溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了正則表達式如何實現逆序環視,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
1 問題引出
前幾天在CSDN論壇遇到這樣一個問題。
我要通過正則分別取出下面 <font color="#008000"> 與 </font> 之間的字符串
1、在 <font color="#008000"> 與 </font> 之間的字符串是沒法固定的,是隨機自動生成的
2、其中 <font color="#008000"> 與 </font>的數量也是沒法固定的,也是隨機自動生成的
<font color="#008000"> ** 這里是不固定的字符串1 ** </font>
<font color="#008000"> ** 這里是不固定的字符串2 ** </font>
<font color="#008000"> ** 這里是不固定的字符串3 ** </font>
有朋友給出這樣的正則“(?<=<font[\s\S]*?>)([\s\S]*?)(?=</font>)”,看下匹配結果。
代碼如下:
string test = @"<font color=""#008000""> ** 這里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 這里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 這里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=<font[\s\S]*?>)([\s\S]*?)(?=</font>)");
foreach (Match m in mc)
{
richTextBox2.Text += m.Value + "\n---------------\n";
}
/*--------輸出--------
** 這里是不固定的字符串1 **
---------------
<font color="#008000"> ** 這里是不固定的字符串2 **
---------------
<font color="#008000"> ** 這里是不固定的字符串3 **
---------------
*/
為什么會是這樣的結果,而不是我們期望的如下的結果呢?
/*--------輸出--------
** 這里是不固定的字符串1 **
---------------
** 這里是不固定的字符串2 **
---------------
** 這里是不固定的字符串3 **
---------------
*/
這涉及到逆序環視的匹配原理,以及貪婪與非貪婪模式應用的一些細節,下面先針對逆序環視的匹配細節展開討論,然后再回過頭來看下這個問題。
2 逆序環視匹配原理
關于環視的一些基礎講解和基本匹配原理,在正則基礎之——環視這篇博客里已有所介紹,只不過當時整理得比較匆忙,沒有涉及更詳細的匹配細節。這里僅針對逆序環視展開討論。
逆序環視的基礎知識在上面博文中已介紹過,這里簡單引用一下。
表達式 | 說明 |
(?<=Expression) | 逆序肯定環視,表示所在位置左側能夠匹配Expression |
(?<!Expression) | 逆序否定環視,表示所在位置左側不能匹配Expression |
對于逆序肯定環視(?<=Expression)來說,當子表達式Expression匹配成功時,(?<=Expression)匹配成功,并報告(?<=Expression)匹配當前位置成功。
對于逆序否定環視(?<!Expression)來說,當子表達式Expression匹配成功時,(?<!Expression)匹配失敗;當子表達式Expression匹配失敗時,(?<!Expression)匹配成功,并報告(?<!Expression)匹配當前位置成功。
2.1 逆序環視匹配行為分析
2.1.1 逆序環視支持現狀
目前支持逆序環視的語言還比較少,比如當前比較流行的腳本語言JavaScript中就是不支持逆序環視的。個人認為不支持逆序環視已成為目前JavaScript中使用正則的最大限制,一些使用逆序環視很輕松搞定的輸入驗證,卻要通過各種變通的方式來實現。
需求:驗證輸入由字母、數字和下劃線組成,下劃線不能出現在開始或結束位置。
對于這樣的需求,如果支持逆序環視,直接“^(?!_)[a-zA-Z0-9_]+(?<!_)$”就可以了搞定了,但是在JavaScript中,卻需要用類似于“^[a-zA-Z0-9]([a-zA-Z0-9_]*[a-zA-Z0-9])?$”這種變通方式來實現。這只是一個簡單的例子,實際的應用中,會比這復雜得多,而為了避免量詞的嵌套帶來的效率陷阱,正則實現起來很困難,甚至有些情況不得不拆分成多個正則來實現。
