溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了JAVA中正則表達式有什么用,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
在Sun的Java JDK 1.40版本中,Java自帶了支持正則表達式的包,本文就拋磚引玉地介紹了如何使用java.util.regex包。
可粗略估計一下,除了偶爾用Linux的外,其他Linu x用戶都會遇到正則表達式。正則表達式是個極端強大工具,而且在字符串模式-匹配和字符串模式-替換方面富有彈性。在Unix世界里,正則表達式幾乎沒有什么限制,可肯定的是,它應用非常之廣泛。
正則表達式的引擎已被許多普通的Unix工具所實現,包括grep,awk,vi和Emacs等。此外,許多使用比較廣泛的腳本語言也支持正則表達式,比如Python,Tcl,JavaScript,以及最著名的Perl。
我很早以前就是個Perl方面的黑客,如果你和我一樣話,你也會非常依賴你手邊的這些強大的text-munging工具。近幾年來,像其他程序開發者一樣,我也越來越關注Java的開發。
Java作為一種開發語言,有許多值得推薦的地方,但是它一直以來沒有自帶對正則表達式的支持。直到最近,借助于第三方的類庫,Java開始支持正則表達式,但這些第三方的類庫都不一致、兼容性差,而且維護代碼起來很糟糕。這個缺點,對我選擇Java作為首要的開發工具來說,一直是個巨大的顧慮之處。
你可以想象,當我知道Sun的Java JDK 1.40版本包含了java.util.regex(一個完全開放、自帶的正則表達式包)時,是多么的高興!很搞笑的說,我花好些時間去挖掘這個被隱藏起來的寶石。我非常驚奇的是,Java這樣的一個很大改進(自帶了java.util.regex包)為什么不多公開一點呢?!
最近,Java雙腳都跳進了正則表達式的世界。java.util.regex包在支持正則表達也有它的過人之處,另外Java也提供詳細的相關說明文檔。使得朦朦朧朧的regex神秘景象也慢慢被撥開。有一些正則表達式的構成(可能最顯著的是,在于糅合了字符類庫)在Perl都找不到。
在regex包中,包括了兩個類,Pattern(模式類)和Matcher(匹配器類)。Pattern類是用來表達和陳述所要搜索模式的對象,Matcher類是真正影響搜索的對象。另加一個新的例外類,PatternSyntaxException,當遇到不合法的搜索模式時,會拋出例外。
即使對正則表達式很熟悉,你會發現,通過java使用正則表達式也相當簡單。要說明的一點是,對那些被Perl的單行匹配所寵壞的Perl狂熱愛好者來說,在使用java的regex包進行替換操作時,會比他們所以前常用的方法費事些。
本文的局限之處,它不是一篇正則表達式用法的完全教程。如果讀者要對正則表達進一步了解的話,推薦閱讀Jeffrey Frieldl的Mastering Regular Expressions,該書由O'Reilly出版社出版。我下面就舉一些例子來教讀者如何使用正則表達式,以及如何更簡單地去使用它。
設計一個簡單的表達式來匹配任何電話號碼數字可能是比較復雜的事情,原因在于電話號碼格式有很多種情況。所有必須選擇一個比較有效的模式。比如:(212) 555-1212, 212-555-1212和212 555 1212,某些人會認為它們都是等價的。
首先讓我們構成一個正則表達式。為簡單起見,先構成一個正則表達式來識別下面格式的電話號碼數字:(nnn)nnn-nnnn。
第一步,創建一個pattern對象來匹配上面的子字符串。一旦程序運行后,如果需要的話,可以讓這個對象一般化。匹配上面格式的正則表達可以這樣構成:(/d{3})/s/d{3}-/d{4},其中/d單字符類型用來匹配從0到9的任何數字,另外{3}重復符號,是個簡便的記號,用來表示有3個連續的數字位,也等效于(/d/d/d)。/s也另外一個比較有用的單字符類型,用來匹配空格,比如Space鍵,tab鍵和換行符。
是不是很簡單?但是,如果把這個正則表達式的模式用在java程序中,還要做兩件事。對java的解釋器來說,在反斜線字符(/)前的字符有特殊的含義。在java中,與regex有關的包,并不都能理解和識別反斜線字符(/),盡管可以試試看。但為避免這一點,即為了讓反斜線字符(/)在模式對象中被完全地傳遞,應該用雙反斜線字符(/)。此外圓括號在正則表達中兩層含義,如果想讓它解釋為字面上意思(即圓括號),也需要在它前面用雙反斜線字符(/)。也就是像下面的一樣:
//(//d{3}//)//s//d{3}-//d{4}
現在介紹怎樣在java代碼中實現剛才所講的正則表達式。要記住的事,在用正則表達式的包時,在你所定義的類前需要包含該包,也就是這樣的一行:
import java.util.regex.*;
下面的一段代碼實現的功能是,從一個文本文件逐行讀入,并逐行搜索電話號碼數字,一旦找到所匹配的,然后輸出在控制臺。
BufferedReader in;
Pattern pattern = Pattern.compile("//(//d{3}//)//s//d{3}-//d{4}");
in = new BufferedReader(new FileReader("phone"));
String s;
while ((s = in.readLine()) != null)
{
Matcher matcher = pattern.matcher(s);
if (matcher.find())
{
System.out.println(matcher.group());
}
}
in.close();對那些熟悉用Python或Javascript來實現正則表達式的人來說,這段代碼很平常。在Python和Javascript這些語言中,或者其他的語言,這些正則表達式一旦明確地編譯過后,你想用到哪里都可以。與Perl的單步匹配相比,看起來多多做了些工作,但這并不很費事。
find()方法,就像你所想象的,用來搜索與正則表達式相匹配的任何目標字符串,group()方法,用來返回包含了所匹配文本的字符串。應注意的是,上面的代碼,僅用在每行只能含有一個匹配的電話號碼數字字符串時。可以肯定的說,java的正則表達式包能用在一行含有多個匹配目標時的搜索。本文的原意在于舉一些簡單的例子來激起讀者進一步去學習java自帶的正則表達式包,所以對此就沒有進行深入的探討。
這相當漂亮吧! 但是很遺憾的是,這僅是個電話號碼匹配器。很明顯,還有兩點可以改進。如果在電話號碼的開頭,即區位號和本地號碼之間可能會有空格。我們也可匹配這些情況,則通過在正則表達式中加入/s?來實現,其中?元字符表示在模式可能有0或1個空格符。
第二點是,在本地號碼位的前三位和后四位數字間有可能是空格符,而不是連字號,更有勝者,或根本就沒有分隔符,就是7位數字連在一起。對這幾種情況,我們可以用(-|)?來解決。這個結構的正則表達式就是轉換器,它能匹配上面所說的幾種情況。在()能含有管道符|時,它能匹配是否含有空格符或連字符,而尾部的?元字符表示是否根本沒有分隔符的情況。
最后,區位號也可能沒有包含在圓括號內,對此可以簡單地在圓括號后附上?元字符,但這不是一個很好的解決方法。因為它也包含了不配對的圓括號,比如"(555" 或 "555)"。相反,我們可以通過另一種轉換器來強迫讓電話號碼是否帶有有圓括號:(/(/d{3}/)|/d{3})。如果我們把上面代碼中的正則表達式用這些改進后的來替換的話,上面的代碼就成了一個非常有用的電話號碼數字匹配器:
Pattern pattern =
Pattern.compile("(//(//d{3}//)|//d{3})//s?//d{3}(-|)?//d{4}");
可以確定的是,你可以自己試著進一步改進上面的代碼。
現在看看第二個例子,它是從Friedl的中改編過來的。其功能是用來檢查文本文件中是否有重復的單詞,這在印刷排版中會經常遇到,同樣也是個語法檢查器的問題。
匹配單詞,像其他的一樣,也可以通過好幾種的正則表達式來完成。可能最直接的是/b/w+/b,其優點在于只需用少量的regex元字符。其中/w元字符用來匹配從字母a到u的任何字符。+元字符表示匹配匹配一次或多次字符,/b元字符是用來說明匹配單詞的邊界,它可以是空格或任何一種不同的標點符號(包括逗號,句號等)。
現在,我們怎樣來檢查一個給定的單詞是否被重復了三次?為完成這個任務,需充分利用正則表達式中的所熟知的向后掃描。如前面提到的,圓括號在正則表達式中有幾種不同的用法,一個就是能提供組合類型,組合類型用來保存所匹配的結果或部分匹配的結果(以便后面能用到),即使遇到有相同的模式。在同樣的正則表達中,可能(也通常期望)不止有一個組合類型。在第n個組合類型中匹配結果可以通過向后掃描來獲取到。向后掃描使得搜索重復的單詞非常簡單:/b(/w+)/s+/1/b。
圓括號形成了一個組合類型,在這個正則表示中它是第一組合類型(也是僅有的一個)。向后掃描/1,指的是任何被/w+所匹配的單詞。我們的正則表達式因此能匹配這樣的單詞,它有一個或多個空格符,后面還跟有一個與此相同的單詞。注意的是,尾部的定位類型(/b)必不可少,它可以防止發生錯誤。如果我們想匹配"Paris in the the spring",而不是匹配"Java's regex package is the theme of this article"。根據java現在的格式,則上面的正則表達式就是:Pattern pattern =Pattern.compile("//b(//w+)//s+//1//b");
最后進一步的修改是讓我們的匹配器對大小寫敏感。比如,下面的情況:"The the theme of this article is the Java's regex package.",這一點在regex中能非常簡單地實現,即通過使用在Pattern類中預定義的靜態標志CASE_INSENSITIVE :
Pattern pattern =Pattern.compile("//b(//w+)//s+//1//b",
Pattern.CASE_INSENSITIVE);
有關正則表達式的話題是非常豐富,而且復雜的,用Java來實現也非常廣泛,則需要對regex包進行的徹底研究,我們在這里所講的只是冰山一角。即使你對正則表達式比較陌生,使用regex包后會很快發現它強大功能和可伸縮性。如果你是個來自Perl或其他語言王國的老練的正則表達式的黑客,使用過regex包后,你將會安心地投入到java的世界,而放棄其他的工具,并把java的regex包看成是手邊必備的利器。
CharSequence
JDK 1.4定義了一個新的接口,叫CharSequence。它提供了String和StringBuffer這兩個類的字符序列的抽象:
CharSequence {
charAt( i);
length();
subSequence( start, end);
toString();
}為了實現這個新的CharSequence接口,String,StringBuffer以及CharBuffer都作了修改。很多正則表達式的操作都要拿CharSequence作參數。
Pattern和Matcher
先給一個例子。下面這段程序可以測試正則表達式是否匹配字符串。第一個參數是要匹配的字符串,后面是正則表達式。正則表達式可以有多個。在Unix/Linux環境下,命令行下的正則表達式還必須用引號。
java.util.regex.*;
TestRegularExpression {
main(String[] args) {
(args.length < 2) {
System.out.println( +
+
);
System.exit(0);
}
System.out.println(/);
( i = 1; i < args.length; i++) {
System.out.println(
/);
Pattern p = Pattern.compile(args[i]);
Matcher m = p.matcher(args[0]);
(m.find()) {
System.out.println(" + m.group() +
at positions " +
m.start() + + (m.end() - 1));
}
}
}
}Java的正則表達式是由java.util.regex的Pattern和Matcher類實現的。Pattern對象表示經編譯的正則表達式。靜態的compile( )方法負責將表示正則表達式的字符串編譯成Pattern對象。正如上述例程所示的,只要給Pattern的matcher( )方法送一個字符串就能獲取一個Matcher對象。此外,Pattern還有一個能快速判斷能否在input里面找到regex的
matches(?regex, ?input)
以及能返回String數組的split( )方法,它能用regex把字符串分割開來。
只要給Pattern.matcher( )方法傳一個字符串就能獲得Matcher對象了。接下來就能用Matcher的方法來查詢匹配的結果了。
matches()
lookingAt()
find()
find( start)
matches( )的前提是Pattern匹配整個字符串,而lookingAt( )的意思是Pattern匹配字符串的開頭。
find( )
Matcher.find( )的功能是發現CharSequence里的,與pattern相匹配的多個字符序列。例如:
java.util.regex.*;
com.bruceeckel.simpletest.*;
java.util.*;
FindDemo {
Test monitor = Test();
main(String[] args) {
Matcher m = Pattern.compile()
.matcher();
(m.find())
System.out.println(m.group());
i = 0;
(m.find(i)) {
System.out.print(m.group() + );
i++;
}
monitor.expect( String[] {
,
,
,
,
,
,
,
,
+
+
});
}
}"//w+"的意思是"一個或多個單詞字符",因此它會將字符串直接分解成單詞。find( )像一個迭代器,從頭到尾掃描一遍字符串。第二個find( )是帶int參數的,正如你所看到的,它會告訴方法從哪里開始找——即從參數位置開始查找。
Groups
Group是指里用括號括起來的,能被后面的表達式調用的正則表達式。Group 0 表示整個表達式,group 1表示第一個被括起來的group,以此類推。所以;
A(B(C))D
里面有三個group:group 0是ABCD, group 1是BC,group 2是C。
你可以用下述Matcher方法來使用group:
public int groupCount( )返回matcher對象中的group的數目。不包括group0。
public String group( ) 返回上次匹配操作(比方說find( ))的group 0(整個匹配)
public String group(int i)返回上次匹配操作的某個group。如果匹配成功,但是沒能找到group,則返回null。
public int start(int group)返回上次匹配所找到的,group的開始位置。
public int end(int group)返回上次匹配所找到的,group的結束位置,最后一個字符的下標加一。
java.util.regex.*;
