溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了Python3爬蟲里如何實現識別微博宮格驗證碼,內容簡而易懂,希望大家可以學習一下,學習完之后肯定會有收獲的,下面讓小編帶大家一起來看看吧。
本節我們來介紹一下新浪微博宮格驗證碼的識別,此驗證碼是一種新型交互式驗證碼,每個宮格之間會有一條指示連線,指示了我們應該的滑動軌跡,我們需要按照滑動軌跡依次從起始宮格一直滑動到終止宮格才可以完成驗證,如圖所示:
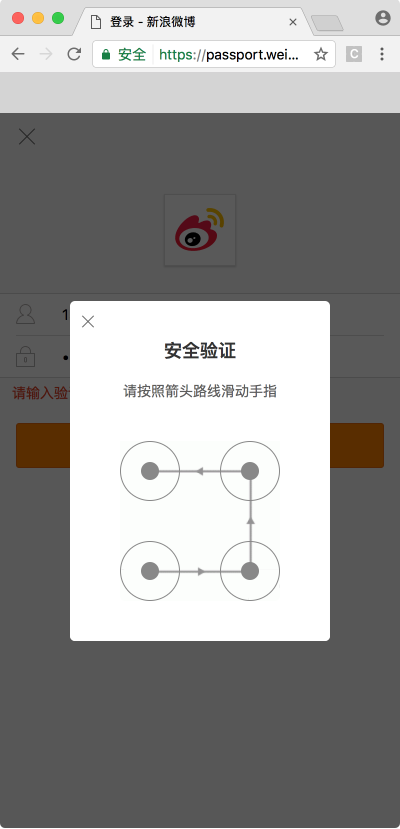
鼠標滑動后的軌跡會以黃色的連線來標識,如圖所示:
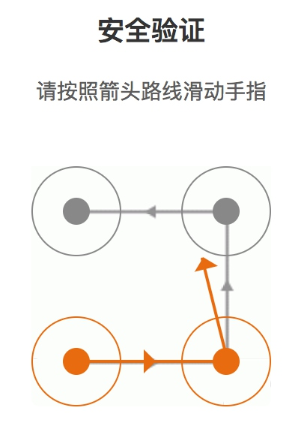
我們可以訪問新浪微博移動版登錄頁面就可以看到如上驗證碼,鏈接為:https://passport.weibo.cn/signin/login,當然也不是每次都會出現驗證碼,一般當頻繁登錄或者賬號存在安全風險的時候會出現。
接下來我們就來試著識別一下此類驗證碼。
1. 本節目標
本節我們的目標是用程序來識別并通過微博宮格驗證碼的驗證。
2. 準備工作
本次我們使用的 Python 庫是 Selenium,使用的瀏覽器為 Chrome,在此之前請確保已經正確安裝好了 Selenium 庫、Chrome瀏覽器并配置好了 ChromeDriver,相關流程可以參考第一章的說明。
3. 識別思路
要識別首先要從探尋規律入手,那么首先我們找到的規律就是此驗證碼的四個宮格一定是有連線經過的,而且每一條連線上都會相應的指示箭頭,連線的形狀多樣,如C型、Z型、X型等等,如圖 8-26、8-27、8-28 所示:
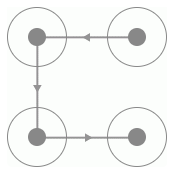
C 型
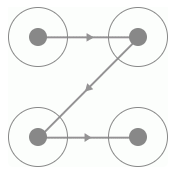
Z 型
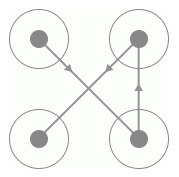
X 型
而同時我們發現同一種類型它的連線軌跡是相同的,唯一不同的就是連線的方向,如圖所示:
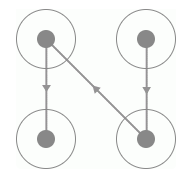
反向連線
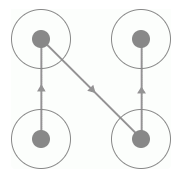
正向連線
這兩種驗證碼的連線軌跡是相同的,但是由于連線上面的指示箭頭不同導致滑動的宮格順序就有所不同。
所以要完全識別滑動宮格順序的話就需要具體識別出箭頭的朝向,而觀察一下整個驗證碼箭頭朝向一共可能有 8 種,而且會出現在不同的位置,如果要寫一個箭頭方向識別算法的話需要都考慮到不同箭頭所在的位置,我們需要找出各個位置的箭頭的像素點坐標,同時識別算法還需要計算其像素點變化規律,這個工作量就變得比較大。
這時我們可以考慮用模板匹配的方法,模板匹配的意思就是將一些識別目標提前保存下來并做好標記,稱作模板,在這里我們就可以獲取驗證碼圖片并做好拖動順序的標記當做模板。在匹配的時候來對比要新識別的目標和每一個模板哪個是匹配的,如果找到匹配的模板,則被匹配到的模板就和新識別的目標是相同的,這樣就成功識別出了要新識別的目標了。模板匹配在圖像識別中也是非常常用的一種方法,實現簡單而且易用性好。
模板匹配方法如果要效果好的話,我們必須要收集到足夠多的模板才可以,而對于微博宮格驗證碼來說,宮格就 4 個,驗證碼的樣式最多就是 4 3 2 * 1 = 24種,所以我們可以直接將所有模板都收集下來。
所以接下來我們需要考慮的就是用何種模板來進行匹配,是只匹配箭頭還是匹配整個驗證碼全圖呢?我們來權衡一下這兩種方式的匹配精度和工作量:
首先是精度問題。如果要匹配箭頭的話,我們比對的目標只有幾個像素點范圍的箭頭,而且我們需要精確知道各個箭頭所在的像素點,一旦像素點有所偏差,那么匹配模板的時候會直接錯位,導致匹配結果大打折扣。如果匹配全圖,我們無需關心箭頭所在位置,同時還有連線幫助輔助匹配,所以匹配精度上顯然是全圖匹配精度更高。
