溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python實現爬取豆瓣數據,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
代碼如下
from bs4 import BeautifulSoup #網頁解析,獲取數據 import sys #正則表達式,進行文字匹配 import re import urllib.request,urllib.error #指定url,獲取網頁數據 import xlwt #使用表格 import sqlite3 import lxml
以上是引用的庫,引用庫的方法很簡單,直接上圖:
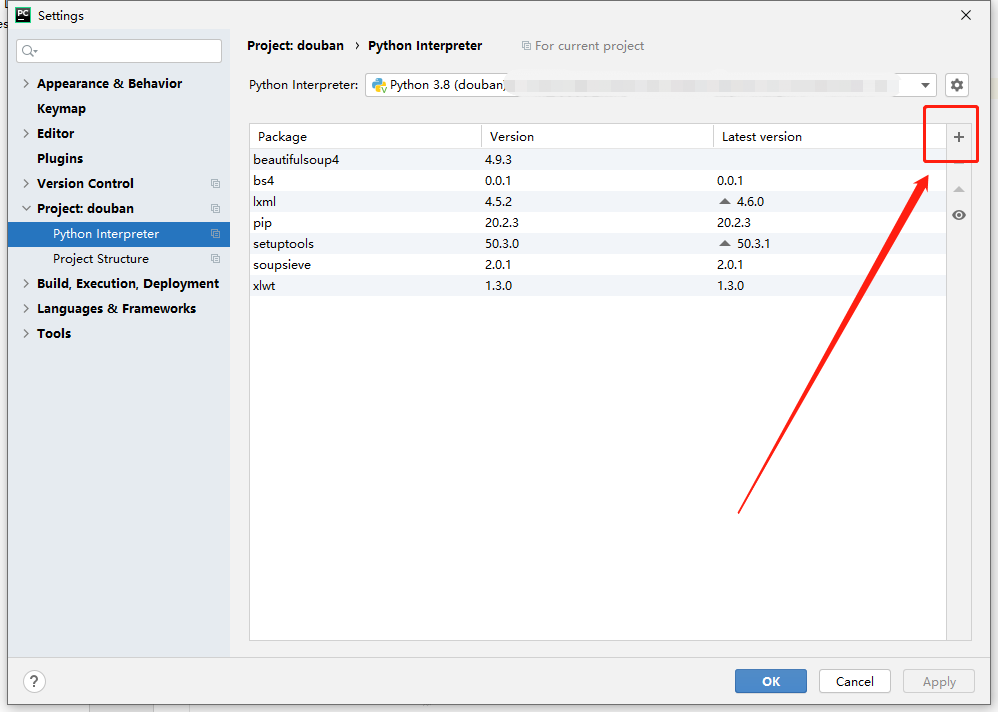
上面第一步算有了,下面分模塊來,步驟算第二步來:
這個放在開頭
def main():
baseurl ="https://movie.douban.com/top250?start="
datalist = getData(baseurl)
savepath=('douban.xls')
saveData(datalist,savepath)這個放在末尾
if __name__ == '__main__':
main()
不難看出這是主函數,里面的話是對子函數的調用,下面是第三個步驟:子函數的代碼
對網頁正則表達提取(放在主函數的后面就可以)
findLink = re.compile(r'<a href="(.*?)" rel="external nofollow" rel="external nofollow" >') #創建正則表達式對象,表示規則(字符串的模式)
#影片圖片
findImg = re.compile(r'<img.*src="(.*?)" width="100"/>',re.S)#re.S取消換行符
#影片片面
findtitle= re.compile(r'<span class="title">(.*?)</span>')
#影片評分
fileRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
#找到評價的人數
findJudge = re.compile(r'<span>(\d*)人評價</span>')
#找到概識
findInq =re.compile(r'<span class="inq">(.*?)</span>')
#找到影片的相關內容
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
爬數據核心函數
def getData(baseurl):
datalist=[]
for i in range(0,10):#調用獲取頁面的函數10次
url = baseurl + str(i*25)
html = askURl(url)
#逐一解析
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data=[]
item = str(item)
link = re.findall(findLink,item)[0] #re庫用來通過正則表達式查找指定的字符串
data.append(link)
titles =re.findall(findtitle,item)
if(len(titles)==2):
ctitle=titles[0].replace('\xa0',"")
data.append(ctitle)#添加中文名
otitle = titles[1].replace("\xa0/\xa0Perfume:","")
data.append(otitle)#添加外國名
else:
data.append(titles[0])
data.append(' ')#外國名字留空
imgSrc = re.findall(findImg,item)[0]
data.append(imgSrc)
rating=re.findall(fileRating,item)[0]
data.append(rating)
judgenum = re.findall(findJudge,item)[0]
data.append(judgenum)
inq=re.findall(findInq,item)
if len(inq) != 0:
inq =inq[0].replace(".","")
data.append(inq)
else:
data.append(" ")
bd=re.findall(findBd,item)[0]
bd=re.sub('<br(\s+)?/>(\s+)?'," ",bd) #去掉<br/>
bd =re.sub('\xa0'," ",bd)
data.append(bd.strip()) #去掉前后的空格
datalist.append(data) #把處理好的一部電影信息放入datalist
return datalist獲取指定網頁內容
def askURl(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;WOW64) Apple"
+"WebKit / 537.36(KHTML, likeGecko) Chrome / 78.0.3904.108 Safari / 537.36"
}
#告訴豆瓣我們是瀏覽器我們可以接受什么水平的內容
request = urllib.request.Request(url,headers=head)
html=""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html將爬下來的數據保存到表格中
ef saveData(datalist,savepath):
print("保存中。。。")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 創建workbook對象
sheet = book.add_sheet('douban',cell_overwrite_ok=True) #創建工作表 cell_overwrite_ok表示直接覆蓋
col = ("電影詳情鏈接","影片中文網","影片外國名","圖片鏈接","評分","評價數","概況","相關信息")
for i in range(0,8):
sheet.write(0,i,col[i])