com.bruceeckel.simpletest.*;
Groups {
Test monitor = Test();
String poem =
+
+
+
+
+
+
+
;
main(String[] args) {
Matcher m =
Pattern.compile()
.matcher(poem);
(m.find()) {
( j = 0; j <= m.groupCount(); j++)
System.out.print( + m.group(j) + );
System.out.println();
}
monitor.expect( String[]{
+
,
,
+
,
+
,
+
,
+
,
,
+
});
}
}這首詩是Through the Looking Glass的,Lewis Carroll的"Jabberwocky"的第一部分。可以看到這個正則表達式里有很多用括號括起來的group,它是由任意多個連續的非空字符('/S+')和任意多個連續的空格字符('/s+')所組成的,其最終目的是要捕獲每行的最后三個單詞;'$'表示一行的結尾。但是'$'通常表示整個字符串的結尾,所以這里要明確地告訴正則表達式注意換行符。這一點是由'(?m)'標志完成的(模式標志會過一會講解)。
start( )和end( )
如果匹配成功,start( )會返回此次匹配的開始位置,end( )會返回此次匹配的結束位置,即最后一個字符的下標加一。如果之前的匹配不成功(或者沒匹配),那么無論是調用start( )還是end( ),都會引發一個IllegalStateException。下面這段程序還演示了matches( )和lookingAt( ):
java.util.regex.*;
com.bruceeckel.simpletest.*;
StartEnd {
Test monitor = Test();
main(String[] args) {
String[] input = String[] {
,
,
};
Pattern
p1 = Pattern.compile(),
p2 = Pattern.compile();
( i = 0; i < input.length; i++) {
System.out.println( + i + + input[i]);
Matcher
m1 = p1.matcher(input[i]),
m2 = p2.matcher(input[i]);
(m1.find())
System.out.println( + m1.group() +
+ m1.start() + + m1.end());
(m2.find())
System.out.println( + m2.group() +
+ m2.start() + + m2.end());
(m1.lookingAt())
System.out.println(
+ m1.start() + + m1.end());
(m2.lookingAt())
System.out.println(
+ m2.start() + + m2.end());
(m1.matches())
System.out.println(
+ m1.start() + + m1.end());
(m2.matches())
System.out.println(
+ m2.start() + + m2.end());
}
monitor.expect( String[] {
,
,
,
+
,
,
,
+
,
,
,
,
,
,
,
,
,
+
,
,
});
}
}注意,只要字符串里有這個模式,find( )就能把它給找出來,但是lookingAt( )和matches( ),只有在字符串與正則表達式一開始就相匹配的情況下才能返回true。matches( )成功的前提是正則表達式與字符串完全匹配,而lookingAt( )成功的前提是,字符串的開始部分與正則表達式相匹配。
匹配的模式(Pattern flags)
compile( )方法還有一個版本,它需要一個控制正則表達式的匹配行為的參數:
Pattern Pattern.compile(String regex, flag)
flag的取值范圍如下:
| 編譯標志 | 效果 |
|---|---|
| Pattern.CANON_EQ | 當且僅當兩個字符的"正規分解(canonical decomposition)"都完全相同的情況下,才認定匹配。比如用了這個標志之后,表達式"a/u030A"會匹配"?"。默認情況下,不考慮"規范相等性(canonical equivalence)"。 |
| Pattern.CASE_INSENSITIVE (?i) | 默認情況下,大小寫不明感的匹配只適用于US-ASCII字符集。這個標志能讓表達式忽略大小寫進行匹配。要想對Unicode字符進行大小不明感的匹配,只要將UNICODE_CASE與這個標志合起來就行了。 |
| Pattern.COMMENTS (?x) | 在這種模式下,匹配時會忽略(正則表達式里的)空格字符(注:不是指表達式里的"//s",而是指表達式里的空格,tab,回車之類)。注釋從#開始,一直到這行結束。可以通過嵌入式的標志來啟用Unix行模式。 |
| Pattern.DOTALL (?s) | 在這種模式下,表達式'.'可以匹配任意字符,包括表示一行的結束符。默認情況下,表達式'.'不匹配行的結束符。 |
| Pattern.MULTILINE (?m) | 在這種模式下,'^'和'$'分別匹配一行的開始和結束。此外,'^'仍然匹配字符串的開始,'$'也匹配字符串的結束。默認情況下,這兩個表達式僅僅匹配字符串的開始和結束。 |
| Pattern.UNICODE_CASE (?u) | 在這個模式下,如果你還啟用了CASE_INSENSITIVE標志,那么它會對Unicode字符進行大小寫不明感的匹配。默認情況下,大小寫不明感的匹配只適用于US-ASCII字符集。 |
| Pattern.UNIX_LINES (?d) | 在這個模式下,只有'/n'才被認作一行的中止,并且與'.','^',以及'$'進行匹配。 |
在這些標志里面,Pattern.CASE_INSENSITIVE,Pattern.MULTILINE,以及Pattern.COMMENTS是最有用的(其中Pattern.COMMENTS還能幫我們把思路理清楚,并且/或者做文檔)。注意,你可以用在表達式里插記號的方式來啟用絕大多數的模式。這些記號就在上面那張表的各個標志的下面。你希望模式從哪里開始啟動,就在哪里插記號。
可以用"OR" ('|')運算符把這些標志合使用:
java.util.regex.*;
com.bruceeckel.simpletest.*;
ReFlags {
Test monitor = Test();
main(String[] args) {
Pattern p = Pattern.compile(,
Pattern.CASE_INSENSITIVE | Pattern.MULTILINE);
Matcher m = p.matcher(
+
+
);
(m.find())
System.out.println(m.group());
monitor.expect( String[] {
,
,
});
}
}這樣創建出來的正則表達式就能匹配以"java","Java","JAVA"...開頭的字符串了。此外,如果字符串分好幾行,那它還會對每一行做匹配(匹配始于字符序列的開始,終于字符序列當中的行結束符)。注意,group( )方法僅返回匹配的部分。
split( )
所謂分割是指將以正則表達式為界,將字符串分割成String數組。
String[] split(CharSequence charseq)
String[] split(CharSequence charseq, limit)
這是一種既快又方便地將文本根據一些常見的邊界標志分割開來的方法。
java.util.regex.*;
com.bruceeckel.simpletest.*;
java.util.*;
SplitDemo {
Test monitor = Test();
main(String[] args) {
String input =
;
System.out.println(Arrays.asList(
Pattern.compile().split(input)));
System.out.println(Arrays.asList(
Pattern.compile().split(input, 3)));
System.out.println(Arrays.asList(
.split()));
monitor.expect( String[] {
,
,
});
}
}第二個split( )會限定分割的次數。
正則表達式是如此重要,以至于有些功能被加進了String類,其中包括split( )(已經看到了),matches( ),replaceFirst( )以及replaceAll( )。這些方法的功能同Pattern和Matcher的相同。
替換操作
正則表達式在替換文本方面特別在行。下面就是一些方法:
replaceFirst(String replacement)將字符串里,第一個與模式相匹配的子串替換成replacement。
replaceAll(String replacement),將輸入字符串里所有與模式相匹配的子串全部替換成replacement。
appendReplacement(StringBuffer sbuf, String replacement)對sbuf進行逐次替換,而不是像replaceFirst( )或replaceAll( )那樣,只替換第一個或全部子串。這是個非常重要的方法,因為它可以調用方法來生成replacement(replaceFirst( )和replaceAll( )只允許用固定的字符串來充當replacement)。有了這個方法,你就可以編程區分group,從而實現更強大的替換功能。
調用完appendReplacement( )之后,為了把剩余的字符串拷貝回去,必須調用appendTail(StringBuffer sbuf, String replacement)。
下面我們來演示一下怎樣使用這些替換方法。說明一下,這段程序所處理的字符串是它自己開頭部分的注釋,是用正則表達式提取出來并加以處理之后再傳給替換方法的。
java.util.regex.*;
java.io.*;
com.bruceeckel.util.*;
com.bruceeckel.simpletest.*;
TheReplacements {
Test monitor = Test();
main(String[] args) Exception {
String s = TextFile.read();
Matcher mInput =
Pattern.compile(, Pattern.DOTALL)
.matcher(s);
(mInput.find())
s = mInput.group(1);
s = s.replaceAll(, );
s = s.replaceAll(, );
System.out.println(s);
s = s.replaceFirst(, );
StringBuffer sbuf = StringBuffer();
Pattern p = Pattern.compile();
Matcher m = p.matcher(s);
(m.find())
m.appendReplacement(sbuf, m.group().toUpperCase());
m.appendTail(sbuf);
System.out.println(sbuf);
monitor.expect( String[]{
,
,
,
,
,
,
,
,
,
});
}
}用TextFile.read( )方法來打開和讀取文件。mInput的功能是匹配'/*!' 和 '!*/' 之間的文本(注意一下分組用的括號)。接下來,我們將所有兩個以上的連續空格全都替換成一個,并且將各行開頭的空格全都去掉(為了讓這個正則表達式能對所有的行,而不僅僅是第一行起作用,必須啟用多行模式)。這兩個操作都用了String的replaceAll( )(這里用它更方便)。注意,由于每個替換只做一次,因此除了預編譯Pattern之外,程序沒有額外的開銷。
replaceFirst( )只替換第一個子串。此外,replaceFirst( )和replaceAll( )只能用常量(literal)來替換,所以如果每次替換的時候還要進行一些操作的話,它們是無能為力的。碰到這種情況,得用appendReplacement( ),它能在進行替換的時候想寫多少代碼就寫多少。在上面那段程序里,創建sbuf的過程就是選group做處理,也就是用正則表達式把元音字母找出來,然后換成大寫的過程。通常你得在完成全部的替換之后才調用appendTail( ),但是如果要模仿replaceFirst( )(或"replace n")的效果,你也可以只替換一次就調用appendTail( )。它會把剩下的東西全都放進sbuf。
你還可以在appendReplacement( )的replacement參數里用"$g"引用已捕獲的group,其中'g' 表示group的號碼。不過這是為一些比較簡單的操作準備的,因而其效果無法與上述程序相比。
reset( )
此外,還可以用reset( )方法給現有的Matcher對象配上個新的CharSequence。
java.util.regex.*;
java.io.*;
com.bruceeckel.simpletest.*;
Resetting {
Test monitor = Test();
main(String[] args) Exception {
Matcher m = Pattern.compile()
.matcher();
(m.find())
System.out.println(m.group());
m.reset();
(m.find())
System.out.println(m.group());
monitor.expect( String[]{
,
,
,
,
,
});
}
}如果不給參數,reset( )會把Matcher設到當前字符串的開始處。
如果你曾經用過Perl或任何其他內建正則表達式支持的語言,你一定知道用正則表達式處理文本和匹配模式是多么簡單。如果你不熟悉這個術語,那么“正則表達式”(Regular Expression)就是一個字符構成的串,它定義了一個用來搜索匹配字符串的模式。
許多語言,包括Perl、PHP、Python、JavaScript和JScript,都支持用正則表達式處理文本,一些文本編輯器用正則表達式實現高級“搜索-替換”功能。那么Java又怎樣呢?本文寫作時,一個包含了用正則表達式進行文本處理的Java規范需求(Specification Request)已經得到認可,你可以期待在JDK的下一版本中看到它。
然而,如果現在就需要使用正則表達式,又該怎么辦呢?你可以從Apache.org下載源代碼開放的Jakarta-ORO庫。本文接下來的內容先簡要地介紹正則表達式的入門知識,然后以Jakarta-ORO API為例介紹如何使用正則表達式。
一、正則表達式基礎知識
我們先從簡單的開始。假設你要搜索一個包含字符“cat”的字符串,搜索用的正則表達式就是“cat”。如果搜索對大小寫不敏感,單詞“catalog”、“Catherine”、“sophisticated”都可以匹配。也就是說:

1.1 句點符號
假設你在玩英文拼字游戲,想要找出三個字母的單詞,而且這些單詞必須以“t”字母開頭,以“n”字母結束。另外,假設有一本英文字典,你可以用正則表達式搜索它的全部內容。要構造出這個正則表達式,你可以使用一個通配符——句點符號“.”。這樣,完整的表達式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,還匹配“t#n”、“tpn”甚至“t n”,還有其他許多無意義的組合。這是因為句點符號匹配所有字符,包括空格、Tab字符甚至換行符:
 |
1.2 方括號符號
為了解決句點符號匹配范圍過于廣泛這一問題,你可以在方括號(“[]”)里面指定看來有意義的字符。此時,只有方括號里面指定的字符才參與匹配。也就是說,正則表達式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因為在方括號之內你只能匹配單個字符:

1.3 “或”符號
如果除了上面匹配的所有單詞之外,你還想要匹配“toon”,那么,你可以使用“|”操作符。“|”操作符的基本意義就是“或”運算。要匹配“toon”,使用“t(a|e|i|o|oo)n”正則表達式。這里不能使用方擴號,因為方括號只允許匹配單個字符;這里必須使用圓括號“()”。圓括號還可以用來分組,具體請參見后面介紹。

1.4 表示匹配次數的符號
表一顯示了表示匹配次數的符號,這些符號用來確定緊靠該符號左邊的符號出現的次數:
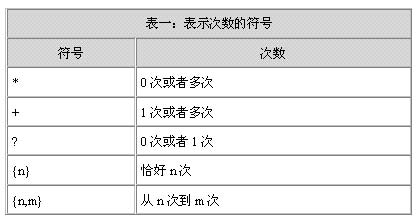
假設我們要在文本文件中搜索美國的社會安全號碼。這個號碼的格式是999-99-9999。用來匹配它的正則表達式如圖一所示。在正則表達式中,連字符(“-”)有著特殊的意義,它表示一個范圍,比如從0到9。因此,匹配社會安全號碼中的連字符號時,它的前面要加上一個轉義字符“/”。

圖一:匹配所有123-12-1234形式的社會安全號碼
假設進行搜索的時候,你希望連字符號可以出現,也可以不出現——即,999-99-9999和999999999都屬于正確的格式。這時,你可以在連字符號后面加上“?”數量限定符號,如圖二所示:

圖二:匹配所有123-12-1234和123121234形式的社會安全號碼
下面我們再來看另外一個例子。美國汽車牌照的一種格式是四個數字加上二個字母。它的正則表達式前面是數字部分“[0-9]{4}”,再加上字母部分“[A-Z]{2}”。圖三顯示了完整的正則表達式。
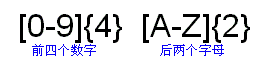
圖三:匹配典型的美國汽車牌照號碼,如8836KV
1.5 “否”符號
“^”符號稱為“否”符號。如果用在方括號內,“^”表示不想要匹配的字符。例如,圖四的正則表達式匹配所有單詞,但以“X”字母開頭的單詞除外。

圖四:匹配所有單詞,但“X”開頭的除外
1.6 圓括號和空白符號
假設要從格式為“June 26, 1951”的生日日期中提取出月份部分,用來匹配該日期的正則表達式可以如圖五所示:

圖五:匹配所有Moth DD,YYYY格式的日期
新出現的“/s”符號是空白符號,匹配所有的空白字符,包括Tab字符。如果字符串正確匹配,接下來如何提取出月份部分呢?只需在月份周圍加上一個圓括號創建一個組,然后用ORO API(本文后面詳細討論)提取出它的值。修改后的正則表達式如圖六所示:

圖六:匹配所有Month DD,YYYY格式的日期,定義月份值為第一個組
1.7 其它符號
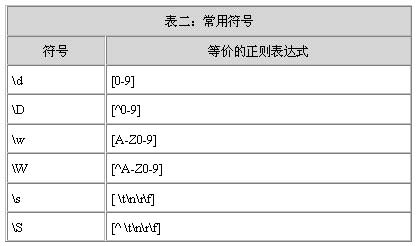
為簡便起見,你可以使用一些為常見正則表達式創建的快捷符號。如表二所示:
表二:常用符號
例如,在前面社會安全號碼的例子中,所有出現“[0-9]”的地方我們都可以使用“/d”。修改后的正則表達式如圖七所示:

圖七:匹配所有123-12-1234格式的社會安全號碼
二、Jakarta-ORO庫
有許多源代碼開放的正則表達式庫可供Java程序員使用,而且它們中的許多支持Perl 5兼容的正則表達式語法。我在這里選用的是Jakarta-ORO正則表達式庫,它是最全面的正則表達式API之一,而且它與Perl 5正則表達式完全兼容。另外,它也是優化得最好的API之一。
Jakarta-ORO庫以前叫做OROMatcher,Daniel Savarese大方地把它贈送給了Jakarta Project。你可以按照本文最后參考資源的說明下載它。
我首先將簡要介紹使用Jakarta-ORO庫時你必須創建和訪問的對象,然后介紹如何使用Jakarta-ORO API。
▲ PatternCompiler對象
首先,創建一個Perl5Compiler類的實例,并把它賦值給PatternCompiler接口對象。Perl5Compiler是PatternCompiler接口的一個實現,允許你把正則表達式編譯成用來匹配的Pattern對象。

▲ Pattern對象
要把正則表達式編譯成Pattern對象,調用compiler對象的compile()方法,并在調用參數中指定正則表達式。例如,你可以按照下面這種方式編譯正則表達式“t[aeio]n”:

默認情況下,編譯器創建一個大小寫敏感的模式(pattern)。因此,上面代碼編譯得到的模式只匹配“tin”、“tan”、 “ten”和“ton”,但不匹配“Tin”和“taN”。要創建一個大小寫不敏感的模式,你應該在調用編譯器的時候指定一個額外的參數:

創建好Pattern對象之后,你就可以通過PatternMatcher類用該Pattern對象進行模式匹配。
▲ PatternMatcher對象
PatternMatcher對象根據Pattern對象和字符串進行匹配檢查。你要實例化一個Perl5Matcher類并把結果賦值給PatternMatcher接口。Perl5Matcher類是PatternMatcher接口的一個實現,它根據Perl 5正則表達式語法進行模式匹配:

使用PatternMatcher對象,你可以用多個方法進行匹配操作,這些方法的第一個參數都是需要根據正則表達式進行匹配的字符串:
· boolean matches(String input, Pattern pattern):當輸入字符串和正則表達式要精確匹配時使用。換句話說,正則表達式必須完整地描述輸入字符串。
· boolean matchesPrefix(String input, Pattern pattern):當正則表達式匹配輸入字符串起始部分時使用。
· boolean contains(String input, Pattern pattern):當正則表達式要匹配輸入字符串的一部分時使用(即,它必須是一個子串)。
另外,在上面三個方法調用中,你還可以用PatternMatcherInput對象作為參數替代String對象;這時,你可以從字符串中最后一次匹配的位置開始繼續進行匹配。當字符串可能有多個子串匹配給定的正則表達式時,用PatternMatcherInput對象作為參數就很有用了。用PatternMatcherInput對象作為參數替代String時,上述三個方法的語法如下:
· boolean matches(PatternMatcherInput input, Pattern pattern)
· boolean matchesPrefix(PatternMatcherInput input, Pattern pattern)
· boolean contains(PatternMatcherInput input, Pattern pattern)
三、應用實例
下面我們來看看Jakarta-ORO庫的一些應用實例。
3.1 日志文件處理
任務:分析一個Web服務器日志文件,確定每一個用戶花在網站上的時間。在典型的BEA WebLogic日志文件中,日志記錄的格式如下:

分析這個日志記錄,可以發現,要從這個日志文件提取的內容有兩項:IP地址和頁面訪問時間。你可以用分組符號(圓括號)從日志記錄提取出IP地址和時間標記。
首先我們來看看IP地址。IP地址有4個字節構成,每一個字節的值在0到255之間,各個字節通過一個句點分隔。因此,IP地址中的每一個字節有至少一個、最多三個數字。圖八顯示了為IP地址編寫的正則表達式:

圖八:匹配IP地址
IP地址中的句點字符必須進行轉義處理(前面加上“/”),因為IP地址中的句點具有它本來的含義,而不是采用正則表達式語法中的特殊含義。句點在正則表達式中的特殊含義本文前面已經介紹。
日志記錄的時間部分由一對方括號包圍。你可以按照如下思路提取出方括號里面的所有內容:首先搜索起始方括號字符(“[”),提取出所有不超過結束方括號字符(“]”)的內容,向前尋找直至找到結束方括號字符。圖九顯示了這部分的正則表達式。

圖九:匹配至少一個字符,直至找到“]”
現在,把上述兩個正則表達式加上分組符號(圓括號)后合并成單個表達式,這樣就可以從日志記錄提取出IP地址和時間。注意,為了匹配“- -”(但不提取它),正則表達式中間加入了“/s-/s-/s”。完整的正則表達式如圖十所示。
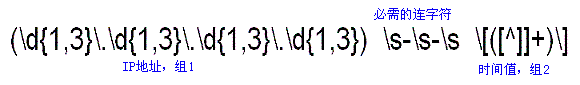
圖十:匹配IP地址和時間標記
現在正則表達式已經編寫完畢,接下來可以編寫使用正則表達式庫的Java代碼了。
為使用Jakarta-ORO庫,首先創建正則表達式字符串和待分析的日志記錄字符串:
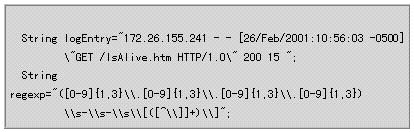
這里使用的正則表達式與圖十的正則表達式差不多完全相同,但有一點例外:在Java中,你必須對每一個向前的斜杠(“/”)進行轉義處理。圖十不是Java的表示形式,所以我們要在每個“/”前面加上一個“/”以免出現編譯錯誤。遺憾的是,轉義處理過程很容易出現錯誤,所以應該小心謹慎。你可以首先輸入未經轉義處理的正則表達式,然后從左到右依次把每一個“/”替換成“//”。如果要復檢,你可以試著把它輸出到屏幕上。
初始化字符串之后,實例化PatternCompiler對象,用PatternCompiler編譯正則表達式創建一個Pattern對象:

現在,創建PatternMatcher對象,調用PatternMatcher接口的contain()方法檢查匹配情況:

接下來,利用PatternMatcher接口返回的MatchResult對象,輸出匹配的組。由于logEntry字符串包含匹配的內容,你可以看到類如下面的輸出:

3.2 HTML處理實例一
下面一個任務是分析HTML頁面內FONT標記的所有屬性。HTML頁面內典型的FONT標記如下所示:

程序將按照如下形式,輸出每一個FONT標記的屬性:

在這種情況下,我建議你使用兩個正則表達式。第一個如圖十一所示,它從字體標記提取出“"face="Arial, Serif" size="+2" color="red"”。

圖十一:匹配FONT標記的所有屬性
第二個正則表達式如圖十二所示,它把各個屬性分割成名字-值對。

圖十二:匹配單個屬性,并把它分割成名字-值對
分割結果為:

現在我們來看看完成這個任務的Java代碼。首先創建兩個正則表達式字符串,用Perl5Compiler把它們編譯成Pattern對象。編譯正則表達式的時候,指定Perl5Compiler.CASE_INSENSITIVE_MASK選項,使得匹配操作不區分大小寫。
接下來,創建一個執行匹配操作的Perl5Matcher對象。

假設有一個String類型的變量html,它代表了HTML文件中的一行內容。如果html字符串包含FONT標記,匹配器將返回true。此時,你可以用匹配器對象返回的MatchResult對象獲得第一個組,它包含了FONT的所有屬性:

接下來創建一個PatternMatcherInput對象。這個對象允許你從最后一次匹配的位置開始繼續進行匹配操作,因此,它很適合于提取FONT標記內屬性的名字-值對。創建PatternMatcherInput對象,以參數形式傳入待匹配的字符串。然后,用匹配器實例提取出每一個FONT的屬性。這通過指定PatternMatcherInput對象(而不是字符串對象)為參數,反復地調用PatternMatcher對象的contains()方法完成。PatternMatcherInput對象之中的每一次迭代將把它內部的指針向前移動,下一次檢測將從前一次匹配位置的后面開始。
本例的輸出結果如下:

3.3 HTML處理實例二
下面我們來看看另一個處理HTML的例子。這一次,我們假定Web服務器從widgets.acme.com移到了newserver.acme.com。現在你要修改一些頁面中的鏈接:

執行這個搜索的正則表達式如圖十三所示:

圖十三:匹配修改前的鏈接
如果能夠匹配這個正則表達式,你可以用下面的內容替換圖十三的鏈接:

注意#字符的后面加上了$1。Perl正則表達式語法用$1、$2等表示已經匹配且提取出來的組。圖十三的表達式把所有作為一個組匹配和提取出來的內容附加到鏈接的后面。
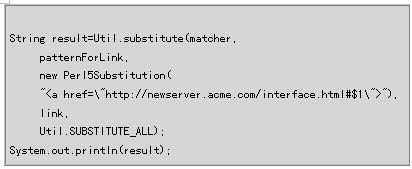
現在,返回Java。就象前面我們所做的那樣,你必須創建測試字符串,創建把正則表達式編譯到Pattern對象所必需的對象,以及創建一個PatternMatcher對像