而另一些流行的語言,比如Java中,雖然支持逆序環視,但只支持固定長度的子表達式,量詞也只支持“?”,其它不定長度的量詞如“*”、“+” 、“{m,n}”等是不支持的。
源字符串:<div>a test</div>
需求:取得div標簽的內容,不包括div標簽本身
Java代碼實現:
復制代碼 代碼如下:
import java.util.regex.*;
String test = "<div>a test</div>";
String reg = "(?<=<div>)[^<]+(?=</div>)";
Matcher m = Pattern.compile(reg).matcher(test);
while(m.find())
{
System.out.println(m.group());
}
/*--------輸出--------
a test
*/
但是如果源字符串變一下,加個屬性變成“<div id=”test1”>a test</div>”,那么除非標簽中屬性內容是固定的,否則就無法在Java中用逆序環視來實現了。
為什么在很多流行語言中,要么不支持逆序環視,要么只支持固定長度的子表式呢?先來分析一下逆序環視的匹配原理吧。
2.1.2 Java中逆序環視匹配原理分析
不支持逆序環視的自不必說,只支持固定長度子表達式的逆序環視如何呢。
源字符串:<div>a test</div>
正則表達式:(?<=<div>)[^<]+(?=</div>) 
需要明確的一點,無論是什么樣的正則表達式,都是要從字符串的位置0處開始嘗試匹配的。
首先由“(?<=<div>)”取得控制權,由位置0開始嘗匹配,由于“<div>”的長度固定為5,所以會從當前位置向左查找5個字符,但是由于此時位于位置0處,前面沒有任何字符,所以嘗試匹配失敗。
正則引擎傳動裝置向右傳動,由位置1處開始嘗試匹配,同樣匹配失敗,直到位置5處,向左查找5個字符,滿足條件,此時把控制權交給“(?<=<div>)”中的子表達式“<div>”。“<div>”取得控制權后,由位置0處開始向右嘗試匹配,由于正則都是逐字符進行匹配的,所以這時會把控制權交給“<div>”中的“<”,由“<”嘗試字符串中的“<”,匹配成功,接下來由“d”嘗試字符串中的“d”,匹配成功,同樣的過程,由“<div>”匹配位置0到位置5之間的“<div>”成功,此時“(?<=<div>)”匹配成功,匹配成功的位置是位置5。
后續的匹配過程請參考 正則基礎之——環視 和 正則基礎之——NFA引擎匹配原理。
那么對于量詞“?”又是怎么樣一種情況呢,看一下下面的例子。
源字符串:cba
正則表達式:(?<=(c?b))a
復制代碼 代碼如下:
String test = "cba";
String reg = "(?<=(c?b))a";
Matcher m = Pattern.compile(reg).matcher(test);
while(m.find())
{
System.out.println(m.group());
System.out.println(m.group(1));
}
/*--------輸出--------
a
*/
可以看到,“c?”并沒有參與匹配,在這里,“?”并不具備貪婪模式的作用,“?”只提供了一個分支的作用,共記錄了兩個分支,一個分支需要從當前位置向前查找一個字符,另一個分支需要從當前位置向前查找兩個字符。正則引擎從當前位置,嘗試這兩種情況,優先嘗試的是需要向前查找較少字符的分支,匹配成功,則不再嘗試另一個分支,只有這一分支匹配失敗時,才會去嘗試另一個分支。
復制代碼 代碼如下:
String test = "dcba";
String reg = "(?<=(dc?b))a";
Matcher m = Pattern.compile(reg).matcher(test);
while(m.find())
{
System.out.println(m.group());
System.out.println(m.group(1));
}
/*--------輸出--------
a
dcb
*/
雖然有兩個分支,但向前查找的字符數可預知的,所以只支持“?”時并不復雜,但如果再支持其它不定長度量詞,情況又如何呢?
2.1.3 .NET中逆序環視匹配原理
.NET的逆序環視中,是支持不定長度量詞的,在這個時候,匹配過程就變得復雜了。先看一下定長的是如何匹配的。
復制代碼 代碼如下:
string test = "<div>a test</div>";
Regex reg = new Regex(@"(?<=<div>)[^<]+(?=</div>)");
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "\n";
}
/*--------輸出--------
a test
*/
從結果可以看到,.NET中的逆序環視在子表達式長度固定時,匹配行為與Java中應該是一樣的。那么不定長量詞又如何呢?
