溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
注:大部分內容參考http://www.cnblogs.com/voidsky/p/5490798.html,但原文不是存在數據庫中。
首先創建一個項目douban9fen
kuku@ubuntu:~/pachong$ scrapy startproject douban9fen New Scrapy project 'douban9fen', using template directory '/usr/local/lib/python2.7/dist-packages/scrapy/templates/project', created in: /home/kuku/pachong/douban9fen You can start your first spider with: cd douban9fen scrapy genspider example example.com
kuku@ubuntu:~/pachong$ cd douban9fen/
首先,我們要確定所要抓取的信息,包括三個字段:(1)書名,(2)評分,(3)作者
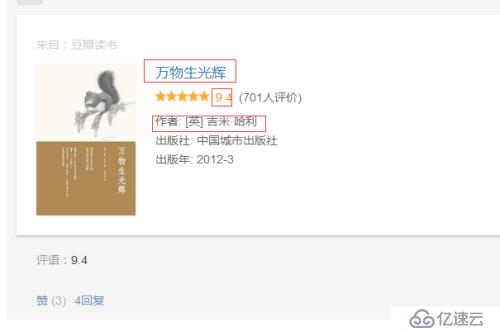
然后,讓我們分析下,采用火狐瀏覽器,進入https://www.douban.com/doulist/1264675/
按F12對上述頁面進行調試
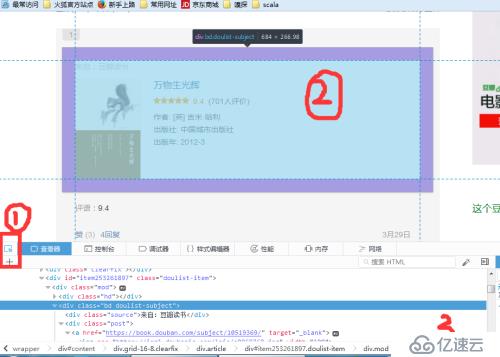
分別按照1、2、3 的步驟查看每個對象所屬的div,關閉調試窗口
進而,在頁面中右擊查看頁面源代碼,在頁面源代碼中查看搜索3中的div標簽下class為bd doulist-subject的地方
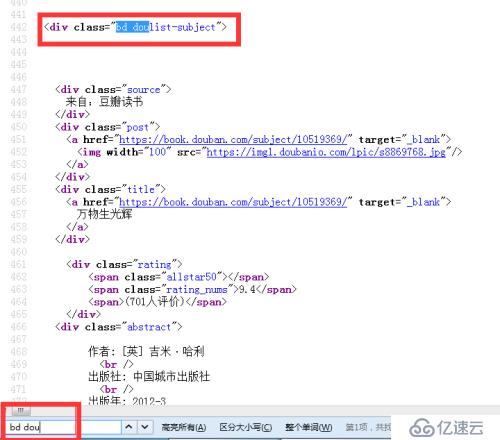
根據先大后小的原則,我們先用bd doulist-subject,把每個書找到,然后,循環對里面的信息進行提取
提取書大框架:
'//div[@class="bd doulist-subject"]'
提取題目:
'div[@class="title"]/a/text()'
提取得分:
'div[@class="rating"]/span[@class="rating_nums"]/text()'
提取作者:(這里用正則方便點)
'<div class="abstract">(.*?)<br'
經過上述分析,接下來進行代碼的編寫
kuku@ubuntu:~/pachong/douban9fen$ ls
douban9fen scrapy.cfg
kuku@ubuntu:~/pachong/douban9fen$ tree douban9fen/
douban9fen/ ├── __init__.py ├── items.py ├── pipelines.py ├── settings.py └── spiders └── __init__.py
kuku@ubuntu:~/pachong/douban9fen/douban9fen/spiders$ vim db_9fen_spider.py
添加以下內容:
# -*- coding:utf8 -*-
import scrapy
import re
class Db9fenSpider(scrapy.Spider):
name = "db9fen"
allowed_domains = ["douban.com"]
start_urls = ["https://www.douban.com/doulist/1264675/"]
#解析數據
def parse(self,response):
# print response.body
ninefenbook = response.xpath('//div[@class="bd doulist-subject"]')
for each in ninefenbook:
title = each.xpath('div[@class="title"]/a/text()').extract()[0]
title = title.replace(' ','').replace('\n','')
print title
author = re.search('<div class="abstract">(.*?)<br',each.extract(),re.S).group(1)
author = author.replace(' ','').replace('\n','')
print author
rate = each.xpath('div[@class="rating"]/span[@class="rating_nums"]/text()').extract()[0]
print rate保存。
為方便執行,我們將建立一個main.py文件
kuku@ubuntu:~/pachong/douban9fen/douban9fen/spiders$ cd ../.. kuku@ubuntu:~/pachong/douban9fen$ vim main.py
添加以下內容,
# -*- coding:utf8 -*-
import scrapy.cmdline as cmd
cmd.execute('scrapy crawl db9fen'.split()) #db9fen 對應著db_9fen_spider.py文件中的name變量值保存。
此時,我們可以執行下
kuku@ubuntu:~/pachong/douban9fen$ python main.py
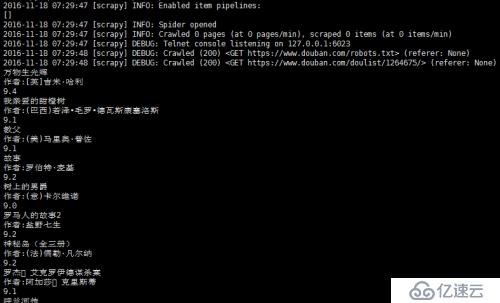
但此時只能抓取到當前頁面中的信息,查看頁面中的后頁信息
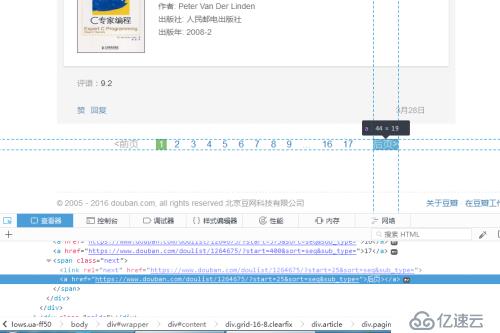
可以看到是存在標簽span中的class="next"下,我們只需要將這個鏈接提取出來,進而對其進行爬取
