;i<1;i++));do
{
command3&
command4&
}&
done
for((i=0;i<1;i++));do
{
command5 &
command6 &
if 5 6執行完畢...
command7
}&
done
這樣類似這樣的改造,讓有前后關系的命令放在一個for循環里讓他們一起執行去,這樣三個for循環其實是并行執行了。然后for循環內部的命令你還可以類似改造1的那種方式改造或者內嵌改造2這個的并行for循環,都是可以的,關鍵看你想象力了。恩?哦,不對,關鍵是看這些個命令之間是一種什么樣的基友關系了。有關聯的放一個屋里就行了,剩下的你就不用操心了。嘿嘿~~
其實這個優化真的需要看系統負載。
5、關于對shell命令的理解。這個條目就靠經驗了,因為貌似沒有相關的書籍可看,如果誰知道有,請推薦給我,我會灰常感謝的啊。
比如:sed -n '45,50p' 和 sed -n '51q;45,50p' ,前者也是讀取45到50行,后者也是,但是后者到51行就執行了退出sed命令,避免了后續的操作讀取。如果這個目標文件的規模巨大的話,剩下的你懂的。
還有類似sed ‘s/foo/bar/g' 和sed ‘/foo/ s/foo/bar/g'
sed支持采用正則進行匹配和替換,考慮字符串替換的需求中,不防加上地址以提高速度。實例中通過增加一個判斷邏輯,采用“事先匹配”代替“直接替換”,由于sed會保留前一次的正則匹配環境,不會產生冗余的正則匹配,因此后者具有更高的效率。關于sed命令的這兩點優化,我也在sed命令詳解里有提到。
還有類似sort 如果數字盡量用 -n選項;還有統計文件行數,如果每行的數據在占用字節數一樣的情況時就可以ls查文件大小然后除以每行的數據大小的出行數,而避免直接使用wc -l這樣的命令;還有find出來的數據,別直接就-exec選項了,如果數據規模小很好,但是如果你find出來上千條數據或更多,你會瘋掉的,不,系統會瘋掉的,因為每行數據都會產生新的進程,你可以這樣find …. | xargs ….;還有…(如果你也知道類似的提效率情況請你告訴我共同進步!)
三、關于優化更好的一些選擇
一個比較好的提升Shell腳本的效率方法就是…… 就是…… 就是…… 好吧,就是盡量少用Shell(別打我啊!!!)下邊給出一些debian官方統計的一些在linux系統上邊的各個語言的效率圖,咱都以C++為比較基準(系統規格:x64 Ubuntu? Intel® Q6600® quad-core):
這些圖的查看方法,比如第一個圖java和c++的程序效率比較圖,總共分三個部分,分別是time、memory、code的比較,如果是c++/java ,就是說 c++做比較的分子,java做比較的分母,如果圖上的長條在哪邊,說明所在的那邊的程序使用的時間或者內存或者代碼較多,具體多多少就看長條長了多少。每一部分有多個長條圖形,每個長條圖案表示針對程序處理不同方面的任務時進行的測試。比如第一幅,c++和java在該環境下大部分情況下time上是差不多的,甚至java-server還有稍微的優勢,內存方面c++就有很大優勢,能夠使用比java少的多的內容做相同的事情,但是編碼量c++就稍微多一點點。以下的圖類似。 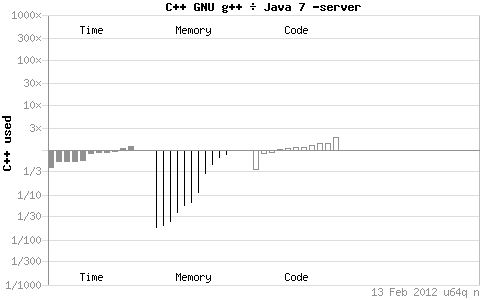

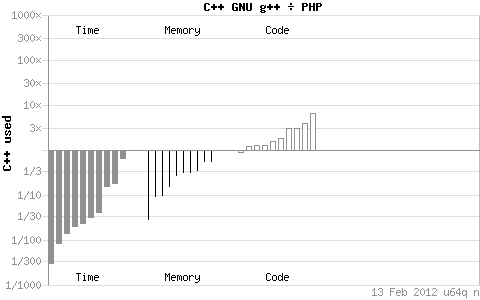

通過上邊的圖我看可以知道C++在時間和空間上對Python、Perl、PHP有著絕對壓倒性的優勢,但是相對的編碼量較高。同java比只有內存使用上的優勢。但是我們這篇主要是針對Shell的,但是,又是但是,debian官網沒有把shell腳本納入效率比較的統計范圍啊!!!還是但是,我們知道Python、Perl、PHP都是號稱對Shell在效率方面有著明顯的優勢,所以你如果不滿意你通過以上提供的種種優化途徑后的Shell腳本程序的話,那你就可以嘗試換一種語言了。
但是我們往往不那么容易舍棄這么好用方便而且簡單的處理數據方式,也可以有個折中的方法,你先用time測試各個Shell腳本命令的耗時,針對特別耗時,特別讓人不能忍受的命令的效率使用C++程序處理,讓你的Shell腳本來調用這個針對局部數據處理的C++程序,這樣折中貌似還是能讓人接受吧?
四、最后說一下這篇是不敢稱為全面或者詳解的文章,是我對這一段Shell學習和實踐的一些心得,希望能有高手指點。也希望能幫到新踏入這一領域的新同學。以后有新的心得再添加吧。
感謝這篇文章的作者的博文指點。
2012-02-22 ps:循環檢測后臺命令是否結束的判斷修改:
解決方法暫時有兩個(具體沒有解釋,不太清楚原因):
1、
代碼如下:
sleep 8 &
sleep 16 &
while true
do
echo `jobs -p | wc -l`
jobs -l >> res
sleep 4
done
2、 檢查剩余個數的語句改成 jobs -l |grep -v “Done”|wc -l
第一個方案的解決是多執行一次jobs,可以解釋成為了消除最后的Done結果,但是這種解釋也是行不通的,因為循環是一直執行的,在echo里已經執行很多次jobs了,何止一次。
第二個方案是過濾掉jobs最后的輸出結果Done這條語句。算是繞過問題得到了期待的結果。
個人感覺bash解釋器優化掉了沒有后臺命令執行的jobs查詢命令,如果是優化掉了那也應該有個空的返回,wc依然可以得到0的結果啊。所以這個問題找不到具體原因,如果你知道請告訴我,非常感謝。。。 這里先感謝just do shell群里的Eric 沉默的土匪 GS 三人,非常感謝你們的幫助。
這里兩個方法不算好方法,只是奇怪這樣為什么不行,行的又該如何解釋。后來知道用wait命令就全解決了,耽誤那么多時間還是用的不明智的方法。
關于“如何優化Shell腳本效率”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