復制代碼 代碼如下:
string test = "cba";
Regex reg = new Regex(@"(?<=(c?b))a");
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "\n";
richTextBox2.Text += m.Groups[1].Value + "\n";
}
/*--------輸出--------
a
cb
*/
可以看到,這里的“?”具備了貪婪模式的特性。那么這個時候是否會有這樣的疑問,它的匹配過程仍然是從當前位置向左嘗試,還是從字符串開始位置向右嘗試匹配呢?
復制代碼 代碼如下:
string test = "<ddd<cccba";
Regex reg = new Regex(@"(?<=(<.*?b))a");
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "\n";
richTextBox2.Text += m.Groups[1].Value + "\n";
}
/*--------輸出--------
a
<cccb
*/
從結果可看出,在逆序環視中有不定量詞的時候,仍然是從當前位置,向左嘗試匹配的,否則Groups[1]的內容就是“<ddd<cccb”,而不是“<cccb”了。
這是非貪婪模式的匹配情況,再看一下貪婪模式匹配的情況。
復制代碼 代碼如下:
string test = "e<ddd<cccba";
Regex reg = new Regex(@"(?<=(<.*b))a");
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "\n";
richTextBox2.Text += m.Groups[1].Value + "\n";
}
/*--------輸出--------
a
<ddd<cccb
*/
可以看到,采用貪婪模式以后,雖然嘗試到“c”前面的“<”時已經可以匹配成功,但由于是貪婪模式,還是要繼續嘗試匹配的。直到嘗試到開始位置,取最長的成功匹配作為匹配結果。
2.2 匹配過程
再來理一下逆序環視的匹配過程吧。
源字符串:<div id=“test1”>a test</div>
正則表達式:(?<=<div[^>]*>)[^<]+(?=</div>) 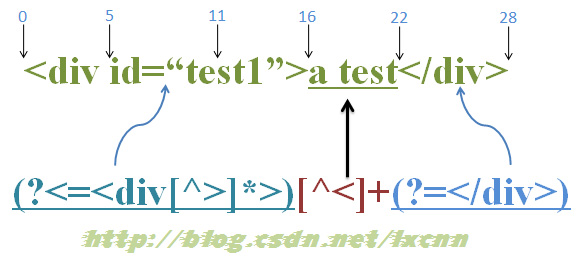
首先由“(?<=<div[^>]*>)”取得控制權,由位置0開始嘗匹配,由于“<div[^>]*>”的長度不固定,所以會從當前位置向左逐字符查找,當然,也有可能正則引擎做了優化,先計算一下最小長度后向前查找,在這里“<div[^>]*>”至少需要5個字符,所以由當前位置向左查找5個字符,才開始嘗試匹配,這要看各語言的正則引擎如何實現了,我推測是先計算最小長度。但是由于此時位于位置0處,前面沒有任何字符,所以嘗試匹配失敗。
正則引擎傳動裝置向右傳動,由位置1處開始嘗試匹配,同樣匹配失敗,直到位置5處,向左查找5個字符,滿足條件,此時把控制權交給“(?<=<div[^>]*>)”中的子表達式“<div[^>]*>”。“<div[^>]*>”取得控制權后,由位置0處開始向右嘗試匹配,由于正則都是逐字符進行匹配的,所以這時會把控制權交給“<div[^>]*>”中的“<”,由“<”嘗試字符串中的“<”,匹配成功,接下來由“d”嘗試字符串中的“d”,匹配成功,同樣的過程,由“<div[^>]*”匹配位置0到位置5之間的“<div ”成功,其中“[^>]*”在匹配“<div ”中的空格時是要記錄可供回溯的狀態的,此時控制權交給“>”,由于已沒有任何字符可供匹配,所以“>”匹配失敗,此時進行回溯,由“[^>]*”讓出已匹配的空格給“>”進行匹配,同樣匹配失敗,此時已沒有可供回溯的狀態,所以這一輪匹配嘗試失敗。
正則引擎傳動裝置向右傳動,由位置6處開始嘗試匹配,同樣匹配失敗,直到位置16處,此時的當前位置指的就是位置16,把控制權交給“(?<=<div[^>]*>)”,向左查找5個字符,滿足條件,記錄回溯狀態,控制權交給“(?<=<div[^>]*>)”中的子表達式“<div[^>]*>”。“<div[^>]*>”取得控制權后,由位置11處開始向右嘗試匹配, “<div[^>]*>”中的“<”嘗試字符串中的“s”,匹配失敗。繼續向左嘗試,在位置10處由“<”嘗試字符串中的“e”,匹配失敗。同樣的過程,直到嘗試到位置0處,由“<div[^>]*”在位置0向右嘗試匹配,成功匹配到“<div id=“test1”>”,此時“(?<=<div[^>]*>)”匹配成功,控制權交給“[^>]+”,繼續進行下面的匹配,直到整個表達式匹配成功。
總結正則表達式“(?<=SubExp1) SubExp2”的匹配過程:
1、 由位置0處向右嘗試匹配,直到找到一個滿足“(?<=SubExp1) ”最小長度要求的位置x;
2、 從位置x處向左查找滿足“SubExp1”最小長度要求的位置y;
3、 由“SubExp1”從位置y開始向右嘗試匹配;
4、 如果“SubExp1”為固定長度或非貪婪模式,則找到一個成功匹配項即停止嘗試匹配;