'//span[@class="next"]/link/@href'
然后提取后 我們scrapy的爬蟲怎么處理呢?
可以使用yield,這樣爬蟲就會自動執行url的命令了,處理方式還是使用我們的parse函數
yield scrapy.http.Request(url,callback=self.parse)
然后將更改db_9fen_spider.py文件,添加以下內容到for函數中。
nextpage = response.xpath('//span[@class="next"]/link/@href').extract()
if nextpage:
print nextpage
next = nextpage[0]
print next
yield scrapy.http.Request(next,callback=self.parse)如圖所示
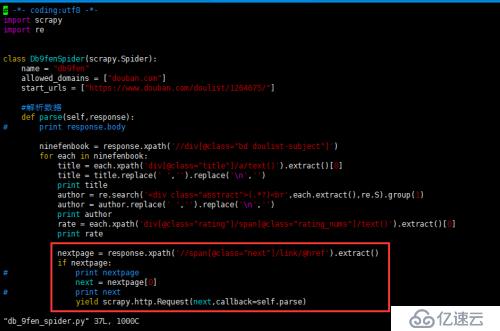
可能有些人想問,next = nextpage[0]什么意思,這里可以解釋以下,變量nextpage是一個列表,列表里面存的是一個鏈接字符串,next = nextpage[0]就是將這個鏈接取出并賦值給變量next。
現在可以在items文件中定義我們要抓取的字段
kuku@ubuntu:~/pachong/douban9fen/douban9fen$ vim items.py
編輯item.py文件中的內容是:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy from scrapy import Field class Douban9FenItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = Field() author = Field() rate = Field()
定義好字段之后,將重新對db_9fen_spider.py進行編輯,將剛才抓取到的三個字段存放在items.py中類的實例中,作為屬性值。
kuku@ubuntu:~/pachong/douban9fen/douban9fen$ cd spiders/ kuku@ubuntu:~/pachong/douban9fen/douban9fen/spiders$ vim db_9fen_spider.py
# -*- coding:utf8 -*-
import scrapy
import re
from douban9fen.items import Douban9FenItem
class Db9fenSpider(scrapy.Spider):
name = "db9fen"
allowed_domains = ["douban.com"]
start_urls = ["https://www.douban.com/doulist/1264675/"]
#解析數據
def parse(self,response):
# print response.body
ninefenbook = response.xpath('//div[@class="bd doulist-subject"]')
for each in ninefenbook:
item = Douban9FenItem()
title = each.xpath('div[@class="title"]/a/text()').extract()[0]
title = title.replace(' ','').replace('\n','')
print title
item['title'] = title
author = re.search('<div class="abstract">(.*?)<br',each.extract(),re.S).group(1)
author = author.replace(' ','').replace('\n','')
print author
item['author'] = author
rate = each.xpath('div[@class="rating"]/span[@class="rating_nums"]/text()').extract()[0]
print rate
item['rate'] = rate
yield item
nextpage = response.xpath('//span[@class="next"]/link/@href').extract()
if nextpage:
# print nextpage
next = nextpage[0]
# print next
yield scrapy.http.Request(next,callback=self.parse)編輯setting.py,添加數據庫配置信息
USER_AGENT = 'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.8.1.14) Gecko/20080404 Firefox/44.0.2' # start MySQL database configure setting MYSQL_HOST = 'localhost' MYSQL_DBNAME = 'douban9fen' MYSQL_USER = 'root' MYSQL_PASSWD = 'openstack' # end of MySQL database configure setting ITEM_PIPELINES = { 'douban9fen.pipelines.Douban9FenPipeline': 300, }
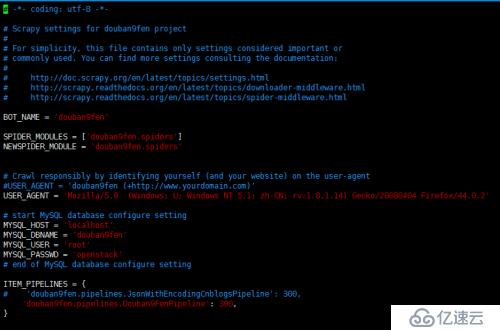
注意mysql數據庫是預先安裝進去的,可以看到數據庫的名稱為douban9fen,因此我們首先需要在數據庫中創建douban9fen 數據庫
