溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關如何解決正則表達式re.sub替換不完整的問題的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
title: 正則表達式re.sub替換不完整的問題現象及其根本原因
toc: true
comment: true
date: 2018-08-27 21:48:22
tags: ["Python", "正則表達式"]
category: ["Python"]
---
問題描述
問題的起因來自于一段正則替換。為了從一段HTML代碼里面提取出正文,去掉所有的HTML標簽和屬性,可以寫一個Python函數:
import re
def remove_tag(html):
text = re.sub('<.*?>', '', html, re.S)
return text這段代碼的使用了正則表達式的替換功能re.sub。這個函數的第一個參數表示需要被替換的內容的正則表達式,由于HTML標簽都是使用尖括號包起來的,因此使用<.*?>就可以匹配所有<xxx yyy="zzz">和</xxx>。
第二個參數表示被匹配到的內容將要被替換成什么內容。由于我需要提取正文,那么只要把所有HTML標簽都替換為空字符串即可。第三個參數就是需要被替換的文本,在這個例子中是HTML源代碼段。
至于re.S,在4年前的一篇文章中我講到了它的用法:https://www.jb51.net/article/146384.htm
現在使用一段HTML代碼來測試一下:
import re
def remove_tag(html):
text = re.sub('<.*?>', '', html, re.S)
return text
source_1 = '''
<div class="content">今天的主角是<a href="xxx">kingname</a>,我們掌聲歡迎!</div>
'''
text = remove_tag(source_1)
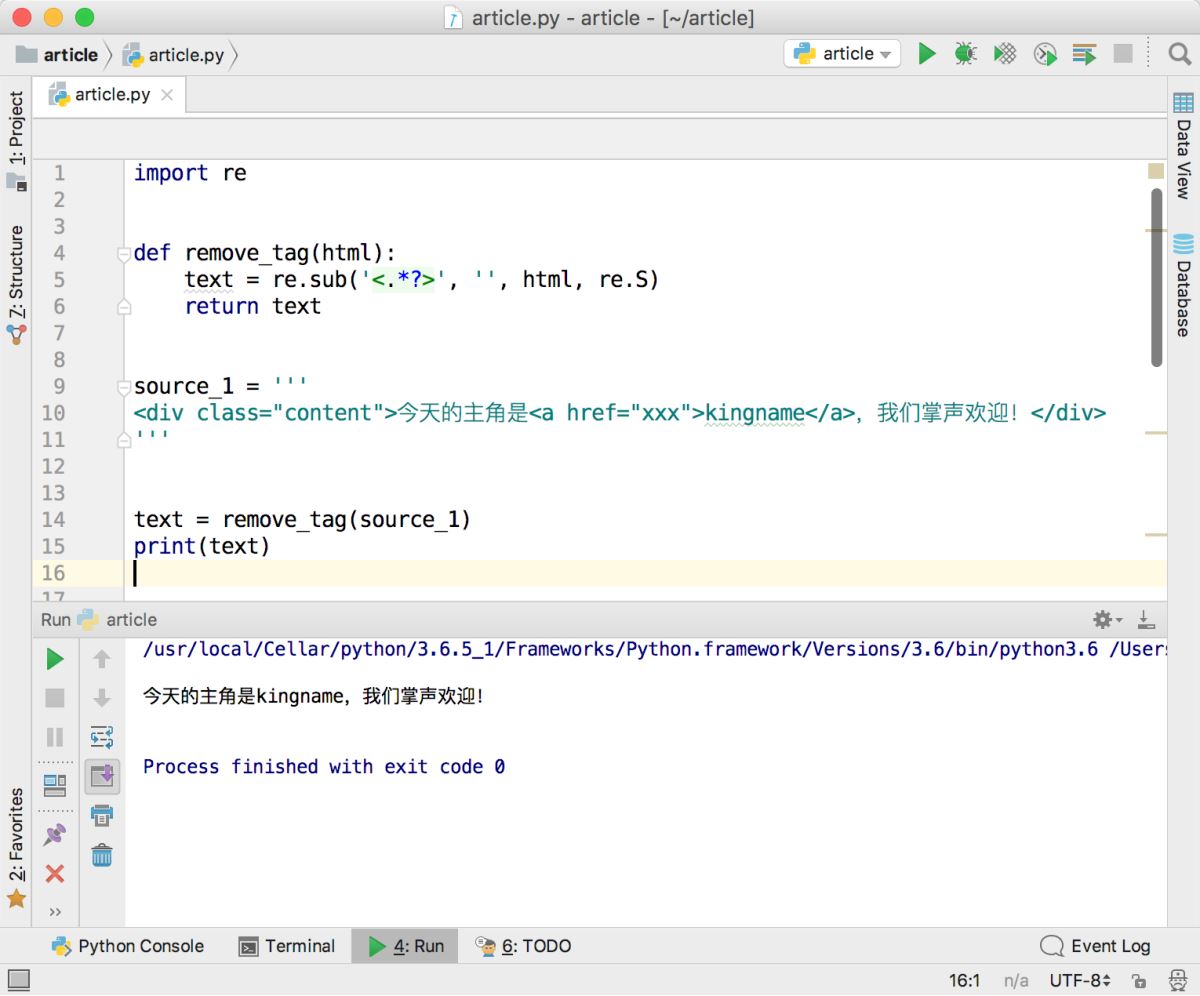
print(text)運行效果如下圖所示,功能完全符合預期
再來測試一下代碼中有換行符的情況:
import re
def remove_tag(html):
text = re.sub('<.*?>', '', html, re.S)
return text
source_2 = '''
<div class="content">
今天的主角是
<a href="xxx">kingname</a>
,我們掌聲歡迎!