接下來,用com.oroinc.text.regex包Util類的substitute()靜態方法進行替換,輸出結果字符串:
Util.substitute()方法的語法如下:
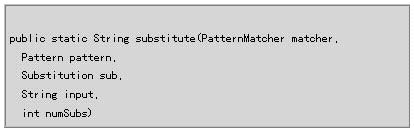
這個調用的前兩個參數是以前創建的PatternMatcher和Pattern對象。第三個參數是一個Substiution對象,它決定了替換操作如何進行。本例使用的是Perl5Substitution對象,它能夠進行Perl5風格的替換。第四個參數是想要進行替換操作的字符串,最后一個參數允許指定是否替換模式的所有匹配子串(Util.SUBSTITUTE_ALL),或只替換指定的次數。
【結束語】在這篇文章中,我為你介紹了正則表達式的強大功能。只要正確運用,正則表達式能夠在字符串提取和文本修改中起到很大的作用。另外,我還介紹了如何在Java程序中通過Jakarta-ORO庫利用正則表達式。至于最終采用老式的字符串處理方式(使用StringTokenizer,charAt,和substring),還是采用正則表達式,這就有待你自己決定了。
Jakarta-ORO篇
由于工作的需要,本人經常要面對大量的文字電子資料的整理工作,因此曾對在JAVA中正則表達式的應用有所關注,并對其有一定的了解,希望通過本文與同行進行有關方面的心得交流。
正則表達式:
正則表達式是一種可以用于模式匹配和替換的強有力的工具,一個正則表達式就是由普通的字符(例如字符 a 到 z)以及特殊字符(稱為元字符)組成的文字模式,它描述在查找文字主體時待匹配的一個或多個字符串。正則表達式作為一個模板,將某個字符模式與所搜索的字符串進行匹配。
正則表達式在字符數據處理中起著非常重要的作用,我們可以用正則表達式完成大部分的數據分析處理工作,如:判斷一個串是否是數字、是否是有效的Email地址,從海量的文字資料中提取有價值的數據等等,如果不使用正則表達式,那么實現的程序可能會很長,并且容易出錯。對這點本人深有體會,面對大量工具書電子檔資料的整理工作,如果不懂得應用正則表達式來處理,那么將是很痛苦的一件事情,反之則將可以輕松地完成,獲得事半功倍的效果。
由于本文目的是要介紹如何在JAVA里運用正則表達式,因此對剛接觸正則表達式的讀者請參考有關資料,在此因篇幅有限不作介紹。
JAVA對正則表達式的支持:
在JDK1.3或之前的JDK版本中并沒有包含正則表達式庫可供JAVA程序員使用,之前我們一般都在使用第三方提供的正則表達式庫,這些第三方庫中有源代碼開放的,也有需付費購買的,而現時在JDK1.4的測試版中也已經包含有正則表達式庫---java.util.regex。
故此現在我們有很多面向JAVA的正則表達式庫可供選擇,以下我將介紹兩個較具代表性的 Jakarta-ORO和java.util.regex,首先當然是本人一直在用的 Jakarta-ORO:
Jakarta-ORO正則表達式庫
1.簡介:
Jakarta-ORO是最全面以及優化得最好的正則表達式API之一,Jakarta-ORO庫以前叫做OROMatcher,是由Daniel F. Savarese編寫,后來他將其贈與Jakarta Project,讀者可在Apache.org的網站下載該API包。
許多源代碼開放的正則表達式庫都是支持Perl5兼容的正則表達式語法,Jakarta-ORO正則表達式庫也不例外,他與Perl 5正則表達式完全兼容。
2.對象與其方法:
★PatternCompiler對象:
我們在使用Jakarta-ORO API包時,最先要做的是,創建一個Perl5Compiler類的實例,并把它賦值給PatternCompiler接口對象。Perl5Compiler是PatternCompiler接口的一個實現,允許你把正則表達式編譯成用來匹配的Pattern對象。
PatternCompiler compiler=new Perl5Compiler();
★Pattern對象:
要把所對應的正則表達式編譯成Pattern對象,需要調用compiler對象的compile()方法,并在調用參數中指定正則表達式。舉個例子,你可以按照下面這種方式編譯正則表達式"s[ahkl]y":
Pattern pattern=null;
try {
pattern=compiler.compile("s[ahkl]y ");
} catch (MalformedPatternException e) {
e.printStackTrace();
}在默認的情況下,編譯器會創建一個對大小寫敏感的模式(pattern)。因此,上面代碼編譯得到的模式只匹配"say"、"shy"、 "sky"和"sly",但不匹配"Say"和"skY"。要創建一個大小寫不敏感的模式,你應該在調用編譯器的時候指定一個額外的參數:
pattern=compiler.compile("s[ahkl]y",Perl5Compiler.CASE_INSENSITIVE_MASK);
Pattern對象創建好之后,就可以通過PatternMatcher類用該Pattern對象進行模式匹配。
★PatternMatcher對象:
PatternMatcher對象依據Pattern對象和字符串展開匹配檢查。你要實例化一個Perl5Matcher類并把結果賦值給PatternMatcher接口。Perl5Matcher類是PatternMatcher接口的一個實現,它根據Perl 5正則表達式語法進行模式匹配:
PatternMatcher matcher=new Perl5Matcher();
PatternMatcher對象提供了多個方法進行匹配操作,這些方法的第一個參數都是需要根據正則表達式進行匹配的字符串:
1、boolean matches(String input, Pattern pattern):當要求輸入的字符串input和正則表達式pattern精確匹配時使用該方法。也就是說當正則表達式完整地描述輸入字符串時返回真值。
2、boolean matchesPrefix(String input, Pattern pattern):要求正則表達式匹配輸入字符串起始部分時使用該方法。也就是說當輸入字符串的起始部分與正則表達式匹配時返回真值。
3、boolean contains(String input, Pattern pattern):當正則表達式要匹配輸入字符串的一部分時使用該方法。當正則表達式為輸入字符串的子串時返回真值。
但以上三種方法只會查找輸入字符串中匹配正則表達式的第一個對象,如果當字符串可能有多個子串匹配給定的正則表達式時,那么你就可以在調用上面三個方法時用PatternMatcherInput對象作為參數替代String對象,這樣就可以從字符串中最后一次匹配的位置開始繼續進行匹配,這樣就方便的多了。
用PatternMatcherInput對象作為參數替代String時,上述三個方法的語法如下:
boolean matches(PatternMatcherInput input, Pattern pattern)
boolean matchesPrefix(PatternMatcherInput input, Pattern pattern)
boolean contains(PatternMatcherInput input, Pattern pattern)
★Util.substitute()方法:
查找后需要要進行替換,我們就要用到Util.substitute()方法,其語法如下:
public static String substitute(PatternMatcher matcher,
Pattern pattern,Substitution sub,String input,
int numSubs)
前兩個參數分別為PatternMatcher和Pattern對象。而第三個參數是個Substiution對象,由它來決定替換操作如何進行。第四個參數是要進行替換操作的目標字符串,最后一個參數用來指定是否替換模式的所有匹配子串(Util.SUBSTITUTE_ALL),或只進行指定次數的替換。
在這里我相信有必要詳細解說一下第三個參數Substiution對象,因為它將決定替換將怎樣進行。
Substiution:
Substiution是一個接口類,它為你提供了在使用Util.substitute()方法時控制替換方式的手段,它有兩個標準的實現類:StringSubstitution與Perl5Substitution。當然,同時你也可以生成自己的實現類來定制你所需要的特殊替換動作。
StringSubstitution:
StringSubstitution 實現的是簡單的純文字替換手段,它有兩個構造方法:
StringSubstitution()->缺省的構造方法,初始化一個包含零長度字符串的替換對象。
StringSubstitution(java.lang.String substitution)->初始化一個給定字符串的替換對象。
Perl5Substitution:
Perl5Substitution 是StringSubstitution的子類,它在實現純文字替換手段的同時也允許進行針對MATH類里各匹配組的PERL5變量的替換,所以他的替換手段比其直接父類StringSubstitution更為多元化。
它有三個構造器:
Perl5Substitution()
Perl5Substitution(java.lang.String substitution)
Perl5Substitution(java.lang.String substitution, int numInterpolations)
前兩種構造方法與StringSubstitution一樣,而第三種構造方法下面將會介紹到。
在Perl5Substitution的替換字符串中可以包含用來替代在正則表達式里由小擴號圍起來的匹配組的變量,這些變量是由$1, $2,$3等形式來標識。我們可以用一個例子來解釋怎樣使用替換變量來進行替換:
假設我們有正則表達式模式為b/d+:(也就是b[0-9]+:),而我們想把所有匹配的字符串中的"b"都改為"a",而":"則改為"-",而其余部分則不作修改,如我們輸入字符串為"EXAMPLE b123:",經過替換后就應該變成"EXAMPLE a123-"。要做到這點,我們就首先要把不做替換的部分用分組符號小括號包起來,這樣正則表達式就變為"b(/d+):",而構造Perl5Substitution對象時其替換字符串就應該是"a$1-",也就是構造式為Perl5Substitution("a$1-"),表示在使用Util.substitute()方法時只要在目標字符串里找到和正則表達式" b(/d+): "相匹配的子串都用替換字符串來替換,而變量$1表示如果和正則表達式里第一個組相匹配的內容則照般原文插到$1所在的為置,如在"EXAMPLE b123:"中和正則表達式相匹配的部分是"b123:",而其中和第一分組"(/d+)"相匹配的部分則是"123",所以最后替換結果為"EXAMPLE a123-"。
有一點需要清楚的是,如果你把構造器Perl5Substitution(java.lang.String substitution,int numInterpolations)
中的numInterpolations參數設為INTERPOLATE_ALL,那么當每次找到一個匹配字串時,替換變量($1,$2等)所指向的內容都根據目前匹配字串來更新,但是如果numInterpolations參數設為一個正整數N時,那么在替換時就只會在前N次匹配發生時替換變量會跟隨匹配對象來調整所代表的內容,但N次之后就以一致以第N次替換變量所代表內容來做為以后替換結果。
舉個例子會更好理解:
假如沿用以上例子中的正則表達式模式以及替換內容來進行替換工作,設目標字符串為"Tank b123: 85 Tank b256: 32 Tank b78: 22",并且設numInterpolations參數為INTERPOLATE_ALL,而Util.substitute()方法中的numSub變量設為SUBSTITUTE_ALL(請參考上文Util.substitute()方法內容),那么你獲得的替換結果將會是:
Tank a123- 85 Tank a256- 32 Tank a78- 22
但是如果你把numInterpolations設為2,并且numSubs依然設為SUBSTITUTE_ALL,那么這時你獲得的結果則會是:
Tank a123- 85 Tank a256- 32 Tank a256- 22
