溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關數據庫中跨庫數據表運算的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
1. 簡單合并(FROM)
所謂跨庫數據表,是指邏輯上同一張數據表被分別存儲在不同數據庫中。其原因有可能是因為數據量太大,放在一個數據庫難以處理,也可能在業務上就需要將生產庫和歷史庫分開。而不同的數據庫,可能只是部署在不同的機器上的同種數據庫,也可能是連類型都不同的數據庫系統。
在面對跨庫數據表,特別是數據庫類型都不相同的情況時,數據庫自帶的工具往往就力所不及了,一般都需要尋找能夠很好地支持多數據源類型的第三方工具,而集算器,可以說是其中的佼佼者了。下面,我們就針對幾種常見的跨庫混合運算情況詳細討論一下:
跨庫運算,簡單粗暴的思路就是把散布在各個庫里的邏輯上相同的數據表合并成一個表,然后在這一個表上進行運算。
例如,在兩個數據庫 HSQL 和 MYSQL 中,分別存儲了一張學生成績表,兩者各自保存了一部分學生信息,如下圖所示:
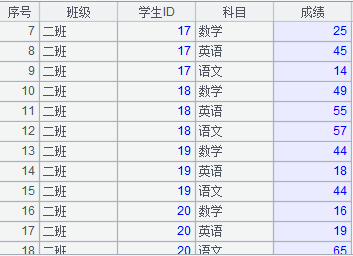
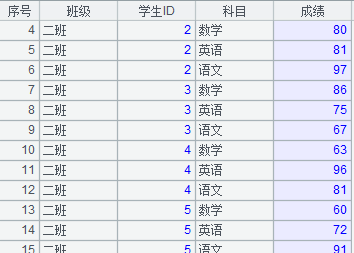
利用集算器,我們可以很容易地將這兩個結構相同的表合并為一個表,集算器的 SPL 腳本如下:

A1、A2 和 B1、B2 分別讀取了兩個庫里的學生成績表,而 A3 用一種簡單直觀的方式就把兩個表合并了。
這種方式實際上是把兩個表都讀入了內存,分別生成了集算器的序表對象,然后利用序表的運算“|”完成了合并。可能有的同學會問:如果我的數據量比較大,無法全部讀入內存怎么辦?沒關系,專為處理大數據而生的集算器,決不會被這么簡單的小問題難住。我們可以使用游標,同樣可以實現表的快速拼接:

A2、B2 分別用游標打開兩個庫里的學生成績表,A3 則使用 conjx() 函數將這兩個游標合并,形成了一個新的可以同時訪問兩個表的游標。
對應于 SQL,這種簡單合并好比只是完成了 from 工作,讓結構相同的跨庫表的數據“縱向”拼接成了一個可以訪問的序表或者游標,而實際運算中,還會涉及過濾 (where/having)、分組聚合 (group+sum/count/avg/max/min)、連接 (join+on)、去重 (distinct)、排序 (order)、取部分數據 (limit+offset),等等操作,下面我們就將對這些運算一一展開討論。
當然,我們在處理這些運算的需求時,不能只是簡單的實現功能,我們還需要考慮實現的效率和性能,因此原則上,我們會盡量利用數據庫的計算能力,而集算器主要負責混合運算。不過,有時也需要由集算器負責幾乎所有的運算,數據庫僅僅負責存儲數據。
2. WHERE
where 過濾的本質是通過比較計算,去除比較的結果是 false 的記錄,因此 where 只作用于一條記錄,不涉及記錄之間的運算,也不需要考慮數據位于哪個數據庫。比如,在前面的例子中,我們要統計出“一班”所有同學的“數學”成績,單庫中的 SQL 是這樣的:
SELECT 學生 ID, 成績 FROM 學生成績表 WHERE 科目 ='數學' AND 班級 =‘一班'
多庫時,也只要將 where 子句直接寫在 SQL 中,讓各個數據庫去并行處理過濾就可以了:

我們也可以讓集算器負責所有過濾運算,數據庫僅存儲數據。這時可以使用集算器的 select 函數(與 SQL 的 select 關鍵字不同)

數據量較大時,同樣也可以將序表換成游標,使用 conjx 函數進行連接:

3. ORDER BY 和 LIMIT OFFSET
order by 是在結果集產生后才進行的處理。在上面的例子中,如果我們要按數學成績排序,對于單數據庫,只需要加上 order by 子句:
SELECT 班級, 學生 ID, 成績 FROM 學生成績表 WHERE 科目 ='數學' AND 班級 =‘一班' ORDER BY 成績
而對于多數據庫,可以讓數據庫先分別排序,然后由集算器歸并有序數據。這樣可以最大的發揮數據庫與并行服務器的性能。

也可以倒序排序,歸并時在排序字段前加“-”(merge 函數可以不加“-”,不過按標準寫法是加上的)

當然也可以完全由集算器來排序:

由集算器實現倒序排序:

而對于大數據量,需要使用游標及 mergex 來完成有序歸并:

limit 和 offset 的執行又在 order 之后,例子中如果想取數學成績除了第一名之后的前十名(可以少于但不能多于),單庫情況下 SQL 是這樣的:
SELECT 班級, 學生 ID, 成績 FROM 學生成績表 WHERE 科目 ='數學' AND 班級 =‘一班' ORDER BY 成績 DESC LIMIT 10 OFFSET 1
多數據庫時,可以用集算器的 to 函數實現 limit offset 的功能,to(n+1,n+m) 等同于 limit m offset n

對于大數據量使用游標的情況,offset 功能可以使用集算器函數 skip 實現,而 limit 的功能則可以使用函數 fetch 實現

4. 聚合運算
我們來討論五種常見的聚合運算:sum/count/avg/max/min。
? sum 的基礎是加法,根據加法結合律,各數據庫中內部數據先分別求和,然后拼接成一張表后再求總和,與先拼接成一張表然后一起求和的結果,其實是一樣的。
? count 的本質,是對每項非 null 數據計 1,null 數據計 0,然后進行累加計算。所以其本質仍是加法運算,與 sum 一樣符合加法結合律。唯一不同的是對原始數據不是累加其本身的數值而是計 1(非 null)或計 0(為 null)。
? avg 的本質,是當 count > 0 時 avg = sum/count,當 count = 0 時 avg = null。顯然 avg 不能像 sum 或 count 那樣先分別計算了。不過根據定義,我們可以先算出 sum 和 count,再通過 sum 和 count 計算出 avg。
? max 和 min 的基礎都是比較運算,而因為比較運算具有傳遞性,因此所有數據庫的最值,可以通過比較各個數據庫的最值得到。
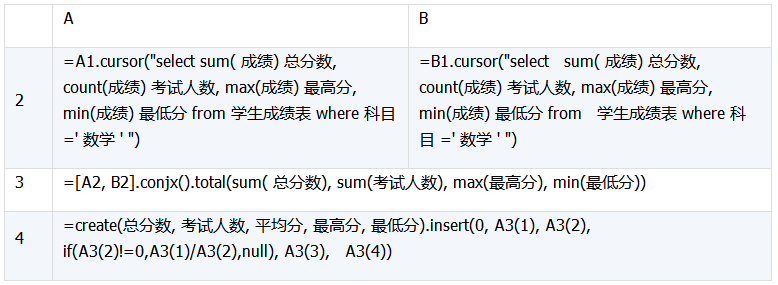
依舊是上面的例子,這次我們要求兩個班全體學生的數學總分、人數、平均分、最高及最低分,對于單源數據:
SELECT sum(成績) 總分數, count(成績) 考試人數, avg(成績) 平均分, max(成績) 最高分, min(成績) 最低分 FROM 學生成績表 WHERE 科目 ='數學'
聚合運算的結果集很小,只有一行,因此無論源數據量的大小,都可以使用游標,代碼如下:
事實上,前面提到的 order by +limit offset 本質上也可以看成是一種聚合運算:top。從這個角度進行優化,可以獲得更高的計算效率。畢竟數據量大時,全排序的成本很高,而且取前 N 個數據的操作也并不需要全排序。當然,這個方法對于數據量小的情況也同樣適用。
具體來說,對于 order by F limit m offset n 的情況,只需先用 top(n+m, F, ~),再用 to(n+1,) 就行了。
我們仍以之前的含 order by+limit offset 的 SQL 語句為例:
SELECT 班級, 學生 ID, 成績 FROM 學生成績表 WHERE 科目 ='數學' AND 班級 =‘一班' ORDER BY 成績 DESC LIMIT 10 OFFSET 1
對于多數據庫, 腳本如下,其中倒序排序只需在排序字段前加“-”:

5. GROUP BY、DISTINCT 和 HAVING
A、分組聚合運算
對于 group by,因為最終所得結果與樣本個體的輸入順序無關,所以只要樣本的總體不變,最終結果也不會變。也就是說,只要在從分庫中提取數據和最終匯總全部數據時,都預先進行了分類運算即可。
假設我們想分別求一、二班的數學總分、人數、平均分、最高及最低分,單數據庫如下:
SELECT 班級, sum(成績) 總分數, count(成績) 考試人數, avg(成績) 平均分, max(成績) 最高分, min(成績) 最低分 FROM 學生成績表 WHERE 科目 ='數學' GROUP BY 班級
我們分三種情況討論:
第一,對于小數據,聚合運算的結果集只會更小,這時推薦使用 query+groups:

第二,對于大數據量,如果結果集也很大,那么就應該使用 cursor+groupx。
另外,由于大結果集的分組計算較慢,需要在外存產生緩存數據。而如果我們在數據庫中對數據先排序,則可以避免這種緩存(此時計算壓力會轉到數據庫,因此需要根據實際情況權衡,通常情況下,數據庫服務器的計算能力會更強一些)。
具體的辦法是對 SQL 的結果集使用 order by 排序,然后在集算器中使用 mergex 函數歸并后,再使用 groupx 的 @o 選項分組:

當然如果不希望加重數據庫負擔,也可以讓數據庫只做分組而不排序,此時集算器直接用 groupx,注意不能加 @o 選項。另外匯總數據時,也要把 mergex 換成 conjx:

第三,如果已明確地知道結果集很小,那么推薦用 cursor+groups
此時 groups 比 groupx 有更好的性能,因為 groups 將運算數據都保存在內存中,比 groupx 節省了寫入外存文件的時間。
另外用 groups 可以不要求在數據庫中預先排序,因為數據庫 group by 的結果集本身不一定有序,再使用 orde by 排序也會增加成本。而對于小結果集,集算器用 groups@o 也并不一定比直接用 groups 更有效率。
通常,匯總數據要用 conjx

B、去重后計數 (count distinct)
在各個數據庫內去重,可以使用 distinct 關鍵字。而數據庫之間的數據去重,則可以使用集算器的 merge@u 函數。要注意的是使用前應該確保表內數據對主鍵字段(或者具有唯一性的一個或多個字段)有序。
對于 distinct 來說, sum(distinct)、avg(distinct) 的計算方法與 count(distinct) 大同小異,而且業務中不常用到,而 max(distinct)、min(distinct) 與單純使用 max、min 沒有區別。因此,我們只以 count(distinct) 為例加以說明。
比如,想要計算全年級(假設只有一班和二班)語數外三科至少有一科不及格需要補考的總人數,單數據庫的 SQL 是這樣的:
SELECT count(distinct 學生 ID) 人數 FROM 學生成績表 WHERE 成績 <60
對于多源數據,全分組聚合在使用游標或序表方面沒有差別,為了語法簡便起見以游標為例:

再如,想要分別計算每班語數外三科至少有一科不及格需要補考的總人數,單數據庫的 SQL 是這樣的:
SELECT 班級, count(distinct 學生 ID) 人數 FROM 學生成績表 WHERE 成績 <60 GROUP BY 班級
對于多數據庫,同樣需要先匯總去重,再進行分組聚合。匯總前需要數據有序,且匯總后數據仍然有序,所以分組函數 groups 和 groupx 都可以使用 @o 選項。
對于小數據量,可以使用 merge@u、groups@o 和 query:

對于大數據量小結果集,可以使用 mergex@u、groups@o 和 cursor:

對于大數據量大結果集,可以使用 mergex@u、groupx@o 和 cursor:

C、對聚合字段過濾(having)
having 是對聚合 (分組) 后得出的結果集再做過濾。所以當語句中有 having 出現時,如果聚合 (分組) 操作沒有徹底執行完畢,需要將 having 子句先提取出來。待數據徹底完成聚合 (分組) 操作之后,再執行條件過濾。
對于多源數據,如果聚合計算是在匯總之后才能最終完成,那么 having 必須使用集算器的函數 select 來實現過濾。
下面主要說明這種聚合計算在匯總之后才完成的情況:比如,想要獲得一班和二班的三個科目的考試中,有哪些平均分是低于 60 分的。對于單數據庫,SQL 可以這樣寫:
SELECT 班級, 科目, avg(成績) 平均分 FROM 學生成績表 GROUP BY 班級, 科目 HAVING avg(成績)<60
對于多數據庫,相關集算器執行代碼如下:

對于大數據量,需要使用游標 (select 函數同樣適用于游標)

6. JOIN ON
跨庫的 JOIN 實現起來非常困難,不過比較幸運的是,我們可以通過存儲設計避免很多跨庫 JOIN。我們分三種情況討論:
1. 同維表分庫,需要重新拼接為一個表
2. 要連接的外鍵表在每個庫中都有相同的一份
3. 需要連接的外鍵表在另一個庫中
對于集算器來講,前兩種的處理情況是一樣的:都不需要涉及跨庫 join,join 操作都可以在數據庫內完成。區別只在于第一種是分庫表,數據庫之間沒有重復數據;而第二種則要求把外鍵表的數據復制到每個庫中。
如果外鍵表沒有復制到每個庫中,那就會涉及真正的跨庫 join,因為很復雜,這里只舉一個內存外鍵表的例子,其它更復雜情況會有專門的文章闡述。
A、同維表或主子表同步分庫
所謂同維表,簡單來講就是兩個表的主鍵字段完全一樣,且其中一個表的主鍵與另一個表的主鍵有邏輯意義上的外鍵約束(并不要求數據庫中一定有真正的外鍵,主鍵同理也是邏輯上的主鍵并不一定存在于數據庫中)。
假設有兩個庫,每個庫中有兩個表,分別記為 A 庫中的 A1 表和 A2 表,B 庫中的 B1 表和 B2 表。從邏輯上看 1 表是 A1 表加上 B1 表,2 表是 A2 表加上 B2 表,我們再假設 1 表與 2 表為同維表,現在要做 1 表與 2 表的 join 連接運算。
所謂同步分庫,就是在設計分庫存儲時,保證了 1 表和 2 表按主鍵進行了同步的分割。也就是必須保證分庫之后,A1 和 B2 的 join 等值連接的結果是空集,同樣 A2 和 B1 的 join 等值連接的結果也是空集,這樣也就不必有跨庫的 join 連接運算了。
舉例說明,比如有兩張表:股票信息與公司信息,表的結構如下:
公司信息
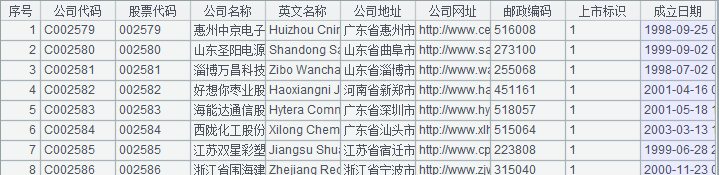
股票信息
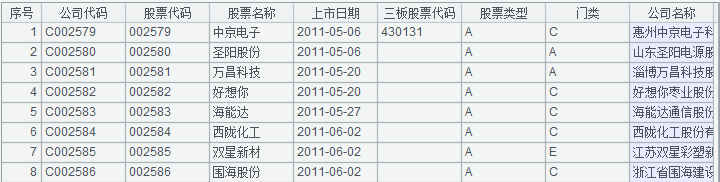
兩個表的主鍵都是 (公司代碼, 股票代碼),且股票信息的主鍵與公司信息的主鍵有邏輯意義上的外鍵約束關系,二者互為同維表。
現在假設我想將兩個表拼接在一起,單數據庫時 SQL 是這樣的:
SELECT * FROM 公司信息 T1 JOIN 股票信息 T2 ON T1. 公司代碼 =T2. 公司代碼 AND T1. 股票代碼 = T2. 股票代碼
現假設公司信息分為兩部分,分別存于 HSQL 和 MYSQL 數據庫中,股票信息同樣分為兩部分,分別存于 HSQL 和 MYSQL 數據庫中,且二者是同步分庫。
join 連接公司信息與股票信息的集算器代碼:

對于大數據:

主子表的情況與同維表類似,即一個表(主表)的主鍵字段被另一個表(子表)的主鍵字段所包含,且子表中對應的主鍵字段與主表的主鍵有邏輯意義上的外鍵約束關系。
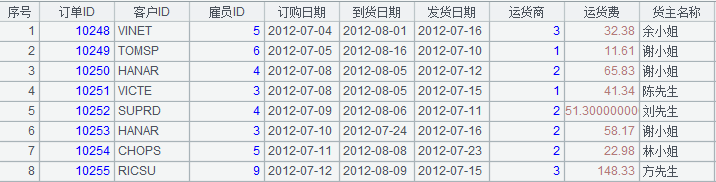
舉例說明,比如有兩張表:訂單與訂單明細,表的結構如下:
訂單
訂單明細
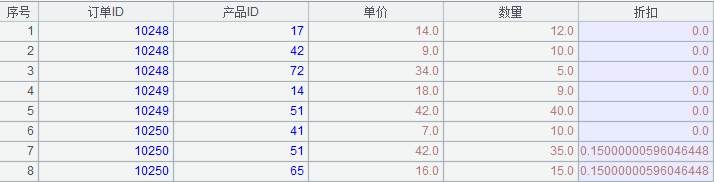
其中訂單是主表,主鍵為 (訂單 ID);而訂單明細為子表,主鍵為 (訂單 ID, 產品 ID),且訂單明細的主鍵字段訂單 ID,與訂單的主鍵有邏輯意義上的外鍵約束關系,顯然二者為主子表的關系。
現在假設我想將兩個表拼接在一起,單數據庫的 SQL 是這樣的:
SELECT * FROM 訂單 T1 JOIN 訂單明細 T2 ON T1. 訂單 ID=T2. 訂單 ID
現假設訂單分為兩部分,分別存于 HSQL 和 MYSQL 數據庫中,訂單明細同樣分為兩部分,分別存于 HSQL 和 MYSQL 數據庫中,且二者同步分庫。
join 連接訂單與訂單明細的集算器代碼:

對于大數據:

B、外鍵表復制進每個庫
所謂外鍵表,即是指連接字段為外鍵字段的情況。這種外鍵表 join 也是業務上常見的一種情況。因為要連接的外鍵表在每個庫中都有同一份,那么兩個外鍵表匯總并去重后,其實還是任一數據庫中原來就有的那個外鍵表。
而 join 的連接操作,本質上可以視為一種乘法,因為 join 連接等價于 cross join 后再用 on 中條件進行過濾。則根據乘法分配率可以推導出:若是需要做連接操作的外鍵表(不妨設為連接右側的表)在每個庫中都有同一份,則連接左側的表(每個數據庫中各有其一部分)在匯總后再連接,等同于各數據中的連接左側的表與外鍵表先做連接操作后,再匯總到一起的結果。如圖所示:
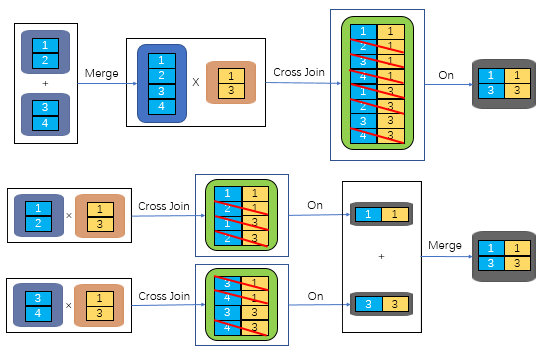
所以我們在存儲設計時,只要在每個數據庫中把外鍵表都重復一下,就可以避免復雜的跨庫 join 操作。一般情況下,外鍵表作為維表的數據量相對較小,這樣重復的成本就不會很高,而事實表則會得很大,然后用分庫存儲的方法,來解決運算速度緩慢或存儲空間不足等問題。
例如,有兩個表:客戶銷售表和客戶表,其中客戶銷售表的外鍵字段:客戶,與客戶表的主鍵字段:客戶 ID,有外鍵約束關系。現在我們想查詢面向河北省各公司的銷售額記錄,對于單數據源,它的 SQL 是這樣寫的:
SELECT T1. 公司名稱 公司名稱, T2. 訂購日期 訂購日期, T2. 銷售額 銷售額 FROM 客戶表 T1 JOIN 客戶銷售表 T2 ON T1. 客戶 ID=T2. 客戶 WHERE T1. 省份 ='河北'
對于多數據源的情況,我們假設客戶銷售表分別存儲在兩個不同的數據庫中,而每個數據庫中都有同一份的客戶表做為外鍵表。則相關的集算器代碼如下:
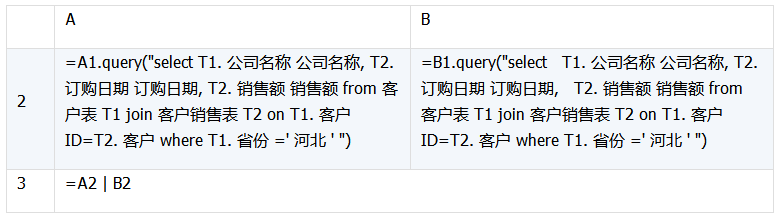
大數據量使用游標時:

C、需要連接的外鍵表在另一個庫中
對于維表(外鍵表)也被分庫的情況,我們只考慮維表全部可內存化的情況,不可內存化時,常常就不適合再將數據存在數據庫中了,需要專門針對性的的存儲和計算方案,這將在另外的文章中專門討論。在這里我們只通過例子來討論維表可內存化的情況。
對于這種情況,當涉及的數據量比較大而需要使用游標時,計算邏輯會變得比較復雜。所以我們在這里只講一下針對小數據量的使用序表的 join 處理方法。關于對大數據量的使用游標的 join 處理,會另有一篇文章做專門的介紹。
當要做 join 連接運算的外鍵表全部或部分存儲在另一個庫中時,最直觀的辦法就是將兩個表都提取出來并各自匯總后,再計算 join 連接。
下面仍以客戶銷售表和客戶表來舉例,假設外鍵表客戶表也分別存儲在兩個數據庫中,此時就不能在 SQL 中使用 join 關鍵字來實現連接運算了,但我們可以將其提取出來后,用集算器的 join 函數來實現目的,它的集算器代碼如下所示:
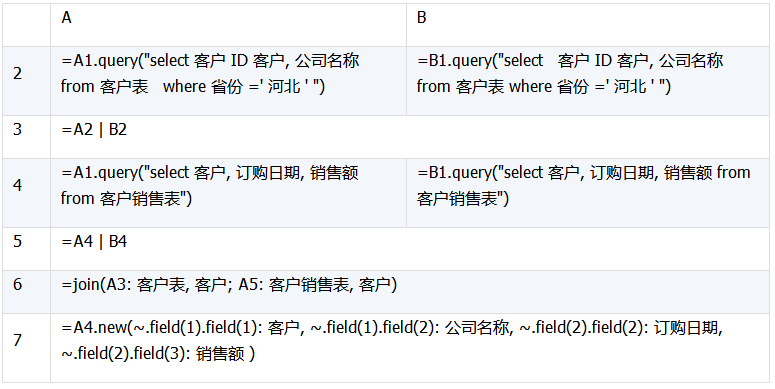
當事實表數據量較大的時候,也可以使用游標處理事實表,只需將 join 換成 cs.join 即可:

7. 簡單 SQL
前面我們主要是從計算原理的角度出發,分析了如何使用集算器實現類似 SQL 效果的多數據源混合計算。除此之外,集算器還提供了一種更簡單、直觀的方法,那就是可以在各個數據庫上通過 SQL 查詢獲取游標,用所有這些游標構建成一個多路游標對象,再用簡單 SQL 對這個多路游標做二次處理。如果簡單 SQL 中沒有涉及 join 的運算,甚至還可以讓集算器直接將一句簡單 SQL 翻譯成各種數據庫的 SQL,從而實現更進一步的自動化。不過這種辦法屬于比較保守的做法,雖然簡單直接,但不能利用所了解的數據情況進行優化(比如不會使用 groups),因此性能就會差一些。
下面仍舊用學生成績的例子,我們想要計算每個班的數學成績的總分、考試人數、平均分、最高分和最低分,使用簡單 SQL 處理這個問題的集算器代碼如下:

因為使用了游標,所以這種寫法也可以用于大數據量。另外再提一句,這個辦法甚至也可以用于非數據庫的數據源(比如文件數據源)!簡單 SQL 的特性可參考相關文檔,這里就不再進一步舉例了。
關于“數據庫中跨庫數據表運算的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