</div>
'''
text = remove_tag(source_2)
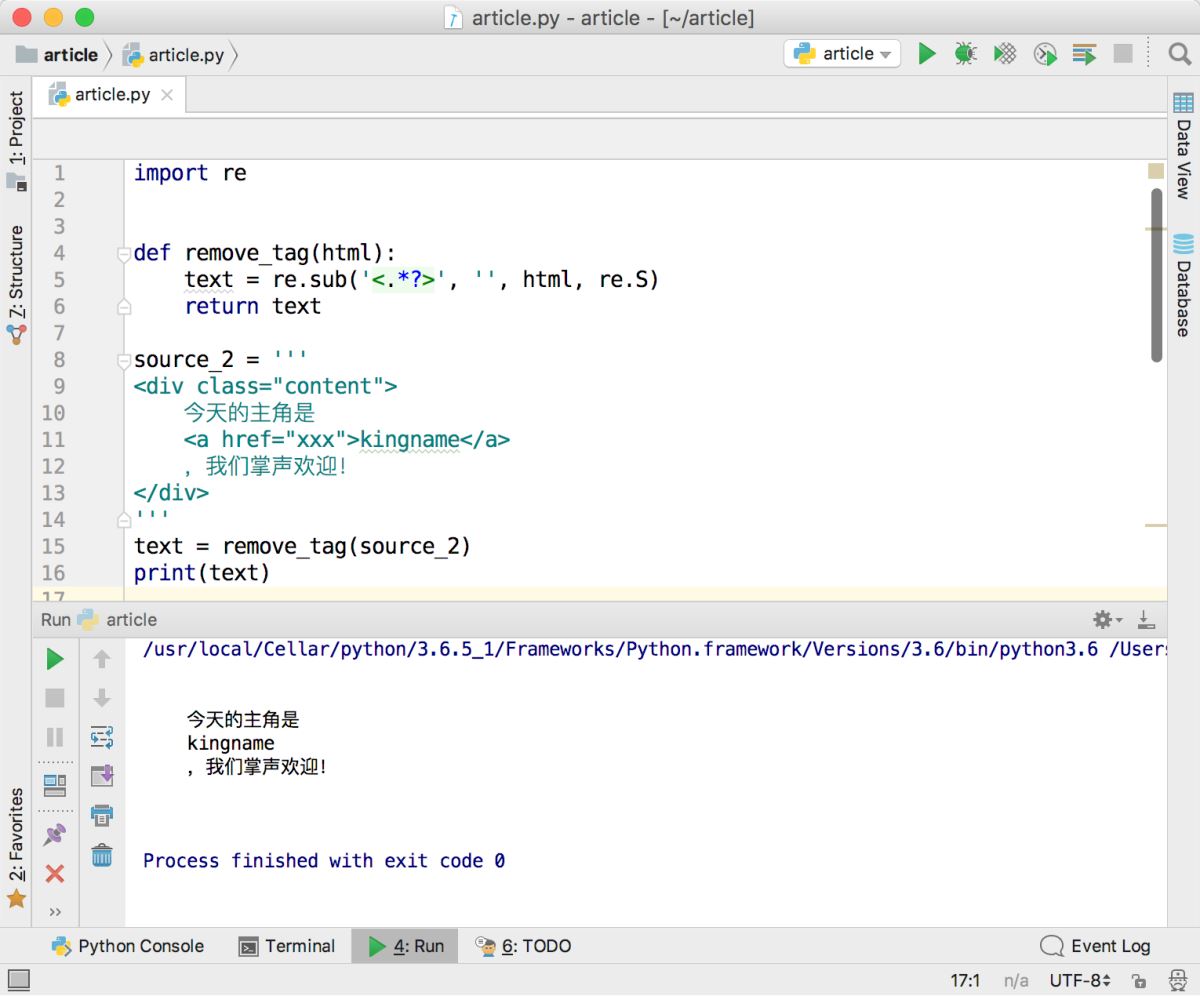
print(text)運行效果如下圖所示,完全符合預期。
經過測試,在絕大多數情況下,能夠從的HTML代碼段中提取出正文。但也有例外。
例外情況
有一段HTML代碼段比較長,內容如下:
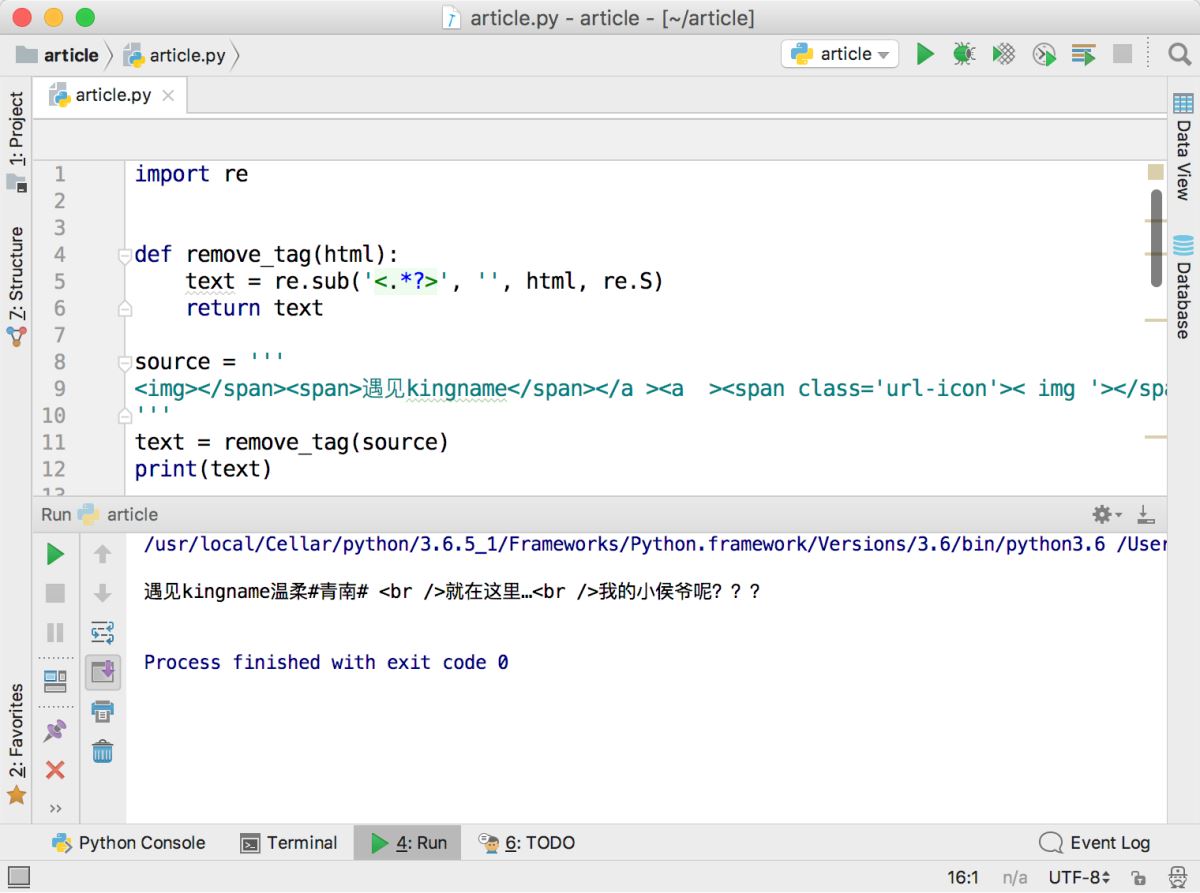
<img> </span><span>遇見kingname</span></a ><a ><span class='url-icon'>< img '></span><span >溫柔</span></a ><a ><span >#青南#</span></a > <br />就在這里…<br />我的小侯爺呢???