你要注意到最后一個替換所用變量$1所代表的內容與第二個$1一樣為"256",而不是預期的"78",因為在替換進行中,替換變量$1只根據匹配內容進行了兩次更新,最后一次就使第二次匹配時所更新的結果,那么我們可以由此知道,如果numInterpolations設為1,那么結果將是:
Tank a123- 85 Tank a123- 32 Tank a123- 22
3.應用示例:
剛好前段時間公司準備出一個《伊索預言》的英語學習互動教材,其中有電子檔資料的整理工作,我們就以此為例來看一下Jakarta-ORO與JDBC2.0 API結合起來對數據庫內的資料進行簡單提取與整理的實現。假設由錄入部的同事送過來的存放在MS SQLSERVER 7數據庫里的電子檔的表結構如下(注:或許在不同的DBMS中有相應的正則表達式的應用,但這不在本文討論范圍內):
表名:AESOP, 表中每條記錄包含有三列:
ID(int):單詞索引號
WORD(varchar):單詞
CONTENT(varchar):存放單詞的相關解釋與例句等內容
其中CONTENT列中內容的格式如下:
[音標] [詞性] (解釋){(例句一/例句解釋/例句中該詞的詞性: 單詞在句中的意思) (例句二/例句解釋/例句中該詞的詞性: 單詞在句中的意思)}
如對應單詞Kevin,CONTENT中的內容如下:
['kevin] [名詞](人名凱文){(Kevin loves comic./凱文愛漫畫/名詞: 凱文)( Kevin is living in ZhuHai now./凱文現住在珠海/名詞: 凱文)}
我們的例子主要針對CONTENT列中內容進行字符串處理。
★查找單個匹配:
首先,讓我們嘗試把CONTNET列中的[音標]字段的內容列示出來,由于所有單詞的記錄中都有這一項并且都在字串開始位置,所以這個查找工作比較簡單:
1、確定相應的正則表達式:/[[^]]+/]
這個是很簡單的正則表達式,其意思是要求相匹配的字符串必須為以一對中括號包含的所有內容,如['kevin] 、[名詞]等,但內容中不包括"]"符號,也就是要避免出現"[][]"會作為一個匹配對象的情況出現(有關正則表達式的基礎知識請參照有關資料,這里不再詳述)。
注意,在Java中,你必須對每一個向前的斜杠("/")進行轉義處理。所以我們要在上面的正則表達式里每個"/"前面加上一個"/"以免出現編譯錯誤,也就是在JAVA中初始化正則表達式的字符串的語句應該為:
String restring=" //[[^]]+//]";
并且在表達式里每個符號中間不能有空格,否則就會同樣出現編譯錯誤。
2、實例化PatternCompiler對象,創建Pattern對象
PatternCompiler compiler=new Perl5Compiler();
Pattern pattern=compiler.compile(restring);
3、創建PatternMatcher對象,調用PatternMatcher接口的contain()方法檢查匹配情況:
PatternMatcher matcher=new Perl5Matcher();
if (matcher.contains(content,pattern)) {
//處理代碼片段
}這里matcher.contains(content,pattern)中的參數 content是從數據庫里取來的字符串變量。該方法只會查到第一個匹配的對象字符串,但是由于音標項均在CONETNET內容字符串中的起始位置,所以用這個方法就已經可以保證把每條記錄里的音標項找出來了,但更為直接與合理的辦法是使用boolean matchesPrefix(PatternMatcherInput input, Pattern pattern)方法,該方法驗證目標字符串是否以正則表達式所匹配的字串為起始。
具體實現的完整的程序代碼如下:
package RegularExpressions;
//import……
import org.apache.oro.text.regex.*;
//使用Jakarta-ORO正則表達式庫前需要把它加到CLASSPATH里面,如果用IDE是//JBUILDER,那么也可以在JBUILDER里直接自建新庫。
public class yisuo {
public static void main(String[] args) {
try {
//使用JDBC DRIVER進行DBMS連接,這里我使用的是一個第三方JDBC
//DRIVER,Microsoft本身也有一個面向SQLSERVER7/2000的免費JDBC //DRIVER,但其性能真的是奇差,不用也罷。
Class.forName("com.jnetdirect.jsql.JSQLDriver");
Connection con = DriverManager.getConnection("jdbc:JSQLConnect://kevin:1433",
"kevin chen", "re");
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,
ResultSet.CONCUR_UPDATABLE);
//為使用Jakarta-ORO庫而創建相應的對象
String rsstring = " //[[^]]+//]";
PatternCompiler orocom = new Perl5Compiler();
Pattern pattern = orocom.compile(rsstring);
PatternMatcher matcher = new Perl5Matcher();
ResultSet uprs = stmt.executeQuery("SELECT * FROM aesop");
while (uprs.next()) {
Stirng word = uprs.getString("word");
Stirng content = uprs.getString("content");
if (matcher.contains(content, pattern)) {
//或if(matcher.matchesPrefix(content,pattern)){
MatchResult result = matcher.getMatch();
Stirng pure = result.toString();
System.out.println(word + "的音標為:" + pure);
}
}
} catch (Exception e) {
System.out.println(e);
}
}
}輸出結果為:kevin的音標為['kevin]
在這個處理中我是用toString()方法來取得結果,但是如果正則表達式里是用了分組符號(圓括號),那么就可以用group(int gid)的方法來取得相應各組匹配的結果,如正則表達式改為" (/[[^]]+/])",那么就可以用以下方法來取得結果:pure=result.group(0);
用程序驗證,輸出結果同樣為:kevin的音標為['kevin]
而如果正則表達式為(/[[^]]+/])(/[[^]]+/]),則會查找到兩個連續的方括號所包含的內容,也就找到[音標] [詞性]兩項,但是兩項的結果分別在兩個組里面,分別由下面語句獲得結果:
result.group(0)->返回[音標] [詞性]兩項內容,也就是與整個正則表達式相匹配的結果字符串,在這里也就為['kevin] [名詞]
result.group(1) ->返回[音標]項內容,結果應是['kevin]
result.group(2) ->返回[詞性]項內容,結果應是[名詞]
繼續用程序驗證,發現輸出并不正確,主要是當內容有中文時就不能成功匹配,考慮到可能是Jakarta-ORO正則表達式庫版本不支持中文的問題,回看一下原來我一直用的還是2.0.1的老版本,馬上到Jakarta.org上下載最新的2.0.4版本裝上再用程序驗證,得出的結果就和預期一樣正確。
★查找多個匹配:
經過第一步的嘗試使用Jakarta-ORO后,我們已經知道了如何正確使用該API包來查找目標字符串里一個匹配的子串,下面我們接著來看一看當目標字符串里包含不止一個匹配的子串時我們如何把它們一個接一個找出來進行相應的處理。
首先我們先試個簡單的應用,假設我們想把CONTNET字段內容里所有用方括號包起來的字串都找出來,很清楚地,CONTNET字段的內容里面就只有兩項匹配的內容:[音標]和 [詞性],剛才我們其實已經把它們分別找出來了,但是我們所用的方法是分組方法,把"[音標] [詞性]"作為一整個正則表達式匹配的內容先找到,再根據分組把[音標]和 [詞性]分別挑出來。但是現在我們需要做的是把[音標]和[詞性]分別做為與同一個正則表達式匹配的內容,先找到一個接著再找下一個,也就是剛才我們的表達式為(/[[^]]+/])(/[[^]]+/]),而現在應為" /[[^]]+/] "。
我們已經知道在匹配操作的三個方法里只要用PatternMatcherInput對象作為參數替代String對象就可以從字符串中最后一次匹配的位置開始繼續進行匹配,實現的程序片段如下:
PatternMatcherInput input=new PatternMatcherInput(content);
while (matcher.contains(input,pattern)) {
result=matcher.getMatch();
System.out.println(result.group(0))
}輸出結果為:['kevin]
[名詞]
接著我們來做復雜一點的處理,就是我們要先把下面內容:
['kevin] [名詞](人名凱文){(Kevin loves comic./凱文愛漫畫/名詞: 凱文)( Kevin is living in ZhuHai now. /凱文現住在珠海/名詞: 凱文)}中的整個例句部分(也就是由大括號所包含的部分)找出來,再分別把例句一和例句二找出,而各例句中的各項內容(英文句、中文句、詞性、解釋)也要分項列出。
第一步當然是要定出相應的正則表達式,需要有兩個,一是和整個例句部分(也就是由大括號包起來的部分)匹配的正則表達式:"/{.+/}",
另一個則要和每個例句部分匹配(也就是小括號中的內容),:/(([^)]+/)
而且由于要把例句的各項分離出來,所以要再把里面的各部分用分組的方法匹配出來:" ([^(]+)/(.+)/(.+):([^)]+) "。
為了簡便起見,我們不再和從數據庫里讀出,而是構造一個包含同樣內容的字符串變量,程序片段如下:
try{
String content="['kevin] [名詞](人名凱文){(Kevin loves comic./凱文愛漫畫/名詞:凱文) (Kevin is living in ZhuHai now./凱文現住在珠海/名詞: 凱文)}";
String ps1="//{.+//}";
String ps2="//([^)]+//)";
String ps3="([^(]+)/(.+)/(.+):([^)]+)";
String sentence;
PatternCompiler orocom=new Perl5Compiler();
Pattern pattern1=orocom.compile(ps1);
Pattern pattern2=orocom.compile(ps2);
Pattern pattern3=orocom.compile(ps3);
PatternMatcher matcher=new Perl5Matcher();
//先找出整個例句部分
if (matcher.contains(content,pattern1)) {
MatchResult result=matcher.getMatch();
String example=result.toString();
PatternMatcherInput input=new PatternMatcherInput(example);
//分別找出例句一和例句二
while (matcher.contains(input,pattern2)){
result=matcher.getMatch();
sentence=result.toString();
//把每個例句里的各項用分組的辦法分隔出來
if (matcher.contains(sentence,pattern3)){
result=matcher.getMatch();
System.out.println("英文句: "+result.group(1));