5、 如果“SubExp1”為貪婪模式,則要嘗試所有的可能,取最長的成功匹配項作為匹配結果。
6、 “(?<=SubExp1) ”成功匹配后,控制權交給后面的子表達式,繼續嘗試匹配。
需要說明的一點,逆序環視中的子表達式“SubExp1”,匹配成功時,匹配開始的位置是不可預知的,但匹配結束的位置一定是位置x。
3 問題分析與總結
3.1 問題分析
那么再回過頭來看下最初的問題。
復制代碼 代碼如下:
string test = @"<font color=""#008000""> ** 這里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 這里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 這里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=<font[\s\S]*?>)([\s\S]*?)(?=</font>)");
foreach (Match m in mc)
{
richTextBox2.Text += m.Value + "\n---------------\n";
}
/*--------輸出--------
** 這里是不固定的字符串1 **
---------------
<font color="#008000"> ** 這里是不固定的字符串2 **
---------------
<font color="#008000"> ** 這里是不固定的字符串3 **
---------------
*/
其實真正讓人費解的是這里的逆序環視的匹配結果,為了更好的說明問題,改下正則。
string test = @"<font color=""#008000""> ** 這里是不固定的字符串1 ** </font>
復制代碼 代碼如下:
<font color=""#008000""> ** 這里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 這里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=(<font[\s\S]*?>))([\s\S]*?)(?=</font>)");
for(int i=0;i<mc.Count;i++)
{
richTextBox2.Text += "第" + (i+1) + "輪成功匹配結果:\n";
richTextBox2.Text += "Group[0]:" + m.Value + "\n";
richTextBox2.Text += "Group[1]:" + m.Groups[1].Value + "\n---------------\n";
}
/*--------輸出--------
第1輪成功匹配結果:
Group[0]: ** 這里是不固定的字符串1 **
Group[1]:<font color="#008000">
---------------
第2輪成功匹配結果:
Group[0]:
<font color="#008000"> ** 這里是不固定的字符串2 **
Group[1]:<font color="#008000"> ** 這里是不固定的字符串1 ** </font>
---------------
第3輪成功匹配結果:
Group[0]:
<font color="#008000"> ** 這里是不固定的字符串3 **
Group[1]:<font color="#008000"> ** 這里是不固定的字符串2 ** </font>
---------------
*/
對于第一輪成功匹配結果應該不存在什么疑問,這里不做解釋。
第一輪成功匹配結束的位置是第一個“</font>”前的位置,第二輪成功匹配嘗試就是從這一位置開始。
首先由“(?<=<font[\s\S]*?>)”取得控制權,向左查找6個字符后開始嘗試匹配,由于“<”會匹配失敗,所以會一直嘗試到位置0處,這時“<font”是可以匹配成功的,但是由于“<font[\s\S]*?>”要匹配成功,匹配的結束位置必須是第一個“</font>”前的位置,所以“>”是匹配失敗的,這一位置整個表達式匹配失敗。
正則引擎傳動裝置向右傳動,直到第一個“</font>”后的位置,“<font[\s\S]*?>”匹配成功,匹配開始位置是位置0,匹配結束位置是第一個“</font>”后的位置,“<font[\s\S]*?>”匹配到的內容是“<font color="#008000"> ** 這里是不固定的字符串1 ** </font>”,其中“[\s\S]*?”匹配到的內容是“color="#008000"> ** 這里是不固定的字符串1 ** </font”,后面的子表達式繼續匹配,直到第二輪匹配成功。
接下來的第三輪成功匹配,匹配過程與第二輪基本相同,只不過由于使用的是非貪婪模式,所以“<font[\s\S]*?>”在匹配到“<font color="#008000"> ** 這里是不固定的字符串2 ** </font>”時匹配成功,就結束匹配,不再向左嘗試匹配了。
接下來看下貪婪模式的匹配結果。
