溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關python爬蟲之使用user-agent的注意事項的內容。小編覺得挺實用的,因此分享給大家做個參考。一起跟隨小編過來看看吧。
我們在寫爬蟲,構建網絡請求的時候,不可避免地要添加請求頭( headers ),以 mdn 學習區為例,我們的請求頭是這樣的:
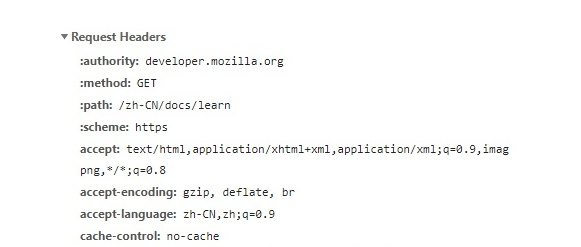
一般來說,我們只要添加 user-agent 就能滿足絕大部分需求了,Python 代碼如下:
import requests
headers = {
#'authority': 'developer.mozilla.org',
#'pragma': 'no-cache',
#'cache-control': 'no-cache',
#'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 YaBrowser/19.7.0.1635 Yowser/2.5 Safari/537.36',
#'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
#'accept-encoding': 'gzip, deflate, br',
#'accept-language': 'zh-CN,zh-TW;q=0.9,zh;q=0.8,en-US;q=0.7,en;q=0.6',
#'cookie': 你的cookie,
}
response = requests.get('https://developer.mozilla.org/zh-CN/docs/learn', headers=headers)
但是有些請求,我們要把特定的 headers 參數添加上才能獲得正確的網絡響應,不知道哪個參數是必要的情況下,就要先把所有參數都添加上,再逐個排除。
但是手動復制粘貼 headers 字典里的每一個鍵值對太費事了。
感謝各位的閱讀!關于python爬蟲之使用user-agent的注意事項就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





