溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
作為一名應用開發者,數據庫應用已經非常廣泛了。你可能使用過關系型數據,比如MySQL、PostgreSQL,也可能使用過文檔存儲,比如MongoDB,或者key-value數據庫,比如Redis。每一種數據庫都有它的長處,也許你還正在考慮使用分布式數據庫,比如Cassandra,來解決你手頭上的工作。
使用這些數據產品并不是要取代原有的數據產品,而是為不同的應用場景提供更多的選擇。NoSQL代表著:選擇合適的方案處理合適的業務場景。
在“Cassandra基本介紹”這個課程,我們將討論從關系型數據庫轉變為Cassandra的主要原因,以及Cassandra基本特點。 在本章結束后,你應該學些到:
RDBMS特點
RDBMS是否適合大數據
第三范式不可擴展
Sharding是一個惡夢
高可用..不是真實的
缺點總結
課程總結
下面我們就先介紹一下,關系型數據庫:
RDBMS特點
RDBMS適合中型數據,在單臺機器上工作良好,比如MySQL、PostgreSQL。
對于數百個并發用戶支持較好。
ACID支持良好
RDBMS是否適合大數據
對于大數據,必然需要水平擴展,MySQL的master/slave模式,將導致ACID(A:原子性,C:一致性,I:隔離性,D:持久性)不復存在
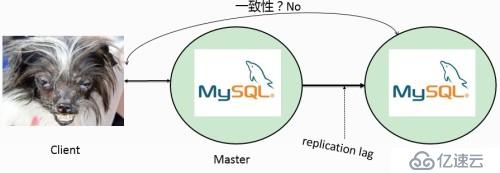
第三范式不可擴展(沒有冗余)
由于查詢的復雜性,以及用戶同時需要快速響應,因為用戶是沒有耐心的,導致數據必須反范式化設計。
Sharding是一個惡夢
數據位于每一個shard
join和聚合困難
需要反范式化
查詢需要使用shard規則或路由,來命中shard
添加shard需要手動遷移數據

高可用..不是真實的
master為單點故障
不支持多數據中心

缺點總結
水平擴展是頭疼的一件事
ACID在本地是best,多機存在一致性問題
重新sharding需要手動遷移數據
往往為了性能需要反范式化
高可用復雜,需要額外操作
課程總結
既然RDBMS有以上缺點,那我們就需要解決它們:
強一致性是不現實的:So,放棄他
重新sharding是困難的:So,我們需要自動完成
Master failover:So,我們應該不使用master/slave模式
數據分布式和聚合 no good:So,對于實時查詢性能,需要進行反范式化,目的是讓查詢總是命中在1臺機器上
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