復制代碼 代碼如下:
string test = @"<font color=""#008000""> ** 這里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 這里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 這里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=(<font[\s\S]*>))([\s\S]*?)(?=</font>)");
for(int i=0;i<mc.Count;i++)
{
richTextBox2.Text += "第" + (i+1) + "輪成功匹配結果:\n";
richTextBox2.Text += "Group[0]:" + m.Value + "\n";
richTextBox2.Text += "Group[1]:" + m.Groups[1].Value + "\n---------------\n";
}
/*--------輸出--------
第1輪匹配結果:
Group[0]: ** 這里是不固定的字符串1 **
Group[1]:<font color="#008000">
---------------
第2輪匹配結果:
Group[0]:
<font color="#008000"> ** 這里是不固定的字符串2 **
Group[1]:<font color="#008000"> ** 這里是不固定的字符串1 ** </font>
---------------
第3輪匹配結果:
Group[0]:
<font color="#008000"> ** 這里是不固定的字符串3 **
Group[1]:<font color="#008000"> ** 這里是不固定的字符串1 ** </font>
<font color="#008000"> ** 這里是不固定的字符串2 ** </font>
---------------
*/
僅僅是一個字符的差別,整個表達式的匹配結果沒有變化,但匹配過程差別卻是很大的。
那么如果想得到下面這種結果要如何做呢?
/*--------輸出--------
** 這里是不固定的字符串1 **
---------------
** 這里是不固定的字符串2 **
---------------
** 這里是不固定的字符串3 **
---------------
*/
把量詞修飾的子表達式的匹配范圍縮小就可以了。
復制代碼 代碼如下:
string test = @"<font color=""#008000""> ** 這里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 這里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 這里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?is)(?<=(<font[^>]*>))(?:(?!</?font\b).)*(?=</font>)");
for(int i=0;i<mc.Count;i++)
{
richTextBox2.Text += "第" + (i+1) + "輪匹配結果:\n";
richTextBox2.Text += "Group[0]:" + mc[i].Value + "\n";
richTextBox2.Text += "Group[1]:" + mc[i].Groups[1].Value + "\n---------------\n";
}
/*--------輸出--------
第1輪匹配結果:
Group[0]: ** 這里是不固定的字符串1 **
Group[1]:<font color="#008000">
---------------
第2輪匹配結果:
Group[0]: ** 這里是不固定的字符串2 **
Group[1]:<font color="#008000">
---------------
第3輪匹配結果:
Group[0]: ** 這里是不固定的字符串3 **
Group[1]:<font color="#008000">
---------------
*/
3.2 逆序環視應用總結
通過對逆序環視的分析,可以看出,逆序環視中使用不定長度的量詞,匹配過程很復雜,代價也是很大的,這也許也是目前絕大多數語言不支持逆序環視,或是不支持在逆序環視中使用不定長度量詞的原因吧。
在正則應用中需要注意的幾點:
1、 不要輕易在逆序環視中使用不定長度的量詞,除非確實需要;
2、 在任何場景下,不只是逆序環視中,不要輕易使用量詞修飾匹配范圍非常大的子表達式,小數點“.”和“[\s\S]”之類的,使用時尤其要注意。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“正則表達式如何實現逆序環視”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