kuku@ubuntu:~/pachong/douban9fen/douban9fen/spiders$ mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 46 Server version: 5.5.52-0ubuntu0.14.04.1 (Ubuntu) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> create database douban9fen; Query OK, 1 row affected (0.00 sec)
mysql> show databases;
+--------------------+ | Database | +--------------------+ | information_schema | | csvt04 | | douban9fen | | doubandianying | | mysql | | performance_schema | | web08 | +--------------------+ 7 rows in set (0.00 sec)
可以看到已經創建數據庫成功;
mysql> use douban9fen;
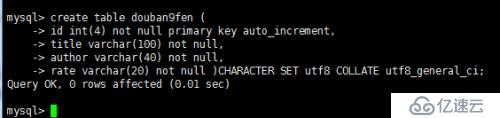
接下來創建數據表
mysql> create table douban9fen ( id int(4) not null primary key auto_increment, title varchar(100) not null, author varchar(40) not null, rate varchar(20) not null )CHARACTER SET utf8 COLLATE utf8_general_ci; Query OK, 0 rows affected (0.04 sec)
編輯pipelines.py,將數據儲存到數據庫中,
kuku@ubuntu:~/pachong/douban9fen/douban9fen$ vim pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
#將數據存儲到mysql數據庫
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class Douban9FenPipeline(object):
#數據庫參數
def __init__(self):
dbargs = dict(
host = '127.0.0.1',
db = 'douban9fen',
user = 'root',
passwd = 'openstack',
cursorclass = MySQLdb.cursors.DictCursor,
charset = 'utf8',
use_unicode = True
)
self.dbpool = adbapi.ConnectionPool('MySQLdb',**dbargs)
def process_item(self, item, spider):
res = self.dbpool.runInteraction(self.insert_into_table,item)
return item
#插入的表,此表需要事先建好
def insert_into_table(self,conn,item):
conn.execute('insert into douban9fen( title,author,rate) values(%s,%s,%s)', (
item['title'],
item['author'],
item['rate']
)
)編輯好上面的紅色標注的文件后,
kuku@ubuntu:~/pachong/douban9fen/douban9fen$ cd .. kuku@ubuntu:~/pachong/douban9fen$
再執行 main.py文件
kuku@ubuntu:~/pachong/douban9fen$ python main.py
執行過程如下:
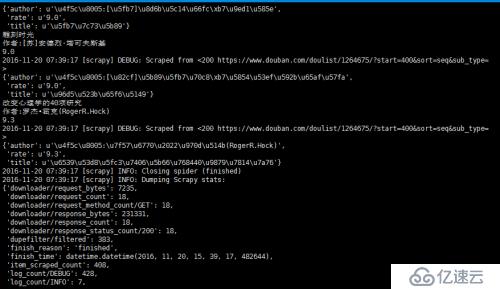
打開mysql ,查看是否已經寫入到數據庫中;
kuku@ubuntu:~/pachong/douban9fen$ mysql -uroot -p
輸入密碼openstack 登錄
mysql> show databases;
+--------------------+ | Database | +--------------------+ | information_schema | | csvt04 | | douban9fen | | doubandianying | | mysql | | performance_schema | | web08 | +--------------------+ 7 rows in set (0.00 sec)
mysql> use douban9fen;
Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed
mysql> show tables;
+----------------------+ | Tables_in_douban9fen | +----------------------+ | douban9fen | +----------------------+ 1 row in set (0.00 sec)
mysql> select * from douban9fen;
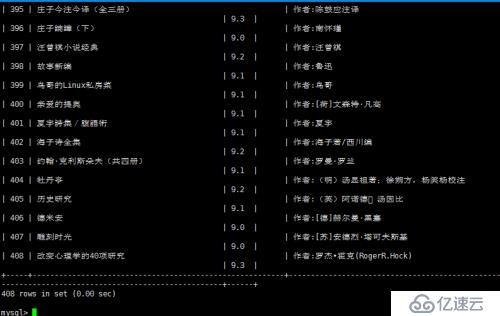
顯示能夠成功寫入到數據庫中。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