運行效果如下圖所示,最后兩個HTML標簽替換失敗。
一開始我以為是HTML里面的空格或者引號引起的問題,于是我把HTML代碼進行簡化:
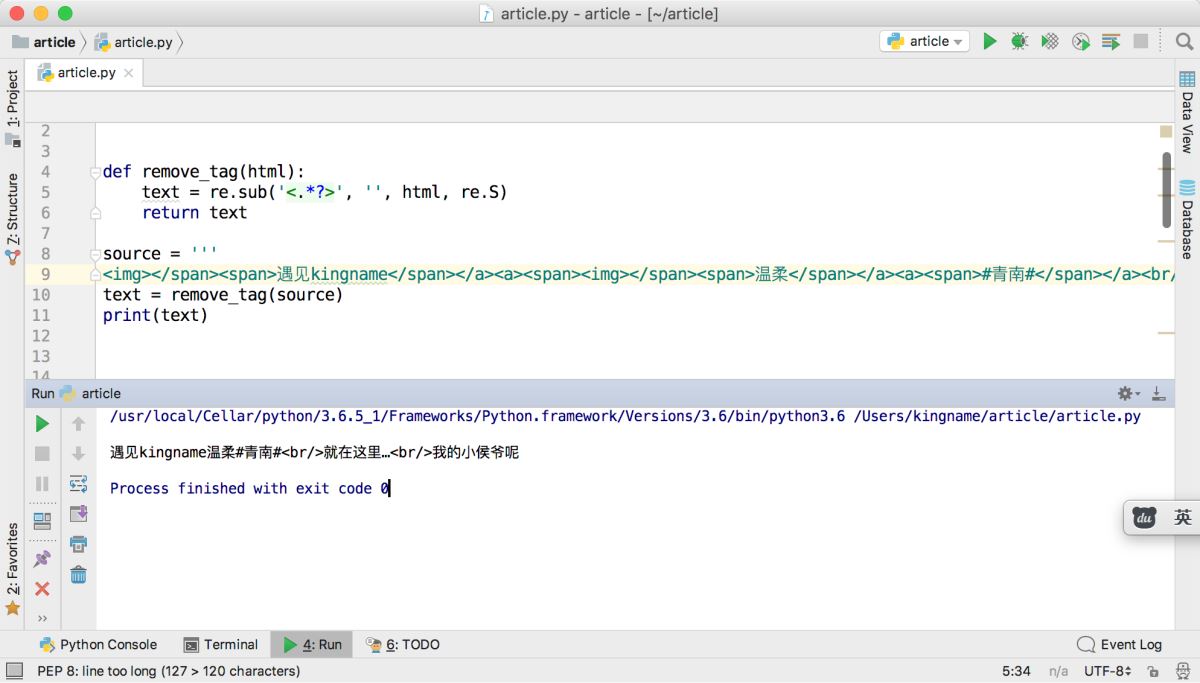
<img></span><span>遇見kingname</span></a><a><span><img></span><span>溫柔</span></a><a><span>#青南#</span></a><br/>就在這里…<br/>我的小侯爺呢
問題依然存在,如下圖所示。
而且更令人驚訝的是,如果把第一個標簽<img>刪了,那么替換結果里面就少了一個標簽,如下圖所示。
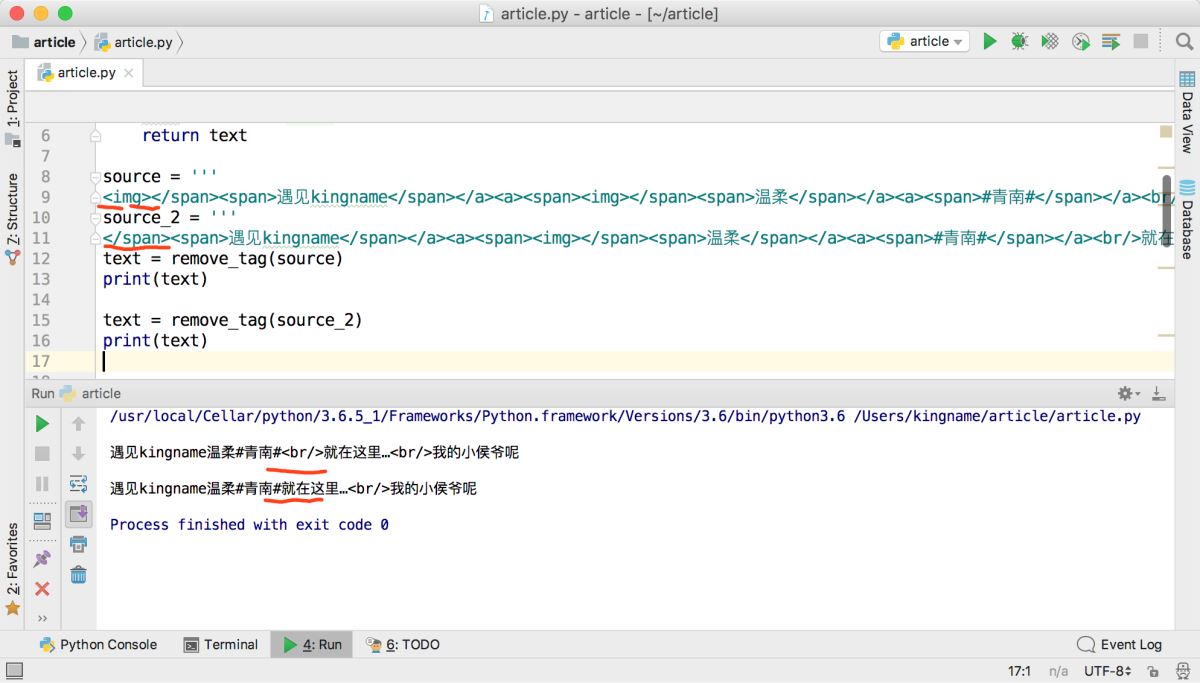
實際上,不僅僅是刪除第一個標簽,前面任意一個標簽刪了都可以減少結果里面的一個標簽。如果刪除前面兩個或以上標簽,那么結果就正常了。
答疑解惑
這個看起來很奇怪的問題,根本原因在re.sub的第4個參數。從函數原型可以看到:
def sub(pattern, repl, string, count=0, flags=0)
第四個參數是count表示替換個數,re.S如果要用,應該作為第五個參數。所以如果把remove_tag函數做一些修改,那么結果就正確了:
def remove_tag(html):
text = re.sub('<.*?>', '', html, flags=re.S)
return text那么問題來了,把re.S放在count的位置,為什么代碼沒有報錯?難道re.S是數字?實際上,如果打印一下就會發現,re.S確實可以作為數字:
>>> import re >>> print(int(re.S)) 16
現在回頭數一數出問題的HTML代碼,發現最后多出來的兩個<br>標簽,剛剛好是第17和18個標簽,而由于count填寫的re.S可以當做16來處理,那么Python就會把前16個標簽替換為空字符串,從而留下最后兩個。
至此問題的原因搞清楚了。
這個問題沒有被及早發現,有以下幾個原因:
被替換的HTML代碼是代碼段,大多數情況下HTML標簽不足16個,所以問題被隱藏。re.S是一個對象,但也是數字,count接收的參數剛好也是數字。在很多編程語言里面,常量都會使用數字,然后用一個有意義的大寫字母來表示。re.S 處理的情況是<div \n> 而不是<div>\n</div>但測試的代碼段標簽都是第二種情況,所以在代碼段里面實際上加不加re.S效果是一樣的。
補充:下面在給大家介紹下正則表達式 re.sub()替換功能
re.sub()替換功能
re.sub是個正則表達式方面的函數,用來實現通過正則表達式,實現比普通字符串的replace更加強大的替換功能。簡單的替換功能可以使用replace()實現。
def main():
text = '123, word!'
text1 = text.replace('123', 'Hello')
print(text1)
if __name__ == '__main__':
main()
# Hello, wold!如果通過re.sub(0函數則可以匹配任意的數字,并將其替換:
import re def main(): content = 'abc124hello46goodbye67shit' list1 = re.findall(r'\d+', content) print(list1) mylist = list(map(int, list1)) print(mylist) print(sum(mylist)) print(re.sub(r'\d+[hg]', 'foo1', content)) print() print(re.sub(r'\d+', '456654', content)) if __name__ == '__main__': main() # ['124', '46', '67'] # [124, 46, 67] # 237 # abcfoo1ellofoo1oodbye67shit # abc456654hello456654goodbye456654shit
感謝各位的閱讀!關于“如何解決正則表達式re.sub替換不完整的問題”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