其次是工作量的問題。如果要匹配箭頭的話,我們需要將所有不同朝向的箭頭模板都保存下來,而相同位置箭頭的朝向可能不一,相同朝向的箭頭位置可能不一,這時候我們需要都算出各個箭頭的位置并將其逐個截出來保存成模板,同時在匹配的時候也需要依次去探尋驗證碼對應位置是否有匹配模板。如果匹配全圖的話,我們不需要關心每個箭頭的位置和朝向,只需要將驗證碼全圖保存下來即可,在匹配的時候也不需要再去計算箭頭的位置,所以工作量上明顯是匹配全圖更小。
所以綜上考慮,我們選用全圖匹配的方式來進行識別。
所以到此為止,我們就可以使用全圖模板匹配的方法來識別這個宮格驗證碼了,找到匹配的模板之后,我們就可以得到事先為模板定義的拖動順序,然后模擬拖動即可。
4. 獲取模板
在開始之前,我們需要做一下準備工作,先將 24 張驗證碼全圖保存下來,保存工作難道需要手工來做嗎?當然不是的,因為驗證碼是隨機的,一共有 24 種,所以我們可以寫一段程序來批量保存一些驗證碼圖片,然后從中篩選出需要的圖片就好了,代碼如下:
import time
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
USERNAME = ''
PASSWORD = ''
class CrackWeiboSlide():
def __init__(self):
self.url = 'https://passport.weibo.cn/signin/login'
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 20)
self.username = USERNAME
self.password = PASSWORD
def __del__(self):
self.browser.close()
def open(self):
"""
打開網頁輸入用戶名密碼并點擊
:return: None
"""
self.browser.get(self.url)
username = self.wait.until(EC.presence_of_element_located((By.ID, 'loginName')))
password = self.wait.until(EC.presence_of_element_located((By.ID, 'loginPassword')))
submit = self.wait.until(EC.element_to_be_clickable((By.ID, 'loginAction')))
username.send_keys(self.username)
password.send_keys(self.password)
submit.click()
def get_position(self):
"""
獲取驗證碼位置
:return: 驗證碼位置元組
"""
try:
img = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'patt-shadow')))
except TimeoutException:
print('未出現驗證碼')
self.open()
time.sleep(2)
location = img.location
size = img.size
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x']
+ size['width']
return (top, bottom, left, right)
def get_screenshot(self):
"""
獲取網頁截圖
:return: 截圖對象
"""
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
return screenshot
def get_image(self, name='captcha.png'):
"""
獲取驗證碼圖片
:return: 圖片對象
"""
top, bottom, left, right = self.get_position()
print('驗證碼位置', top, bottom, left, right)
screenshot = self.get_screenshot()