for i in range(0,250):
print("第%d條" %(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath)以上就是整個爬數據的整個程序,這僅僅是一個非常簡單的爬取,如果想要爬更難的網頁需要實時分析
整個程序代碼
from bs4 import BeautifulSoup #網頁解析,獲取數據
import sys #正則表達式,進行文字匹配
import re
import urllib.request,urllib.error #指定url,獲取網頁數據
import xlwt #使用表格
import sqlite3
import lxml
def main():
baseurl ="https://movie.douban.com/top250?start="
datalist = getData(baseurl)
savepath=('douban.xls')
saveData(datalist,savepath)
#影片播放鏈接
findLink = re.compile(r'<a href="(.*?)" rel="external nofollow" rel="external nofollow" >') #創建正則表達式對象,表示規則(字符串的模式)
#影片圖片
findImg = re.compile(r'<img.*src="(.*?)" width="100"/>',re.S)#re.S取消換行符
#影片片面
findtitle= re.compile(r'<span class="title">(.*?)</span>')
#影片評分
fileRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
#找到評價的人數
findJudge = re.compile(r'<span>(\d*)人評價</span>')
#找到概識
findInq =re.compile(r'<span class="inq">(.*?)</span>')
#找到影片的相關內容
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
def getData(baseurl):
datalist=[]
for i in range(0,10):#調用獲取頁面的函數10次
url = baseurl + str(i*25)
html = askURl(url)
#逐一解析
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data=[]
item = str(item)
link = re.findall(findLink,item)[0] #re庫用來通過正則表達式查找指定的字符串
data.append(link)
titles =re.findall(findtitle,item)
if(len(titles)==2):
ctitle=titles[0].replace('\xa0',"")
data.append(ctitle)#添加中文名
otitle = titles[1].replace("\xa0/\xa0Perfume:","")
data.append(otitle)#添加外國名
else:
data.append(titles[0])
data.append(' ')#外國名字留空
imgSrc = re.findall(findImg,item)[0]
data.append(imgSrc)
rating=re.findall(fileRating,item)[0]
data.append(rating)
judgenum = re.findall(findJudge,item)[0]
data.append(judgenum)
inq=re.findall(findInq,item)
if len(inq) != 0:
inq =inq[0].replace(".","")
data.append(inq)
else:
data.append(" ")
bd=re.findall(findBd,item)[0]
bd=re.sub('<br(\s+)?/>(\s+)?'," ",bd) #去掉<br/>
bd =re.sub('\xa0'," ",bd)
data.append(bd.strip()) #去掉前后的空格
datalist.append(data) #把處理好的一部電影信息放入datalist
return datalist
#得到指定一個url的網頁內容
def askURl(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;WOW64) Apple"
+"WebKit / 537.36(KHTML, likeGecko) Chrome / 78.0.3904.108 Safari / 537.36"
}
#告訴豆瓣我們是瀏覽器我們可以接受什么水平的內容
request = urllib.request.Request(url,headers=head)
html=""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
def saveData(datalist,savepath):
print("保存中。。。")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 創建workbook對象
sheet = book.add_sheet('douban',cell_overwrite_ok=True) #創建工作表 cell_overwrite_ok表示直接覆蓋
col = ("電影詳情鏈接","影片中文網","影片外國名","圖片鏈接","評分","評價數","概況","相關信息")
for i in range(0,8):
sheet.write(0,i,col[i])
for i in range(0,250):
print("第%d條" %(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath)
if __name__ == '__main__':
main()關于Python實現爬取豆瓣數據就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





