溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了怎么用scrapy框架構建python爬蟲,具有一定借鑒價值,需要的朋友可以參考下。希望大家閱讀完這篇文章后大有收獲。下面讓小編帶著大家一起了解一下。
制作爬蟲,總體來說分為兩步:先爬再取。
也就是說,首先你要獲取整個網頁的所有內容,然后再取出其中對你有用的部分。
要建立一個Spider,你必須用scrapy.spider.BaseSpider創建一個子類,并確定三個強制的屬性:
name:爬蟲的識別名稱,必須是唯一的,在不同的爬蟲中你必須定義不同的名字。
start_urls:爬取的URL列表。爬蟲從這里開始抓取數據,所以,第一次下載的數據將會從這些urls開始。其他子URL將會從這些起始URL中繼承性生成。
parse():解析的方法,調用的時候傳入從每一個URL傳回的Response對象作為唯一參數,負責解析并匹配抓取的數據(解析為item),跟蹤更多的URL。
創建douban_spider.py文件,保存在douban\spiders目錄下。并導入我們需用的模塊
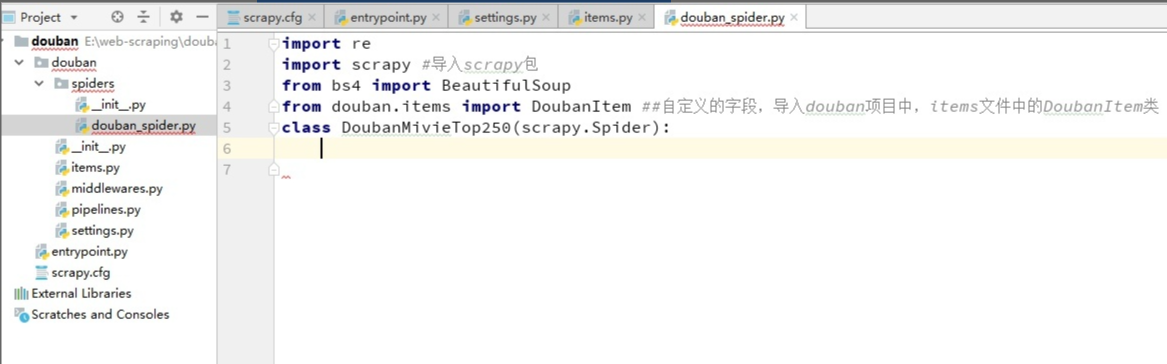
編寫主要模塊:
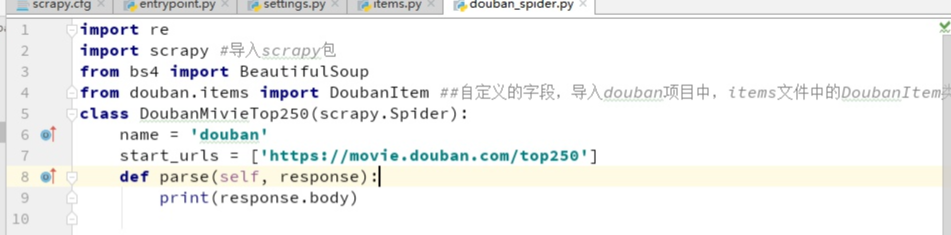
然后運行一下,
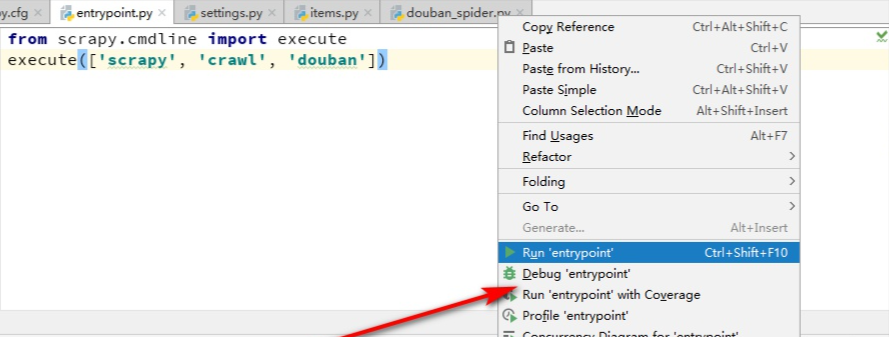
會看到有403錯誤,是因為我們爬取的時候沒加頭部導致的:
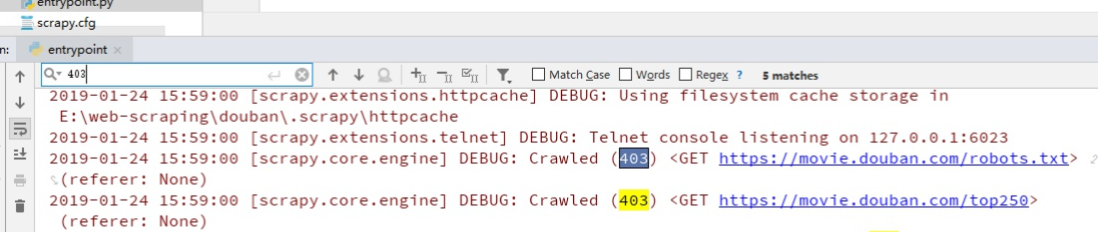
我們來偽裝一下,在settings.py里加上USER_AGENT:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
再次運行,即可看到正確結果。
感謝你能夠認真閱讀完這篇文章,希望小編分享怎么用scrapy框架構建python爬蟲內容對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,遇到問題就找億速云,詳細的解決方法等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