System.out.println("句子中文翻譯: "+result.group(2));
System.out.println("詞性: "+result.group(3));
System.out.println("意思: "+result.group(4));
}
}
}
}
catch(Exception e) {
System.out.println(e);
}輸出結果為:
英文句: Kevin loves comic.
句子中文翻譯: 凱文愛漫畫
詞性: 名詞
意思: 凱文
英文句: Kevin is living in ZhuHai now.
句子中文翻譯: 凱文現住在珠海
詞性: 名詞
意思: 凱文
★查找替換:
以上的兩個應用都是單純在查找字符串匹配方面的,我們再來看一下查找后如何對目標字符串進行替換。
例如我現在想把第二個例句進行改動,換為:Kevin has seen《LEON》seveal times,because it is a good film./ 凱文已經看過《這個殺手不太冷》幾次了,因為它是一部好電影。/名詞:凱文。
也就是把
['kevin] [名詞](人名凱文){(Kevin loves comic./凱文愛漫畫/名詞: 凱文)( Kevin is living in ZhuHai now. /凱文現住在珠海/名詞: 凱文)}
改為:
['kevin] [名詞](人名凱文){(Kevin loves comic./凱文愛漫畫/名詞: 凱文)( Kevin has seen《LEON》seveal times,because it is a good film./ 凱文已經看過《這個殺手不太冷》幾次了,因為它是一部好電影。/名詞:凱文。)}
之前,我們已經了解Util.substitute()方法與Substiution接口,以及Substiution的兩個實現類StringSubstitution和Perl5Substitution,我們就來看看怎么用Util.substitute()方法配合Perl5Substitution來完成我們上面提出的替換要求,確定正則表達式:
我們要先找到其中的整個例句部分,也就是由大括號包起來的字串,并且把兩個例句分別分組,所以正則表達式為:"/{(/([^)]+/))(/([^)]+/))/}",如果用替換變量來代替分組,那么上面的表達式可以看為"/{$1$2/}",這樣就可以更容易看出替換變量與分組間的關系。
根據上面的正則表達式Perl5Substitution類可以這樣構造:
Perl5Substitution("{$1( Kevin has seen《LEON》seveal times,because it is a good film./ 凱文已經看過《這個殺手不太冷》幾次了,因為它是一部好電影。/名詞:凱文。)}")
再根據這個Perl5Substitution對象來使用Util.substitute()方法便可以完成替換了,實現的代碼片段如下:
try{
String content="['kevin] [名詞](人名凱文){(Kevin loves comic./凱文愛漫畫/名詞: 凱文)(Kevin lives in ZhuHai now./凱文現住在珠海/名詞: 凱文)}";
String ps1="//{(//([^)]+//))(//([^)]+//))//}";
String sentence;
String pure;
PatternCompiler orocom=new Perl5Compiler();
Pattern pattern1=orocom.compile(ps1);
PatternMatcher matcher=new Perl5Matcher();
String result=Util.substitute(matcher,
pattern1,new Perl5Substitution(
"{$1( Kevin has seen《LEON》seveal times,because it is a good film./ 凱文已經看過《這個殺手不太冷》幾次了,因為它是一部好電影。/名詞:凱文。)}",1),
content,Util.SUBSTITUTE_ALL);
System.out.println(result);
}
catch(Exception e) {
System.out.println(e);
}輸出結果是正確的,為:
['kevin] [名詞](人名凱文){(Kevin loves comic./凱文愛漫畫/名詞: 凱文)( Kevin has seen《LEON》seveal times,because it is a good film./ 凱文已經看過《這個殺手不太冷》幾次了,因為它是一部好電影。/名詞:凱文。)}
至于有關使用numInterpolations參數的構造器用法,讀者只要根據上面的介紹自己動手試一下就會清楚了,在此就不再例述。
總結:
本文首先介紹了Jakarta-ORO正則表達式庫的對象與方法,并且接著舉例讓讀者對實際應用有進一步的了解,雖然例子都比較簡單,但希望讀者們在看了該文后對Jakarta-ORO正則表達式庫有一定的認知,在實際工作中有所幫助與啟發。
其實在Jakarta org里除了Jakarta-ORO外還有一個百分百的純JAVA正則表達式庫,就是由Jonathan Locke贈與Jakarta ORG的Regexp,在該包里面包含了完整的文檔以及一個用于調試的Applet例子,對其有興趣的讀者可以到此下載。
參考資料:
本文的主要參考文章,該文在介紹Jakarta-ORO的同時也為讀者詳盡解析了正則表達式的基本語法。
一個基于PERL的正則表達式詳盡教程(雖然該教程是基于PERL的,但是你并不需要有PERL的經驗,雖然那會有所幫助),以及一個不錯的正則表達式簡例教程。
最不可缺少的當然是Jakarta-ORO的幫助文檔http://jakarta.apache.org/oro/api/
關于作者
陳廣佳 Kevin Chen,汕頭大學電子信息工程系工科學士,臺灣大新出版社珠海區開發部,現正圍繞中日韓電子資料使用JAVA開發電子詞典等相關項目。可通過E-mail:cgjmail@163.net于他聯系。
java.util.regex篇
現在JDK1.4里終于有了自己的正則表達式API包,JAVA程序員可以免去找第三方提供的正則表達式庫的周折了,我們現在就馬上來了解一下這個SUN提供的遲來恩物- -對我來說確實如此。
1.簡介:
java.util.regex是一個用正則表達式所訂制的模式來對字符串進行匹配工作的類庫包。
它包括兩個類:Pattern和Matcher
| Pattern | 一個Pattern是一個正則表達式經編譯后的表現模式。 |
| Matcher | 一個Matcher對象是一個狀態機器,它依據Pattern對象做為匹配模式對字符串展開匹配檢查。 |
首先一個Pattern實例訂制了一個所用語法與PERL的類似的正則表達式經編譯后的模式,然后一個Matcher實例在這個給定的Pattern實例的模式控制下進行字符串的匹配工作。
以下我們就分別來看看這兩個類:
2.Pattern類:
Pattern的方法如下:
| static Pattern | compile(String regex) 將給定的正則表達式編譯并賦予給Pattern類 |
| static Pattern | compile(String regex, int flags) 同上,但增加flag參數的指定,可選的flag參數包括:CASE INSENSITIVE,MULTILINE,DOTALL,UNICODE CASE, CANON EQ |
| int | flags() 返回當前Pattern的匹配flag參數. |
| Matcher | matcher(CharSequence input) 生成一個給定命名的Matcher對象 |
| static boolean | matches(String regex, CharSequence input) 編譯給定的正則表達式并且對輸入的字串以該正則表達式為模開展匹配,該方法適合于該正則表達式只會使用一次的情況,也就是只進行一次匹配工作,因為這種情況下并不需要生成一個Matcher實例。 |
| String | pattern() 返回該Patter對象所編譯的正則表達式。 |
| String[] | split(CharSequence input) 將目標字符串按照Pattern里所包含的正則表達式為模進行分割。 |
| String[] | split(CharSequence input, int limit) 作用同上,增加參數limit目的在于要指定分割的段數,如將limi設為2,那么目標字符串將根據正則表達式分為割為兩段。 |
一個正則表達式,也就是一串有特定意義的字符,必須首先要編譯成為一個Pattern類的實例,這個Pattern對象將會使用 matcher()方法來生成一個Matcher實例,接著便可以使用該 Matcher實例以編譯的正則表達式為基礎對目標字符串進行匹配工作,多個Matcher是可以共用一個Pattern對象的。
現在我們先來看一個簡單的例子,再通過分析它來了解怎樣生成一個Pattern對象并且編譯一個正則表達式,最后根據這個正則表達式將目標字符串進行分割:
import java.util.regex.*;
public class Replacement{
public static void main(String[] args) throws Exception {
// 生成一個Pattern,同時編譯一個正則表達式
Pattern p = Pattern.compile("[/]+");
//用Pattern的split()方法把字符串按"/"分割
String[] result = p.split(
"Kevin has seen《LEON》seveal times,because it is a good film."
+"/ 凱文已經看過《這個殺手不太冷》幾次了,因為它是一部"
+"好電影。/名詞:凱文。");
for (int i=0; i<result.length; i++)
System.out.println(result[i]);
}
}輸出結果為:
Kevin has seen《LEON》seveal times,because it is a good film.
凱文已經看過《這個殺手不太冷》幾次了,因為它是一部好電影。
名詞:凱文。
很明顯,該程序將字符串按"/"進行了分段,我們以下再使用 split(CharSequence input, int limit)方法來指定分段的段數,程序改動為:
tring[] result = p.split("Kevin has seen《LEON》seveal times,because it is a good film./ 凱文已經看過《這個殺手不太冷》幾次了,因為它是一部好電影。/名詞:凱文。",2);
這里面的參數"2"表明將目標語句分為兩段。
輸出結果則為:
Kevin has seen《LEON》seveal times,because it is a good film.
凱文已經看過《這個殺手不太冷》幾次了,因為它是一部好電影。/名詞:凱文。
由上面的例子,我們可以比較出java.util.regex包在構造Pattern對象以及編譯指定的正則表達式的實現手法與我們在上一篇中所介紹的Jakarta-ORO 包在完成同樣工作時的差別,Jakarta-ORO 包要先構造一個PatternCompiler類對象接著生成一個Pattern對象,再將正則表達式用該PatternCompiler類的compile()方法來將所需的正則表達式編譯賦予Pattern類:
PatternCompiler orocom=new Perl5Compiler();
Pattern pattern=orocom.compile("REGULAR EXPRESSIONS");
PatternMatcher matcher=new Perl5Matcher();
但是在java.util.regex包里,我們僅需生成一個Pattern類,直接使用它的compile()方法就可以達到同樣的效果:
Pattern p = Pattern.compile("[/]+");
因此似乎java.util.regex的構造法比Jakarta-ORO更為簡潔并容易理解。
3.Matcher類:
Matcher方法如下:
| Matcher | appendReplacement(StringBuffer sb, String replacement) 將當前匹配子串替換為指定字符串,并且將替換后的子串以及其之前到上次匹配子串之后的字符串段添加到一個StringBuffer對象里。 |
| StringBuffer | appendTail(StringBuffer sb) 將最后一次匹配工作后剩余的字符串添加到一個StringBuffer對象里。 |
| int | end() 返回當前匹配的子串的最后一個字符在原目標字符串中的索引位置 。 |
| int | end(int group) 返回與匹配模式里指定的組相匹配的子串最后一個字符的位置。 |
| boolean | find() 嘗試在目標字符串里查找下一個匹配子串。 |
| boolean | find(int start) 重設Matcher對象,并且嘗試在目標字符串里從指定的位置開始查找下一個匹配的子串。 |
| String | group() 返回當前查找而獲得的與組匹配的所有子串內容 |
| String | group(int group) 返回當前查找而獲得的與指定的組匹配的子串內容 |
| int | groupCount() 返回當前查找所獲得的匹配組的數量。 |
| boolean | lookingAt() 檢測目標字符串是否以匹配的子串起始。 |
| boolean | matches() 嘗試對整個目標字符展開匹配檢測,也就是只有整個目標字符串完全匹配時才返回真值。 |
| Pattern | pattern() 返回該Matcher對象的現有匹配模式,也就是對應的Pattern 對象。 |
| String | replaceAll(String replacement) 將目標字符串里與既有模式相匹配的子串全部替換為指定的字符串。 |
| String | replaceFirst(String replacement) 將目標字符串里第一個與既有模式相匹配的子串替換為指定的字符串。 |
| Matcher | reset() 重設該Matcher對象。 |
| Matcher | reset(CharSequence input) 重設該Matcher對象并且指定一個新的目標字符串。 |
| int | start() 返回當前查找所獲子串的開始字符在原目標字符串中的位置。 |
| int | start(int group) 返回當前查找所獲得的和指定組匹配的子串的第一個字符在原目標字符串中的位置。 |
(光看方法的解釋是不是很不好理解?不要急,待會結合例子就比較容易明白了)
一個Matcher實例是被用來對目標字符串進行基于既有模式(也就是一個給定的Pattern所編譯的正則表達式)進行匹配查找的,所有往Matcher的輸入都是通過CharSequence接口提供的,這樣做的目的在于可以支持對從多元化的數據源所提供的數據進行匹配工作。
我們分別來看看各方法的使用:
★matches()/lookingAt ()/find():
一個Matcher對象是由一個Pattern對象調用其matcher()方法而生成的,一旦該Matcher對象生成,它就可以進行三種不同的匹配查找操作:
matches()方法嘗試對整個目標字符展開匹配檢測,也就是只有整個目標字符串完全匹配時才返回真值。
lookingAt ()方法將檢測目標字符串是否以匹配的子串起始。
find()方法嘗試在目標字符串里查找下一個匹配子串。
以上三個方法都將返回一個布爾值來表明成功與否。
★replaceAll ()/appendReplacement()/appendTail():
Matcher類同時提供了四個將匹配子串替換成指定字符串的方法:
replaceAll()
replaceFirst()
appendReplacement()
appendTail()
replaceAll()與replaceFirst()的用法都比較簡單,請看上面方法的解釋。我們主要重點了解一下appendReplacement()和appendTail()方法。
appendReplacement(StringBuffer sb, String replacement) 將當前匹配子串替換為指定字符串,并且將替換后的子串以及其之前到上次匹配子串之后的字符串段添加到一個StringBuffer對象里,而appendTail(StringBuffer sb) 方法則將最后一次匹配工作后剩余的字符串添加到一個StringBuffer對象里。
例如,有字符串fatcatfatcatfat,假設既有正則表達式模式為"cat",第一次匹配后調用appendReplacement(sb,"dog"),那么這時StringBuffer sb的內容為fatdog,也就是fatcat中的cat被替換為dog并且與匹配子串前的內容加到sb里,而第二次匹配后調用appendReplacement(sb,"dog"),那么sb的內容就變為fatdogfatdog,如果最后再調用一次appendTail(sb),那么sb最終的內容將是fatdogfatdogfat。
還是有點模糊?那么我們來看個簡單的程序:
//該例將把句子里的"Kelvin"改為"Kevin"
import java.util.regex.*;
public class MatcherTest{
public static void main(String[] args)
throws Exception {
//生成Pattern對象并且編譯一個簡單的正則表達式"Kelvin"
Pattern p = Pattern.compile("Kevin");
//用Pattern類的matcher()方法生成一個Matcher對象
Matcher m = p.matcher("Kelvin Li and Kelvin Chan are both working in Kelvin Chen's KelvinSoftShop company");
StringBuffer sb = new StringBuffer();
int i=0;
//使用find()方法查找第一個匹配的對象
boolean result = m.find();
//使用循環將句子里所有的kelvin找出并替換再將內容加到sb里
while(result) {
i++;
m.appendReplacement(sb, "Kevin");
System.out.println("第"+i+"次匹配后sb的內容是:"+sb);
//繼續查找下一個匹配對象
result = m.find();
}
//最后調用appendTail()方法將最后一次匹配后的剩余字符串加到sb里;
m.appendTail(sb);
System.out.println("調用m.appendTail(sb)后sb的最終內容是:"+ sb.toString());
}
}最終輸出結果為:
第1次匹配后sb的內容是:Kevin
第2次匹配后sb的內容是:Kevin Li and Kevin
第3次匹配后sb的內容是:Kevin Li and Kevin Chan are both working in Kevin
第4次匹配后sb的內容是:Kevin Li and Kevin Chan are both working in Kevin Chen's Kevin
調用m.appendTail(sb)后sb的最終內容是:Kevin Li and Kevin Chan are both working in Kevin Chen's KevinSoftShop company.
看了上面這個例程是否對appendReplacement(),appendTail()兩個方法的使用更清楚呢,如果還是不太肯定最好自己動手寫幾行代碼測試一下。
★group()/group(int group)/groupCount():
該系列方法與我們在上篇介紹的Jakarta-ORO中的MatchResult .group()方法類似(有關Jakarta-ORO請參考上篇的內容),都是要返回與組匹配的子串內容,下面代碼將很好解釋其用法:
import java.util.regex.*;
public class GroupTest{
public static void main(String[] args)
throws Exception {
Pattern p = Pattern.compile("(ca)(t)");
Matcher m = p.matcher("one cat,two cats in the yard");
StringBuffer sb = new StringBuffer();
boolean result = m.find();
System.out.println("該次查找獲得匹配組的數量為:"+m.groupCount());
for(int i=1;i<=m.groupCount();i++){
System.out.println("第"+i+"組的子串內容為: "+m.group(i));
}
}
}輸出為:
該次查找獲得匹配組的數量為:2
第1組的子串內容為:ca
第2組的子串內容為:t
Matcher對象的其他方法因比較好理解且由于篇幅有限,請讀者自己編程驗證。
4.一個檢驗Email地址的小程序:
最后我們來看一個檢驗Email地址的例程,該程序是用來檢驗一個輸入的EMAIL地址里所包含的字符是否合法,雖然這不是一個完整的EMAIL地址檢驗程序,它不能檢驗所有可能出現的情況,但在必要時您可以在其基礎上增加所需功能。
import java.util.regex.*;
public class Email {
public static void main(String[] args) throws Exception {
String input = args[0];
//檢測輸入的EMAIL地址是否以 非法符號"."或"@"作為起始字符
Pattern p = Pattern.compile("^//.|^//@");
Matcher m = p.matcher(input);
if (m.find()){
System.err.println("EMAIL地址不能以'.'或'@'作為起始字符");
}
//檢測是否以"www."為起始
p = Pattern.compile("^www//.");
m = p.matcher(input);
if (m.find()) {
System.out.println("EMAIL地址不能以'www.'起始");
}
//檢測是否包含非法字符
p = Pattern.compile("[^A-Za-z0-9//.//@_//-~#]+");
m = p.matcher(input);
StringBuffer sb = new StringBuffer();
boolean result = m.find();
boolean deletedIllegalChars = false;
while(result) {
//如果找到了非法字符那么就設下標記
deletedIllegalChars = true;
//如果里面包含非法字符如冒號雙引號等,那么就把他們消去,加到SB里面
m.appendReplacement(sb, "");
result = m.find();
}
m.appendTail(sb);
input = sb.toString();
if (deletedIllegalChars) {
System.out.println("輸入的EMAIL地址里包含有冒號、逗號等非法字符,請修改");
System.out.println("您現在的輸入為: "+args[0]);
System.out.println("修改后合法的地址應類似: "+input);
}
}
}例如,我們在命令行輸入:java Email www.kevin@163.net
那么輸出結果將會是:EMAIL地址不能以'www.'起始
如果輸入的EMAIL為@kevin@163.net
則輸出為:EMAIL地址不能以'.'或'@'作為起始字符
當輸入為:cgjmail#$%@163.net
那么輸出就是:
輸入的EMAIL地址里包含有冒號、逗號等非法字符,請修改
您現在的輸入為: cgjmail#$%@163.net
修改后合法的地址應類似: cgjmail@163.net
感謝你能夠認真閱讀完這篇文章,希望小編分享的“JAVA中正則表達式有什么用”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