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha
def main(self):
"""
批量獲取驗證碼
:return: 圖片對象
"""
count = 0
while True:
self.open()
self.get_image(str(count) + '.png')
count += 1
if __name__ == '__main__':
crack = CrackWeiboSlide()
crack.main()其中這里需要將 USERNAME 和 PASSWORD 修改為自己微博的用戶名密碼,運行一段時間后便可以發現在本地多了很多以數字命名的驗證碼,如圖所示:

在這里我們只需要挑選出不同的24張驗證碼圖片并命名保存就好了,名稱可以直接取作宮格的滑動的順序,如某張驗證碼圖片如圖所示:
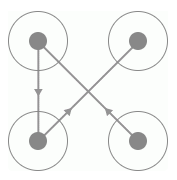
我們將其命名為 4132.png 即可,也就是代表滑動順序為 4-1-3-2,按照這樣的規則,我們將驗證碼整理為如下 24 張圖,如圖 所示:
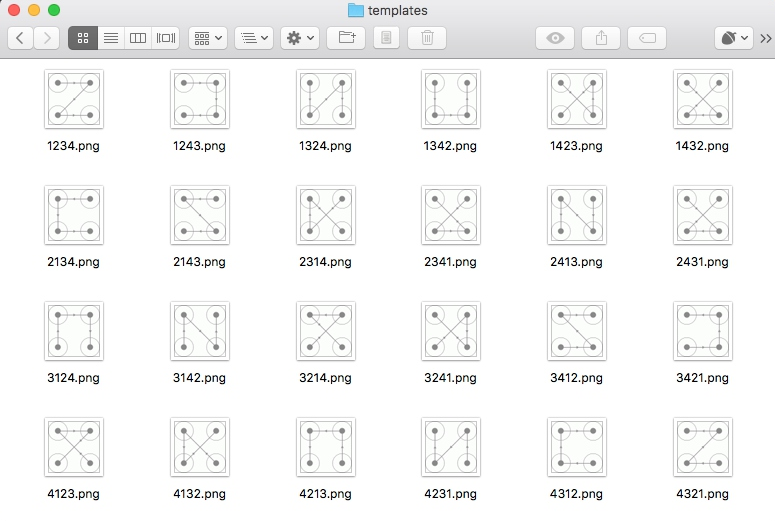
如上的 24 張圖就是我們的模板,接下來我們在識別的時候只需要遍歷模板進行匹配即可。
5. 模板匹配
上面的代碼已經實現了將驗證碼保存下來的功能,通過調用 get_image() 方法我們便可以得到驗證碼圖片對象,得到驗證碼對象之后我們就需要對其進行模板匹配了,定義如下的方法進行匹配:
from os import listdir
def detect_image(self, image):
"""
匹配圖片
:param image: 圖片
:return: 拖動順序
"""
for template_name in listdir(TEMPLATES_FOLDER):
print('正在匹配', template_name)
template = Image.open(TEMPLATES_FOLDER + template_name)
if self.same_image(image, template):
# 返回順序
numbers = [int(number) for number in list(template_name.split('.')[0])]
print('拖動順序', numbers)
return numbers在這里 TEMPLATES_FOLDER 就是模板所在的文件夾,在這里我們用 listdir() 方法將所有模板的文件名稱獲取出來,然后對其進行遍歷,通過 same_image() 方法對驗證碼和模板進行比對,如果成功匹配,那么就將匹配到的模板文件名轉為列表,如匹配到了 3124.png,則返回結果 [3, 1, 2, 4]。
比對的方法實現如下:
def is_pixel_equal(self, image1, image2, x, y):
"""
判斷兩個像素是否相同
:param image1: 圖片1
:param image2: 圖片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
"""
# 取兩個圖片的像素點
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 20
if abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(
pixel1[2] - pixel2[2]) < threshold:
return True
else:
return False
def same_image(self, image, template):
"""
識別相似驗證碼
:param image: 待識別驗證碼
:param template: 模板
:return:
"""
# 相似度閾值
threshold = 0.99
count = 0
for x in range(image.width):
for y in range(image.height):
# 判斷像素是否相同
if self.is_pixel_equal(image, template, x, y):
count += 1
result = float(count) / (image.width * image.height)
if result > threshold:
print('成功匹配')
return True
return False在這里比對圖片也是利用了遍歷像素的方法,same_image() 方法接收兩個參數,image 為待檢測的驗證碼圖片對象,template 是模板對象,由于二者大小是完全一致的,所以在這里我們遍歷了圖片的所有像素點,比對二者同一位置的像素點是否相同,如果相同就計數加 1,最后計算一下相同的像素點占總像素的比例,如果該比例超過一定閾值那就判定為圖片完全相同,匹配成功。在這里設定閾值為 0.99,即如果二者有 0.99 以上的相似比則代表匹配成功。
這樣通過上面的方法,依次匹配 24 個模板,如果驗證碼圖片正常,總能找到一個匹配的模板,這樣最后就可以得到宮格的滑動順序了。
6. 模擬拖動
得到了滑動順序之后,我們接下來就是根據滑動順序來拖動鼠標連接各個宮格了,方法實現如下:
def move(self, numbers):
"""
根據順序拖動
:param numbers:
:return:
"""
# 獲得四個按點
circles = self.browser.find_elements_by_css_selector('.patt-wrap .patt-circ')
dx = dy = 0
for index in range(4):
circle = circles[numbers[index] - 1]
# 如果是第一次循環
if index == 0:
# 點擊第一個按點
ActionChains(self.browser)
.move_to_element_with_offset(circle, circle.size['width'] / 2, circle.size['height'] / 2)
.click_and_hold().perform()
else:
# 小幅移動次數
times = 30
# 拖動
for i in range(times):
ActionChains(self.browser).move_by_offset(dx / times, dy / times).perform()
time.sleep(1 / times)
# 如果是最后一次循環
if index == 3:
# 松開鼠標
ActionChains(self.browser).release().perform()
else:
# 計算下一次偏移
dx = circles[numbers[index + 1] - 1].location['x'] - circle.location['x']
dy = circles[numbers[index + 1] - 1].location['y'] - circle.location['y']在這里方法接收的參數就是宮格的點按順序,如 [3, 1, 2, 4]。首先我們利用 find_elements_by_css_selector() 方法獲取到四個宮格元素,是一個列表形式,每個元素代表一個宮格,接下來我們遍歷了宮格的點按順序,再做一系列對應操作。
其中如果是第一個宮格,那就直接鼠標點擊并保持動作,否則移動到下一個宮格。如果是最后一個宮格,那就松開鼠標,否則計算移動到下一個宮格的偏移量。
通過四次循環,我們便可以成功操作瀏覽器完成宮格驗證碼的拖拽填充,松開鼠標之后即可識別成功。
運行效果如圖所示:
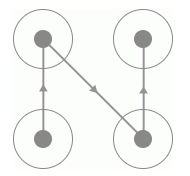
鼠標會慢慢的從起始位置移動到終止位置,最后一個宮格松開之后便完成了驗證碼的識別。
至此,微博宮格驗證碼的識別就全部完成了。
識別完成之后驗證碼窗口會自動關閉,接下來直接點擊登錄按鈕即可完成微博登錄。
以上就是關于Python3爬蟲里如何實現識別微博宮格驗證碼的內容,如果你們有學習到知識或者技能,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





